Содержание

IT-отделы работают с мизерным бюджетом. Поэтому сокращение расходов позволит компании не только оставаться на плаву, но и направить сэкономленные средства на развитие. Чтобы рациональнее использовать имеющийся бюджет, познакомимся с 7 бесплатными программными продуктами для разработки баз данных и решениями DBM с открытым исходным кодом.
CUBRID

Бесплатный вариант с открытым исходным кодом, оптимизированный специально для веб-приложений. Сервис предназначен для обработки больших объемов данных и генерации многочисленных параллельных запросов. Это решение реализовано на языке программирования C.
- Множественная степень дробления блокировок;
- Создание резервных копий онлайн;
- Инструменты GUI и драйверы для JDBC , PHP , Python , Perl и Ruby ;
- Поддержка встроенного сегментирования базы данных для масштабирования;
- В крупных системах данные разделяются по нескольким экземплярам базы данных;
- Репликация полнотекстовых баз данных и согласованность транзакций.
- Не работает в системах Apple ;
- Нет отладчика сценариев;
- Руководство доступно только на английском и корейском языках;
- Обсуждения на официальном форуме , как правило, устаревшие ( большинству из них несколько лет ).
Firebird

Эта реляционная база данных использовалась в производственных системах (под разными названиями) с 1981 года и реализует многие стандарты ANSI SQL . Firebird может работать на Linux , Windows и различных Unix-платформах .
- API трассировки для мониторинга в реальном времени;
- Аутентификация с проверкой подлинности Windows ;
- Четыре поддерживаемые архитектуры: SuperClassic , Classic , SuperServer и Embedded ;
- Разнообразные средства разработки: коммерческие инструменты – FIBPlus и IBObjects ;
- Возможность автоматического развертывания для очистки базы данных;
- Уведомления о событиях из триггеров базы данных и хранимых процедур;
- Бесплатная поддержка глобального сообщества Firebird . Что важно при разработке требований к базам данных.
- Интегрированная поддержка репликации не включена и доступна только в качестве дополнения;
- Нехватка временных таблиц и интеграции с другими системами управления базами данных;
- Аутентификация с проверкой подлинности Windows недостаточна по сравнению с решениями, доступными в других операционных системах.
MariaDB

Созданная разработчиками MySQL , MariaDB используется такими техническими гигантами, как Wikipedia , Facebook и даже Google . MariaDB – это сервер базы данных, который предлагает встраиваемую замену функционала MySQL . Безопасность является главным принципом и приоритетом разработчиков СУБД . В каждом релизе они добавляют все патчи безопасности MySQL и при необходимости улучшают их.
- Масштабируемость с простой интеграцией;
- Доступ в режиме реального времени;
- Основные функции MySQL ( MariaDB является альтернативой MySQL );
- Альтернативные механизмы хранения, оптимизация серверов и патчи;
- Обширная база знаний по разработке баз данных SQL , накопленная в течение 20 лет работы MariaDB .
- Отсутствует плагин проверки сложности пароля;
- Отсутствует memcached интерфейс ( распределённая система кэширования в оперативной памяти );
- Нет трассировки оптимизатора.
MongoDB

MongoDB была основана в 2007 году и известна как « база данных для великих идей ». Проект финансируется такими известными инвесторами, как Fidelity Investments , Goldman Sachs Group , Inc. , и Intel Capital . С момента своего создания MongoDB была скачена 20 миллионов раз и поддерживается более чем 1000 партнерами. Эти партнеры придерживаются принципа бесплатного решения с открытым исходным кодом.
- Проверка документов;
- Зашифрованный механизм хранения.
Популярные варианты использования:
- мобильные приложения;
- каталоги продуктов;
- управление контентом;
- Real-time Приложения с механизмом хранения в памяти ( бета-версия );
- сокращает время между первичным сбоем и восстановлением.
- Не подходит для приложений, требующих сложных транзакций;
- Не подходит для устаревших приложений;
- Молодое решение: программное обеспечение меняется и быстро развивается.
MySQL

Самый именитый представитель нашего обзора программ для разработки базы данных . MySQL существует с 1995 года и теперь принадлежит компании Oracle . СУБД имеет открытый исходный код. Также существует несколько платных версий, которые предлагают дополнительные функции, такие как гео-репликация кластера и автоматическое масштабирование.
Поскольку MySQL является отраслевым стандартом, она совместима практически со всеми операционными системами и написана на языках C и C ++ . Это решение является отличным вариантом для международных пользователей. Сервер СУБД может выводить клиентам сообщения об ошибках на нескольких языках.
- Проверка на стороне сервера;
- Возможность локального использования;
- Гибкая система привилегий и паролей;
- Безопасное шифрование всего трафика паролей;
- Библиотека, которая может быть встроена в автономные приложения;
- Предоставляет сервер в качестве отдельной программы для сетевого окружения клиент/сервер.
Недостатки практической разработки и администрирования баз данных MySQL Приобретена компанией Oracle :
- пользователи полагают, что MySQL больше не подпадает под категорию бесплатного и открытого программного обеспечения;
- больше не поддерживается сообществом;
- пользователи не могут исправлять ошибки и патчи;
- проигрывает другим решениям из-за медленных обновлений.
PostgreSQL

PostgreSQL является еще одним выдающимся решением с открытым исходным кодом, работающим во всех основных операционных системах, включая Linux , UNIX ( AIX , BSD , HP-UX , SGI IRIX , Mac OS X , Solaris , Tru64 ) и Windows . PostgreSQL полностью отвечает принципам ACID ( атомарность, согласованность, изолированность, устойчивост ь).
- Возможность создания пользовательских типов данных и методов запросов;
- Среда разработки баз данных выполняет хранимые процедуры более чем на десятке языков программирования: Java , Perl , Python , Ruby , Tcl , C/C ++ и собственный PL/pgSQL ;
- GiST ( система обобщенного поиска ): объединяет различные алгоритмы сортировки и поиска: B-дерево , B+-дерево , R-дерево , деревья частичных сумм и ранжированные B+ -деревья ;
- Возможность создания для большего параллелизма без изменения кода Postgres , например, CitusDB .
- Система MVCC требует регулярной « чистки »: проблемы в средах с высокой скоростью транзакций;
- Разработка осуществляется обширным сообществом: слишком много усилий для улучшений.
SQLite

Провозгласившая себя самой распространенной СУБД в мире, SQLite зародилась в 2000 году и используется Apple , Facebook , Microsoft и Google . Каждый релиз тщательно тестируется. Разработчики SQLite предоставляют пользователям списки ошибок, а также хронологию изменений кода каждой версии.
- Нет отдельного серверного процесса;
- Формат файла – кросс-платформенный;
- Транзакции соответствуют требованиям ACID ;
- Доступна профессиональная поддержка.
Не рекомендуется для:
- клиент-серверных приложений;
- крупномасштабных сайтов;
- больших наборов данных;
- программ с высокой степенью многопоточности.
Я пропустила что-то из существенных преимуществ или недостатков решений для разработки баз данных , перечисленных выше? Считаете, что есть лучшие альтернативные СУБД ? Поделитесь своим мнением в комментариях.
Данная публикация представляет собой перевод статьи « The Top 7 Free and Open Source Database Software Solutions » , подготовленной дружной командой проекта Интернет-технологии.ру
Наверное, у каждого веб-разработчика есть любимые базы данных, с которыми он может спокойно работать, используя весь накопленный опыт.
Скорее всего, это одна из нижеприведенных:
Или иногда даже нечто еще легче, типа XML, текст и т.д.
То, что эти базы данных используют чаще всего, вполне объяснимо. С ними предоставляется отличная документация, у них большое число поклонников, которые всегда ответят вам на вопросы и дадут совет, их можно без труда использовать со всеми распространенными CMS, они достаточно просты в использовании, а также их советует большая часть компаний и сервисов, предоставляющих хостинговые услуги.
Но в мире есть много других баз данных, которые завоевывают известность изо дня в день, к тому же, у них даже могут быть преимущества перед теми программами, которые используете вы.
Мы представляем вашему вниманию список из 25+ альтернативных вариантов баз данных Open Source, которые вы вероятно захотите использовать, разрабатывая следующий проект:

Это высокопроизводительная база данных, ориентированная на документы (структуры типа JSON), которая распространяется с открытым кодом.
Программа может использовать драйвера для большинства популярных языков программирования (PHP,Python, Perl, Ruby, javascript, C++ и так далее).

Hypertable представляет собой высокопроизводительную систему хранения информации, разработанную для поддержки приложений, которым требуется максимальная производительность, гибкость и надежность.
Она была разработана по модели BigTable от Google и в основном сфокусирована на больших массивах информации.

Документально-ориентированная база данных с возможность запросов и индексирования в стиле MapReduce на javascript.
CouchDB предлагает простой API JSON, доступ к которому может быть осуществлен через любую среду, разрешающую HTTP-запросы.

Встроенный устойчивый Java-движок, который хранит данные в виде диаграмм, а не таблиц.
Neo4j предоставляет вам отличную гибкость в работе. Он может удерживать миллиарды параметров на одном отдельном компьютере, а также можно расширить функции за счет установки нескольких серверов.

Riak представляет собой почти идеальную базу данных для веб-приложений. Она сочетает в себе:
* децентрализованное хранилище ключей-значений
* гибкий движок map/reduce
* интерфейс дружественный с HTTP/JSON-запросами

Встраиваемый движок баз данных, который представляет собой быстрое, надежное и устойчивое решение.
Oracle Berkeley DB – это библиотека, которая ссылается напрямую в ваше приложение, и позволяет вам производить простые функции отправки сообщений на удаленный сервер для лучшей производительности.

Cassandra представляет собой гибкую базу данных второго поколения, которая используется такими гигантами как Facebook, Digg, Twitter, Cisco и другими.
Приложение нацелено на согласованную, устойчивую и доступную среду для хранения данных.

Memcached – это хранилище для небольших случайных фрагментов информации (строк, объектов) из запросов базы данных, запросов API или генерации страниц. Часто приложение используется для ускорения загрузки динамических веб-приложений за счет оптимизации запросов к базе данных.

Firebird – это база данных, работающая на Linux, Windows и различных UNIX-платформах.
Она гарантирует высокую производительность и полноценную поддержку языка для хранящихся процедур и схем.

Redis представляет собой продвинутую базу данных, разработанную на C, которую можно применять как в memcached, в отличие от обычных баз данных. Она поддерживает множество разных языков программирования и ее используют такие популярные проекты как GitHub или Engine Yard.
Существует также PHP-клиент под названием Rediska для управления базами данных Redis.

HBase разрабатывалась как хранилище в колонном формате. Приложение также может называться Hadoop database.
Проект нацелен на размещение очень больших таблиц.
Приложение оснащено межсетевым интерфейсом, который поддерживает XML, Protobuf и опцией кодировки бинарной информации.

Keyspace представляет собой хранилище ключей-значений, работающее в ОС Windows. Keyspace предлагает высокий уровень доступности посредством маскирующего сервера/сетевых ошибок и представляет собой отдельный доступный сервер.

4store представляет собой хранилище для баз данных и движок с поддержкой RDF-данных. Оно написано на ANSI C99, специально для работы на системах UNIX. Приложение предлагает высокую производительность, гибкость и стабильность.

MariaDB представляет собой обратно-совместимую, заменяемую ветку MySQL® Database Server.
Он включает в себя все известные движки хранения данных, которые распространяются с открытым кодом, а также движок хранилища Maria.

Ответвление от MySQL, которое нацелено на надежное оптимизирование баз данных для приложений Cloud и Net.

Движок для SQL-баз данных, который был написан на Java.
HyperSQL предлагает маленький и быстрый движок с таблицами в стиле in-memory и disk-based, а также поддерживает встроенные и серверные режимы.
К тому же, в приложении есть инструменты командной строки SQL и приложение опроса GUI.

MonetDB представляет собой систему баз данных для высокопроизводительных приложений в OLAP, GIS, XML-запросов и так далее.

Это движок хранения объектов и сервер приложений (работающий на Java/Rhino). Приложение предоставляет хранилище динамической даты JSON для интенсивной разработки богатых интернет-приложений на javascript.

eXist-db разработана с помощью технологии XML. Она хранит XML-данные в соответствии с моделью данных XML и предрасположен к функциям, и XQuery.
– Другие базы данных
Вам понравился материал? Поблагодарить легко!
Будем весьма признательны, если поделитесь этой статьей в социальных сетях:

Повсеместно принято, что в «серьезных» CRUD приложениях база данных становится во главу угла. Ее проектируют самой первой, она обрастает хранимыми процедурами (stored procedures), с ней приходиться возиться больше всего. Но это не единственный путь! Для Entity Framework есть Code First подход, где главным становится код, а не база. Преимущества:
- Никакого генерированного кода
- База — это снова просто хранилище. Над ней не надо дрожать, дропается легко и без проблем.
- Простейшая установка среды разработки. Выкачал код и запустил — никакой возни с бэкапами.
Есть и пара недостатков, но они скорее связаны с Entity Framework, а не с Code First подходом как таковым; о них чуть позже.
Ниже я покажу на примере, насколько просто разрабатывать с Code First подходом.
Пример
Возьмем простую модель:
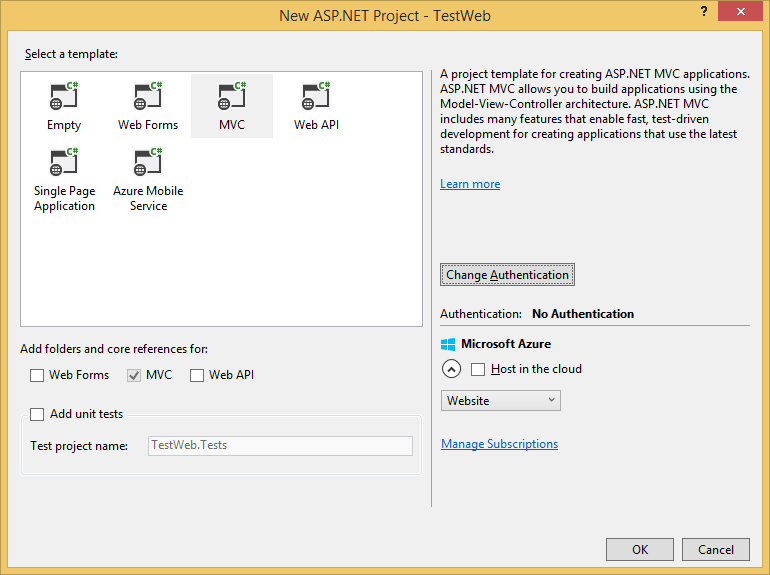
В качестве фронт-энда будет ASP.NET MVC, так что создаем соответствующий проект. Выбираем No Authentication — в этом проекте нельзя будет логиниться и весь контент доступен для всех.
Я сделал еще 2 проекта — для бизнес-объектов и DAL, но при желании можно просто создать соответствующие папки в web проекте. Не забудте установить Entity Framework в соответствующие проекты через NuGet.
Создаем классы, которые будут отображать сущности (entities):
Как видно, все повторяющееся свойства (properties) можно убрать в абстрактный класс и наследоваться от него. В данном случае у каждой таблицы будет Primary Key колонка типа Guid, который будет генерироваться при записи в базу.
Grade — это просто энумератор, ничего особенного:
Создаем контекстный класс:
Отношения дефинированы через Fluent API, читаются с конца — например, Student — Enrollment относятся как one (Student): many (Enrollment).
Стоит отметить, что конфигурировать модели можно как через Fluent API, так и аннотациями. Для некоторых настроек аннотаций не существует, но их можно создать самим. Я предпочитаю все-же Fluent API.
И, наконец, заполнение базы данными:
Примечание: как следует из названия DropCreateDatabaseIfModelChanges, база будет дропаться при изменениях в соответствующих классах моделей. То есть данные — капут.
Как реализовать миграции, чтобы данные не капут, выходит за область этой статьи.
Последнее, что надо сделать — добавить информацию в web.config. Используем LocalDb, которая идет вместе с Visual Studio, которой вполне достаточно для целей этого проекта. Следующий код идет в элемент configuration:
А следующая разметка — в элемент entityFramework:
В атрибуте type элемента context указываются через запятую название класса контекста и assembly, где этот класс находится. То же самое для инициализатора в элементе databaseInitializer.
Это вообщем-то и все, проект готов к запуску.
В Visual Studio 2013 можно по-быстрому сгенерировать Controller и View к выбранной модели через диалог Add -> New Scaffolded Item.

Скачать пример можно тут.
Недостатки
Во-первых, к существующей базе данных подобный подход применить сложно. Так что вообщем-то это для разработки с нуля.
Часто подножки ставит Entity Framework, который часто принимает решения за программиста — есть так называемые конвенции, что, допустим, property который называется Id, будет по умолчанию преобразован в Primary Key таблицы. Мне такой подход не нравится.
Продолжение темы
Разработка с помощью Code First подхода в Entity Framework достаточно объемная тема. Я не касался вопроса миграций, проблем с многопоточностью (concurrency) и многого другого. Если сообществу интересно, я могу продолжить эту тему в дальнейших статьях.
1. Getting started with Entity Framework 6 Code First using MVC 5
2. Database initialization in Code-First
3. Lerman J., Miller R. — Programming Entity Framework. Code First (2011)
Читают сейчас

Похожие публикации
- 18 апреля 2014 в 19:20
Реализация слоя доступа к данным на Entity Framework Code First
Entity Framework Code First — индексация полей и полнотекстовый поиск
Учебный курс. Создание модели данных Entity Framework для приложения ASP.NET MVC
Заказы
AdBlock похитил этот баннер, но баннеры не зубы — отрастут
Комментарии 23
Если не будет дальнейшего глубоко погружения, то это очередная статья «hello world EF», коих в интернете ну очень много. Продолжайте!
Если не устраивают конвенции по умолчанию, расскажите лучше как их переопределить.
Если не устраивают конвенции по умолчанию, расскажите лучше как их переопределить.
Если честно, для рунета технические статьи писать — дело неблагадарное. Если тема не про джаваскрипт или php, получишь 2.5 комментария, из которых 2 — критика в достаточно резкой форме.
Легче для англоязычных ресурсов писать, охват аудитории больше и люди спокойнее.
В каждом, каждом примере по Entity Framework есть эти DbSet в виде свойств. И никто никогда не объясняет, зачем они нужны, и что будет, если их убрать.
Это, надо заметить, очень, очень опасная настройка. Давать ее в примере, не объяснив, чем это грозит — очень недобро.
(Для тех, кто не знает: в результате этой настройки как только code-first-модель будет изменена — например, добавится новое свойство — существующая БД будет дропнута и создана заново. Да, со всеми данными.)
Ну и вообще, использовать такие инициализаторы при наличии миграций…
Во-первых, к существующей базе данных подобный подход применить сложно.
есть так называемые конвенции, что, допустим, property который называется Id, будет по умолчанию преобразован в Primary Key таблицы
Во-первых, это легко перенастраивается. Во-вторых, даже конвенцию можно отменить.
Ну и да, это не разработка баз данных никаких боком, это разработка DAL-слоя.
Ну и вообще, использовать такие инициализаторы при наличии миграций…
Во-первых, это вводная статья. Основоное преимущество разработки с Code First — скорость Это прототип, если угодно. В нормальном приложении никто не будет писать в базу из контроллера, но для прототипов Scaffolded items неоценимы. Для прототипов инициализатор вполне сойдет.
Как минимум потому что придется писать уродливые мапинги на существующие таблицы. Все можно сделать, вопрос — зачем.
Ну и да, это не разработка баз данных никаких боком, это разработка DAL-слоя.
Для прототипов инициализатор вполне сойдет.
Вот только вы нигде не пишете, почему этот инициализатор нельзя применять в продуктивном коде. И вообще не объясняете, что он делает.
Как минимум потому что придется писать уродливые мапинги на существующие таблицы.
Это зависит исключительно от уродливости базы. А зачем — а зачем вообще использовать Code First? Вот затем же.
Суть в том, что до появления реальных данных в Code First база — побочный продукт.
Вот только вы нигде не пишете, почему этот инициализатор нельзя применять в продуктивном коде. И вообще не объясняете, что он делает.
А зачем — а зачем вообще использовать Code First?
Заметим, я не говорю о переводе готового приложения, я говорю о работе с существующей БД, это не одно и то же.
Вы не учитываете того факта, что в БД могут быть (а) полезные данные (например, в продуктиве) и (б) данные и объекты, которые вообще не описаны в CF.
Не говоря уже о том, что (ц) создание БД может быть долгим процессом и (д) в норме у запускаемого приложения не должно быть прав на дроп БД.
(д) в норме у запускаемого приложения не должно быть прав на дроп БД.
Если вы не поняли, я говорил про девелопера, а не про приложение.
(ц) создание БД может быть долгим процессом
Для среднестатистической CRUD аппликации он не будет долгим.
(б) данные и объекты, которые вообще не описаны в CF
Ага, значит один объект мы из кода добавляем из кода в базу, а второй из базы в код. Прямо Code First 🙂
(а) полезные данные (например, в продуктиве)
Девелоперу зачем «полезные данные»? Чтобы чай попить, пока апликация грузится? Для load тестирования надо отдельную среду поднимать. Я уже молчу, что если вы базу с продукции девелоперам ставите, то вам любой аудит по пальцам надает, мало не покажется.
Предлагаю прекратить спор, т.к. каждый останется при своем мнении.
Если вы не поняли, я говорил про девелопера, а не про приложение.
Database initializer у вас выполняет разработчик? Мне кажется, что все-таки приложение. Это его часть. Соответственно, у приложения должны быть эти права. У вас права приложения отличаются в продуктиве и в разработческом контуре? Вас ждут приятные новости при выкатке.
Для среднестатистической CRUD аппликации он не будет долгим.
Что такое «среднестатистическая аппликация»? Среднестатистический блог, среднестатистический энтерпрайз, среднестатический магазин? Они все очень разные.
Ага, значит один объект мы из кода добавляем из кода в базу, а второй из базы в код.
С чего вы это взяли? Мы ничего не добавляем ни в одном из направлений, у нас просто есть часть БД, с которой работает новое приложение через EF-CF, а есть часть БД, с которой работает legacy. А где-то посередине они пересекаются. Процентов на 30.
Девелоперу зачем «полезные данные»?
Я же сказал — «в продуктиве». У вас разные инициализаторы в проде и в разработческом контуре? Хорошая идея, но очень хрупкая (особенно в части «как же выкатить изменения на продуктив»).
Чтобы чай попить, пока апликация грузится?
У вас объем данных влияет на скорость каждой загрузки приложения? Печаль. Или вы говорите о времени инициализации через drop-create? Так это ваша идея, а не моя, я этого подхода рекомендовал избегать.
Я уже молчу, что если вы базу с продукции девелоперам ставите, то вам любой аудит по пальцам надает, мало не покажется.
Мы не ставим базу с продуктива разработчикам, мы используем единый код (и единый механизм версионирования) в разработческом и продуктивном контурах.
Понимаете, когда приложение, с которым вы работаете — это унаследованная учетная система со сложной структурой бизнес-данных и несколькими десятками справочников, каждый из которых может влиять на бизнес-поведение, его инициализация — это дорого.
И, собственно, я бы понял предмет этого спора, если бы в EF-CF не было миграций — но миграции решают большую часть описанных проблем (кроме прав при развертывании, но они решаются за счет явной накатки миграций разработчиком в разработческой среде и инженером развертывания в продуктиве, благо, механизм, который это позволяет, есть). Так что я, честное слово, не вижу, зачем держаться за стремительно устаревающий DropCreate кроме как в прототипах на выброс, где нет речи ни о каких реально значимых данных и хоть сколько-нибудь продолжительном сроке жизни решения.
Как минимум потому что придется писать уродливые мапинги на существующие таблицы. Все можно сделать, вопрос — зачем.
существующая БД будет дропнута и создана заново. Да, со всеми данными.
«Все данные» — это только про «дропнута», или и про «создана заново»?
В каждом, каждом примере по Entity Framework есть эти DbSet в виде свойств. И никто никогда не объясняет, зачем они нужны, и что будет, если их убрать.
Заинтриговали прямо.
А зачем они нужны и что будет, если их убрать?
Disclaimer. В этой теме я абсолютный чайник, мне просто очень интересно. Уровень вопросов моих вы уже видите. Разумеется, вы не обязаны удовлетворять мой интерес — это очевидно. Но если ответите, буду признателен :).
«Все данные» — это только про «дропнута», или и про «создана заново»?
Дропнута. Создана она будет только с теми данными, которые прошиты в Seed .
А зачем они нужны и что будет, если их убрать?
Это, на самом деле, тема для длинного рассуждения. Начнем с первой части: для чего они нужны.
Во-первых, они нужны для того, чтобы предоставить пользователю контекста доступ к коллекциям сущностям — проще говоря, context.Courses . Проблема этого подхода в том, что он осмысленен очень непродолжительное время, и как только мы начинаем либо трактовать контекст как совсем низкоуровневый доступ, скрывая его за отдельным репозиторием (в этом случае достаточно публичного Set ), либо трактовать его как готовый репозиторий (в этом случае наружу выставляются сразу готовые методы Get , Find и так далее, а внутри, в общем-то, тоже достаточно Set ). Проще говоря, у этого интерфейса неадекватный уровень абстракции.
Во-вторых, они нужны для того, чтобы контекст знал, какими, собственно, сущностями он будет пользоваться (как следствие, что создавать в БД, по чему строить миграции и так далее). Однако это поведение иногда может быть непредсказуемым, поэтому лучше всегда явно прописывать конфигурацию в OnModelCreating .
Собственно, из этого и вытекает ответ на «что будет, если»: если у вас уже прописаны все конфигурации, или классы достижимы из прописанных конфигураций по конвенциям, и вы не опираетесь на наличие у контекста именованных свойств для доступа к данным — ничего не будет. Собственно, у меня таких контекстов достаточно много, и они прекрасно работают.