Помехоустойчивое кодирование осуществляется за счет введения в состав передаваемого сигнала довольно большого объема избыточной (контрольной) информации. В английской терминологии такое кодирование носит наименование Forward Error Correcting coding (FEC coding), т.е. кодирование с упреждающей коррекцией ошибок, или кодирование с коррекцией ошибок на проходе. В сотовой связи помехоустойчивое кодирование реализуется в виде трех процедур – блочного кодирования, сверточного кодирования и перемежения. Кроме того, кодер канала выполняет еще ряд функций: добавляет управляющую информацию, которая, в свою очередь, также подвергается помехоустойчивому кодированию; упаковывает подготовленную к передаче информацию и сжимает ее во времени; осуществляет шифрование передаваемой информации, если таковое предусмотрено режимом работы аппаратуры. Последовательность выполнения этих задач показана на блок-схеме рис. 10.
При блочном кодировании входная информация разделяется на блоки, содержащие по k символов каждый, которые по определенному закону преобразуются кодером в n-символьные блоки, причем n > k (рис. 10). Отношение R = k/n носит наименование скорости кодирования и является мерой избыточности, вносимой кодером. При рационально построенном кодере меньшая скорость кодирования, т.е. большая избыточность, соответствует более высокой помехоустойчивости.
Повышению помехоустойчивости способствует также увеличение длины блока. Блочный кодер с параметрами n, k обозначается (n, k). Если символы входной и выходной последовательностей являются двоичными, т.е. состоят из одного бита каждый, то кодер называется двоичным; именно двоичные кодеры используются в сотовой связи. Схема, представленная на рис. 11, соответствует двоичному блочному кодеру (5, 4).
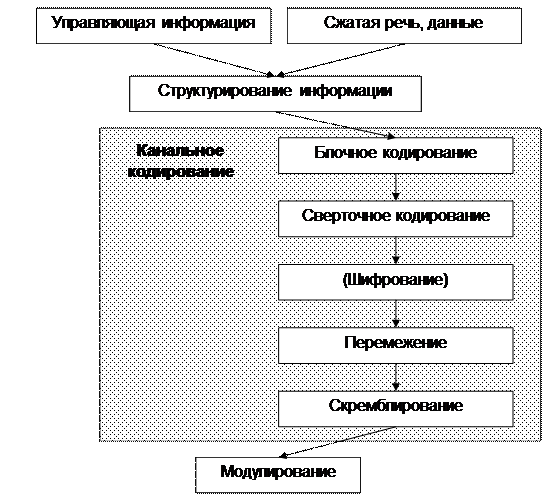
Рисунок 10 – Канальное кодирование
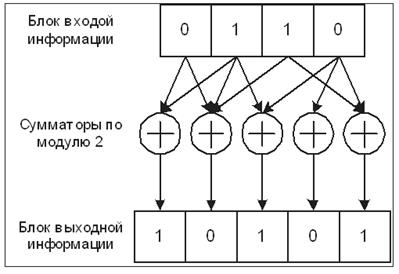
Рисунок 11 – Блочное кодирование
Каждый бит блока выходной информации является суммой по модулю 2 нескольких бит (от одного до k) входного блока, для чего используется n сумматоров по модулю 2. Один из сумматоров на схеме рис. 11 (второй справа) является вырожденным – на его вход поступает лишь одно слагаемое.
При сверточном кодировании (рис. 12) К последовательных символов входной информационной последовательности, по k бит в каждом символе, участвуют в образовании n-битовых символов выходной последовательности, n > k, причем на каждый символ входной последовательности приходится по одному символу выходной.
а)  б)
б) 
Рисунок 12 – Схема сверточного кодирования (4, 2, 5) (n = 4, k = 2; R = k/n = 1/2). а) – побайтовый контроль четности позволяет обнаружить одиночные ошибки в байтах; б) – добавление еще 8-го бита контроля позволяет исправить одиночную ошибку в восьми байтах
Каждый бит выходной последовательности получается как результат суммирования по модулю 2 нескольких бит (от двух до Kk бит) К входных символов, для чего используются п сумматоров по модулю 2. Сверточный кодер с параметрами n, k, К обозначается (n, k, K). Отношение R = k/n, как и в блочном кодере, называется скоростью кодирования.
Параметр К называется длиной ограничения (constraint length); он определяет длину сдвигового регистра (в символах), содержимое которого участвует в формировании одного выходного символа. После того, как очередной выходной символ сформирован, входная последовательность сдвигается на один символ вправо (рис. 11). В результате символ 1 выходит за пределы регистра, символы 2…5 перемещаются вправо, каждый на место соседнего, а на освободившееся место записывается очередной символ входной последовательности, и по новому содержимому регистра формируется следующий выходной символ. Название сверточного кода обязано тому, что он может рассматриваться как свертка импульсной характеристики кодера и входной информационной последовательности. Если k = 1, т.е. символы входной последовательности однобитовые, сверточный кодер называется двоичным. Сверточный кодер, схема которого приведена на рис. 11, не является двоичным, поскольку для него k = 2.
Перемежение представляет собой такое изменение порядка следования символов информационной последовательности, т.е. такую перестановку, символов, при которой стоявшие рядом символы оказываются разделенными несколькими другими символами. Такая процедура предпринимается с целью преобразования групповых ошибок (пакетов ошибок) в одиночные ошибки, с которыми легче бороться с помощью блочного и сверточного кодирования. Использование перемежения – одна из характерных особенностей сотовой связи, что это является следствием неизбежных глубоких замираний сигнала в условиях многолучевого распространения, которое практически всегда имеет место, особенно в условиях плотной городской застройки. При этом группа следующих один за другим символов, попадающих на интервал замирания (провала) сигнала, с большой вероятностью оказывается ошибочной. Если же перед выдачей информационной последовательности в радиоканал она подвергается процедуре перемежения, а на приемном конце восстанавливается прежний порядок следования символов, то пакеты ошибок с большой вероятностью рассыпаются на одиночные ошибки, вероятность исправления которых значительно выше.
Известно несколько различных схем перемежения и их модификаций – диагональная, блочная, свёрточная и другие.
В канальном кодирование так же осуществляется и скремблирование. Скремблирование – разновидность кодирования информации для передачи по каналам связи, улучшающая спектральные и статистические характеристики сигнала. Скремблирование есть приведение информации к виду, по различным характеристикам похожему на случайные данные. Скремблирование выравнивает спектр сигнала, частоты появления различных символов и их цепочек.
В стандарте GSM повышение эффективности канального кодирования и перемежения при малой скорости перемещения подвижных станций достигается медленным переключением рабочих частот сеанса связи (со скоростью 217 скачков в секунду). Главное назначение медленных скачков – обеспечение частотного разнесения в радиоканалах, функционирующих в условиях многолучевого распространения радиоволн. Принцип формирования медленных скачков по частоте состоит в том, что сообщение в каждом последующем кадре передается (принимается) на новой фиксированной частоте. Параметры последовательности переключений частот (частотно-временная матрица и начальная частота) назначаются для каждой подвижной станции в процессе установления канала связи. Этот метод несколько модифицированный используется и в широкополосных системах связи.
Не нашли то, что искали? Воспользуйтесь поиском:
Лучшие изречения: При сдаче лабораторной работы, студент делает вид, что все знает; преподаватель делает вид, что верит ему. 9369 –  | 7304 –
| 7304 –  или читать все.
или читать все.
1. Общая структура канального кодирования
Для защиты от ошибок в каналах радиосвязи систем стандарта TETRA используется помехоустойчивое канальное кодирование сигнала, которое осуществляется путем введения в состав передаваемого сигнала достаточно большого объема дополнительной (избыточной) информации. В стандарте TETRA канальное кодирование реализуется в виде 4-х процедур:
- блочного кодирования (block-encoding);
- сверточного кодирования (convolutional encoding);
- перемежения (interleaving);
- скремблирования (scrambling).
При блочном кодировании входная информация разбивается на блоки по k символов, которые преобразуются по определенному закону в n-символьные блоки, где n>k [14]. Блочное кодирование предназначено, в основном, для обнаружения одиночных и групповых ошибок в канале связи и в определенных случаях для их исправления.
При сверточном кодировании каждый символ входной информационной последовательности, состоящий из k бит, преобразуется в n-битовый символ выходной последовательности, причем n>k. Сверточное кодирование является мощным средством борьбы с одиночными ошибками, хотя и не обеспечивает их обнаружения.
При перемежении производится изменение порядка следования символов информационной последовательности таким образом, что стояшие рядом символы оказываются разделенными несколькими другими. Перемежение обеспечивает преобразование групповых ошибок в канале связи в одиночные.
Скремблирование состоит в преобразовании входной информационной последовательности в выходную путем ее побитного сложения по модулю 2 со специально формируемой шифровальной последовательностью. Скремблирование используется для определенной защиты передаваемой информации, а также для аутентификации абонентов.
Структура канального кодирования, представленная на рис. 8.1, является общей для всех типов логических каналов, хотя параметры каждой из процедур канального кодирования для различных логических каналов, как правило, отличаются. Поэтому в дальнейшем будут приведены общие алгоритмы преобразований по каждой из процедур, а затем указаны параметры этих преобразований для каждого типа логического канала.
Стандарт TETRA описывает процесс канального кодирования как последовательное преобразование данных на 4-х уровнях, при этом входные данные обозначаются как биты типа 1 в блоках типа 1, данные после блочного кодирования – биты типа 2 в блоках типа 2 и т. д. После блочного кодирования к битам, закодированным блочным кодом, добавляются т. н. "хвостовые" биты.

Рис. 8.1. Общая схема канального кодирования в стандарте TETRA.
Для дальнейшего описания процедур канального кодирования введем следующие обозначения:
- x – порядковый номер типа бит и блоков, x = 1,2,3,4,5;
- Kx – число битов, переносимых одним блоком типа x;
- k – номер бита, k = 1,2. Kx;
- bx(k) – бит типа x в с номером k в блоке типа x.
2. Блочное кодирование
Блочный кодер обозначается (K2,K1), где K1 – число символов в блоке входной последовательности, а K2 – число символов в блоке выходной последовательности. Отношение R=K1/K2 носит наименование скорости кодирования (coding rate) и характеризует меру избыточности, вносимую кодером.
При блочном кодировании в стандарте TETRA используется двоичный систематический кодер, т. е. кодер, у которого каждый символ входной и выходной последовательности соответствует одному биту, а в состав блока выходной информации полностью включается блок входной информации, который дополняется p-битовым кодом циклического контроля избыточности (CRC – Cyclic Redundancy Check). Таким образом, K1 битов типа 1 преобразуются в K2 бита типа 2, где K2=K1+p.
CRC-коды вычисляются по правилу
F(X) = X n-K1 M(X) mod G(X),
G(X) – формирующий полином, различный для разных логических каналов;
n-K1 – количество создаваемых битов четности.
Многочлен F(X) является многочленом степени (n-K1-1) с коэффициентами f(0), f(1). f(n-K1-1), т. е.

Тогда K2 бит типа 2 имеют вид:
b2(k) = b1(k) при k = 1,2. K1
b2(k) = f(k-K1-1) при k = K1+1, K1+2. n.
Порождающий полином для канала речевого трафика имеет вид:
для остальных каналов:
G(X) = 1 + X 5 + X 12 + X 16 .
Для одного из логических каналов – канала назначения доступа AACH – используется блочное кодирование на основе кода Рида-Маллера. Коды Рида-Маллера представляют собой класс линейных кодов с простым описанием и декодированием, осуществляемым методом простого голосования [15].
Порождающая матрица кода Рида-Маллера r-го порядка длиной 2 m определяется как совокупность блоков

где G – вектор размерности n=2 m , состоящий из одних единиц; Gp – (m х 2 m )- матрица, содержащая в качестве столбцов все двоичные m-последовательности; строки матрицы Gp получены из строк матрицы G1 как все возможные произведения p строк из G1 [15].
При блочном кодировании канала AACH стандарта TETRA 14 бит входной информационной последовательности должно преобразовываться в 30-разрядный выходной блок в соответствии с уравнением
где G – порождающая матрица, имеющая вид
где I14 – единичная матрица размером 14х14, а GRM – порождающая матрица кода Рида-Маллера размерностью 16х14.
Это означает, что при блочном кодировании AACH первые 14 бит выходной последовательности соответствуют битам входного информационного блока, а последующие 16 бит образуются с помощью кода Рида-Маллера.
3. Сверточное кодирование
Сверточное кодирование обеспечивает преобразование K2 входных бит типа 2, полученных в результате блочного кодирования, в K3 бит выходной последовательности, причем K3 > K2. Каждый бит выходной последовательности получается как результат суммирования по модулю 2 нескольких следующих друг за другом битов входной последовательности.
Сверточные кодеры обычно обозначаются как n,k,K, где n – количество бит в одном символе выходной последовательности, которые формируются за один такт работы кодера (соответствует числу сумматоров по модулю 2 в схеме кодера); k – количество бит в одном символе входной последовательности, поступающих на вход кодера за один такт; K – длина ограничения (constraint length), т. е. числовое значение, соответствующее длине сдвигового регистра, который участвует в формировании одного выходного символа. (Символы могут состоять из одного или нескольких бит.) При этом отношение R = k/n, как и в блочном кодере, называется скоростью кодирования.
Однако поскольку в стандарте TETRA непосредственно сверточное кодирование дополняется процедурой прореживания полученной информации, изменяющей количество бит выходной последовательности, под скоростью кодирования будем понимать отношение суммарного количества бит входной последовательности к суммарному количеству бит выходной последовательности (K2/K3).
В связи с тем, что объемы блоков, а также требования по помехоустойчивости и скорости передачи информации в разных логических каналах отличны друг от друга, сверточные коды для этих логических каналов также различаются. Сверточное кодирование в стандарте TETRA состоит из двух процедур:
- кодирования "материнским" кодом с фиксированной скоростью (для канала речевых сообщений TCH/S она соответствует 1/3, для всех остальных каналов – 1/4);
- перфорирования (прореживания, выкалывания) полученной последовательности, т. е. пропуска некоторых кодированных символов с целью приведения структуры размещения бит в соответствие со структурой кадра. Изменение алгоритмов перфорирования позволяет обеспечить различную скорость сверточного кодирования для разных логических каналов.
Кодирование материнским кодом
При кодировании материнским кодом используется сверточный кодер (n,1,5), где n – для канала трафика речи (TCH/S) равно 3, а для всех остальных каналов – 4.
Любой из порождающих многочленов материнского кода может быть записан в виде

где gi,j = 0 или 1, j = 0,1,2,3,4.
Это означает, что закодированные биты определяются как

где сумма берется по модулю 2, а b2(k-j)=0 при k≤j.
Порождающие многочлены материнского кода имеют вид:
-
для канала трафика речи:
G1(D) = 1 + D + D 2 + D 2 + D 3 + D 4
G2(D) = 1 + D + D 3 + D 4
G3(D) = 1 + D 2 + D 4
G1(D) = 1 + D + D 4
G2(D) = 1 + D 2 + D 3 + D 4
G3(D) = 1 + D + D 2 + D 4
G4(D) = 1 + D + D 3 + D 4 .
В качестве иллюстрации на рис. 8.2 показана схема сверточного кодера для всех логических каналов стандарта TETRA, отличных от канала речевого трафика.
Перфорирование материнского кода
Перфорирование материнского кода производится путем отбора K3 битов из nK2 битов V(k), полученных при сверточном кодировании. Отбор, т. е. определение битов выходной последовательности,
производится с помощью т. н. коэффициентов перфорирования P(1), P(2). P(t), определяющих номер выбираемого бита в отрезке входной последовательности длиной Period (значение t соответствует количеству выбираемых битов в данном отрезке), в соответствии с правилом вычисления значения k
k = Period ·((i-1) div t) + P(i – t(i-1) div t)),
где div означает результат целочисленного деления.

Рис. 8.2. Схема сверточного кодера логических каналов TETRA.
Значения Period, i, t, а также конкретные значения P(1), P(2). P(t) определяются для каждого типа логического канала отдельно. Для большинства каналов i=j, однако для некоторых из них значение i вычисляется более сложным образом, например, для канала TCH/4,8
i = j + (j-1) div 65.
Period для большинства логических каналов равен 8, в каналах речевого трафика он может принимать значения 12 и 24. Параметр t может принимать значения 3, 6, 9, 17.
При перемежении обеспечивается преобразование K3 бит входной последовательности, полученной в результате сверточного кодирования, в K4 бит выходной последовательности, причем K3 = K4, т. е. перемежение не вносит в сигнал избыточность, а только производит перестановку битов в информационном блоке.
Перемежение используется для преобразования групповых ошибок, возникающих в канале связи из-за наличия глубоких замираний сигнала в условиях многолучевого распространения, в одиночные, с которыми легче бороться с помощью блочного и сверточного кодирования [14].
В стандарте TETRA применяется 2 вида перемежения: блочное и перемежение по N блокам.
Блочный перемежитель обозначается (K,J), где K означает количество бит во входном информационном блоке, а J – количество бит, на которое разносятся соседние для входного блока биты. При блочном перемежении соответствие битов выходного блока битам входной последовательности, т. е.
производится по следующему правилу:
Работу схемы блочного перемежителя можно представить как проведение последовательной построчной записи входной информационной последовательности в матрицу, в которой длина строки соответствует J (число столбцов (K div J + 1)), а затем считывания записанной информации по столбцам.
Блочное перемежение с различными параметрами преобразования используется в каналах SCH/HD, SCH/HU, SCH/F, BNCH, STCH, BSCH и TCH/S.
Перемежение по N блокам
Перемежение по N блокам применяется в логических каналах передачи данных TCH/2,4 и TCH/4,8, информация по которым передается блоками длиной 432 бита.
При данной схеме перемежения блочная перестановка битов дополняется т. н. диагональным перемежением. Его особенностью является то, что оно производится одновременно для нескольких последовательных блоков, т. е. может осуществляться перестановка битов из одного блока в другой. Количество блоков, участвующих в перемежении, (N), может быть равным 1, 4 или 8 (N=1 – вырожденный случай, при котором перемежение осуществляется в пределах одного блока). При этом в результате перемежения образуется M+N-1 блоков по 432 бита, где M – целое число, т. е. процедура перемежения по N блокам может увеличивать общее количество информационных блоков.
Таким образом, при перемежении по N блокам преобразование входной информации производится в 2 этапа: 1-й этап – диагональное перемежение с увеличением общего количества блоков, 2-й этап – блочное перемежение в каждом из полученных блоков.
Первоначально M блоков B3(1), B3(2). B3(M), участвующих в преобразовании, с помощью диагонального перемежителя преобразуются в M+N-1 блоков B3‘(1), B3‘(2). B3‘(M+N-1). Если обозначить k-й бит блока B3‘(m) как b3‘(m,k), где k=1,2. 432, а m=1,2. M+N-1, то
b3‘(m,k) = 0 вне этой области, где
j = (k-1) div (432/N) и i = (k-1) mod (432/N).
Практически это означает формирование M+N-1 блоков, каждый из которых состоит из 1/M-х частей следующих друг за другом M блоков (при M=2 это половина блока, при M=3 – 1/3 блока и т. д.). Для первых и последних блоков, количество которых соответствует увеличению общего числа блоков, свободные разряды заполняются нулями (при M=2 нулями заполняется вторая половина первого и первая половина последнего блока, при M=3 нулями заполняются первые две трети первого блока, первая треть второго блока, первая треть предпоследнего блока и первые две трети последнего блока). При этом следует учитывать, что предварительно в каждом из N блоков биты также переставляются путем сборки в блоке сначала бит с номерами 1, 1+M, 1+2M. , затем 2, 2+M, 2+2M и т. д.
На втором этапе производится блочное перемежение битов в каждом из полученных блоков в соответствии с правилом
где i = 1 + ((103·k) mod 432), а k = 1,2. 432.
Скремблирование обеспечивает преобразование K4 битов входного информационного блока, поступающего от перемежителя, в K5 бит выходного блока путем побитового сложения по модулю 2 с шифровальной последовательностью.
Инициализация 32-разрядного сдвигового регистра с обратными связями, используемого для формирования шифровальной последовательности, производится с помощью расширенной обучающей последовательности c1, c2. c30, приведенной в разделе 5.2, и двух дополнительных бит, равных 1.
Особенности канального кодирования для различных логических каналов
Канальное кодирование каждого из логических каналов имеет свои отличия, касающиеся наличия или отсутствия отдельных процедур кодирования, видов блочного кодирования и перемежения, а также параметров всех процедур канального кодирования. На рис. 8.3 и 8.4 показана структура канального кодирования для всех логических каналов за исключением канала речевого трафика TCH/S.

Рис. 8.3. Структура канального кодирования логических каналов TCH7,2; SCH/HD; SCH/HU; SCH/F; BNCH; STCH.

Рис. 8.4. Структура канального кодирования логических каналов AACH; BSCH; TCH4,8; TCH2,4.
Особенность канального кодирования трафика речи заключается в разделении первичного информационного блока из 137 бит, поступающих с выхода речевого кодера, на 3 класса в соответствии с чувствительностью к ошибкам в канале связи. (Биты 1-го класса являются наименее чувствительными и кодируются достаточно слабо, биты класса 3 обладают высокой чувствительностью к помехам и поэтому подвергаются наиболее мощному помехоустойчивому кодированию.)
Временной кадр, как правило, включает в себя 2 речевых кадра, каждый из которых на выходе речевого кодека имеет размерность 137 бит (см. раздел 7). После канального кодирования информация с выхода речевого кодека (2 137 бит) преобразуется в информационный кадр длиной 432 бита.
1-й класс включает 51 из каждого речевого кадра (2 51), 2-й класс – 56 бит (2 56), 3-й класс – 30 бит (2 56). К наиболее чувствительному 3-му классу относятся:
- 12 бит, содержащие 4 старших разряда 3-х 8-разрядных коэффициентов линейного предсказания;
- 6 бит, содержащие 6 старших разрядов 8-разрядного значения периода основного тона первого (из 4-х) сегмента речевого кадра;
- 12 бит, содержащие 3 старших разряда 4-х 6-разрядных коэффициентов усиления для каждого из сегментов речевого кадра.
- Кодирование производится раздельно для каждого из классов:
- биты 1-го класса подвергаются только перемежению и скремблированию;
- над битами 2-го класса производится сверточное кодирование, перемежение и скремблирование;
- биты 3-го класса подвергаются всем видам канального кодирования: блочному и сверточному кодированию, перемежению и скремблированию.
Следует отметить, что перемежение и скремблирование производятся над полным блоком из 432 бит, в который включаются биты всех классов чувствительности.
Структура кодирования для канала речевого трафика представлена на рис. 8.5.

Рис. 8.5. Структура канального кодирования речевого трафика.
Под кодированием понимают отображение сообщения в сигнал для передачи по его каналу.
Классификация методов кодирования:
Примитивное или избыточное примитивное кодирование применяется для согласования алфавита источника и алфавита канала. Примитивное кодирование используется также в целях шифрования передаваемой информации и повышения устойчивости работы системы синхронизации. В последнем случае правило кодирования выбирается так, чтобы вероятность появления на выходе кодера длинной последовательности, состоящей только из нулей и единиц, была минимальной. Подобный кодер называется также скремблером.
Экономное кодирование, или сжатие данных, применяется для уменьшения времени передачи информации или требуемого объема памяти при ее хранении. Отличительное свойство экономного кодирования состоит в том, что избыточность источника, образованного выходом кодера, меньше, чем избыточность источника на входе кодера. Экономное кодирование применяется в ЭВМ.
Помехоустойчивое или избыточное кодирование применяется для обнаружения и (или) исправления ошибок, возникающих при передаче по каналу. Отличительное свойство помехоустойчивого кодирования состоит в том, что избыточность источника, образованного выходом кодера, больше, чем избыточность источника на входе кодера.
Кодирование источника— это преобразование аналогового сигнала в цифровой (для аналоговых источников) иудаление избыточной (ненужной) информации.
В качестве дополнительных элементов для борьбы с помехами применяют: кодер источника и кодер канала. На рисунке приведена схема преобразования электрического сигнала в цифровую форму с помощью кодера источника:

На рисунке изображен кодер канала одноканальной и многоканальной СП:

КИ – кодер источника,
ДКИ – декодер источника,
ЭФП – электрофизический преобразователь,
Мн – модулятор несущей,
Дн – демодулятор несущей,
Гн – генератор несущей,
ηи(t) – избыточный сигнал с функциональной зависимостью между элементами,
ПНФ – преобразователь в нужную форму,
ЛЧП – линейная часть приемника,
КК – кодер канала, ДКК – декодер канала,
УУК – устройство уплотнения каналов,
УРК – устройство разделения каналов.
Кодер канала – второй (и последний) элемент собственно цифрового участка передающего тракта. Он следует после кодера речи и предшествует модулятору, осуществляющему перенос информационного сигнала на несущую частоту. Основная задача кодера канала – помехоустойчивое кодирование сигнала речи, т.е. такое его кодирование, которое позволяет обнаруживать и в значительной мере исправлять ошибки, возникающие при распространении сигнала по каналу от передатчика к приемнику.
Помехоустойчивое кодирование иначе называется канальным кодированием,поскольку предназначается для нейтрализации канальных помех. Помехоустойчивое кодирование осуществляется за счет введения в состав передаваемого сигнала довольно большого объема избыточной (контрольной) информации. Кроме того, кодер канала выполняет еще ряд функций: добавляет управляющую информацию, которая, в свою очередь, также подвергается помехоустойчивому кодированию; упаковывает подготовленную к передаче информацию и сжимает ее во времени; осуществляет шифрование передаваемой информации, если таковое предусмотрено режимом работы аппаратуры.
Канальное кодирование реализуется в виде 4-х процедур:
При блочном кодировании входная информация разбивается на блоки по k символов, которые преобразуются по определенному закону в n-символьные блоки, где n>k. Блочное кодирование предназначено, в основном, для обнаружения одиночных и групповых ошибок в канале связи и в определенных случаях для их исправления.
При сверточном кодировании каждый символ входной информационной последовательности, состоящий из k бит, преобразуется в n-битовый символ выходной последовательности, причем n>k. Сверточное кодирование является мощным средством борьбы с одиночными ошибками, хотя и не обеспечивает их обнаружения.
При перемежении производится изменение порядка следования символов информационной последовательности таким образом, что стоящие рядом символы оказываются разделенными несколькими другими. Перемежение обеспечивает преобразование групповых ошибок в канале связи в одиночные.
Скремблирование состоит в преобразовании входной информационной последовательности в выходную путем ее побитного сложения по модулю 2 со специально формируемой шифровальной последовательностью. Скремблирование используется для определенной защиты передаваемой информации, а также для аутентификации абонентов.
Существует множество способов кодирования источником сообщений. Рассмотрим кодирование источников с известной статистикой сообщений. Общая идея построения такого кода доказывается теоремой кодирования для каналов без помех. Поскольку минимизируется средняя длина кодовой последовательности, то код должен быть неравномерным. Очевидно, что средняя длина неравномерного кода будет минимизироваться тогда, когда с более вероятными сообщениями источника будут сопоставляться более короткие комбинации канальных символов. Проблема состоит в том, что у неравномерного кода на приемной стороне оказываются неизвестными границы этих комбинаций. Если же попытаться их выделить, используя известный способ кодирования, то декодирования может оказаться неоднозначным. Для того чтобы используемый код обладал свойством однозначной декодируемости, он должен удовлетворять некоторым условиям. Однозначное декодирование будет обеспечено, если ни одно кодовое слово не является началом другого кодового слова. Такие коды называют префиксными.
Необходимые и достаточные условия существования префиксного кода определяются неравенством Крафта, которое формулируется в виде теоремы:
Пусть m – объем алфавита дискретного канала без помех, а ni, i= 1,2,…,М, есть конечное множество положительных целых чисел. Для существования семейства М последовательностей с длинами n1, n2, …,nM, обладающего свойством префиксного кода, необходимо и достаточно выполнение следующего неравенства: 
Канальным (помехоустойчивым) блоковым кодом V будем называть любое множество из М различных последовательностей (комбинаций, слов) х1, х2, х3, …, хМ длины n, каждая позиция которых может принимать любое их m значений входного алфавита Х, если М n .
Такой код также называют избыточным. При выполнении равенства М=m n код называется примитивным. Будем называть скоростью кода величину  ; если M=2 k и m=2, то R=k/n.
; если M=2 k и m=2, то R=k/n.
11. Дискретное преобразование Фурье (ДПФ в экспоненциальной и тригонометрической форме, свойства ДПФ). Область применения.
Для цифровой обработки требуются как дискретные отсчеты сигнала, так и дискретные отсчеты спектра. Известно что дискретный (или как еще говорят линейчатый спектр) имеют периодические сигналы, а линейчатый спектр получается путем разложения в ряд Фурье периодического сигнала. Значит, чтобы получить дискретный спектр, надо сделать исходный дискретный сигнал периодическим, или другими словами необходимо повторить данный сигнал во времени бесконечное количество раз с некоторым периодом  , тогда его спектр будет содержать дискретные гармоники кратные
, тогда его спектр будет содержать дискретные гармоники кратные  . Графически процесс повторения сигнала во времени представлен на рисунке 2.
. Графически процесс повторения сигнала во времени представлен на рисунке 2.

Рисунок 2: Повторение сигнала во времени
Черным показан исходный сигнал, серым его повторения через некоторый период .
Как следует из рисунка 2, повторять сигнал можно с различным периодом , однако необходимо чтобы период повторения был более или равен длительности сигнала, т.е.  . При этом минимальный период повторения сигнала
. При этом минимальный период повторения сигнала
 . . |
(10) |
Это тот минимальный период при котором сигнал и его повторения не накладываются друг на друга. Повторение сигнала с минимальным периодом  представлен на рисунке 3.
представлен на рисунке 3.

Рисунок 3: Повторение сигнала с минимальным периодом
При повторении сигнала с минимальным периодом получим линейчатый спектр сигнала, состоящий из гармоник кратных
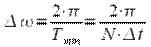 |
(11) |
и на одном периоде  получим
получим
 |
(12) |
Таким образом мы можем продискретизировать спектр дискретного сигнала на одном периоде повторения 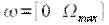 с шагом
с шагом 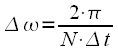 и получим тем самым
и получим тем самым  отсчетов спектра. Учтем вышесказанное в выражении (7), получим:
отсчетов спектра. Учтем вышесказанное в выражении (7), получим:
 |
(13) |
Если опустить в выражении (13) шаг дискретизации по времени 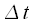 и по частоте
и по частоте  , то получим окончательное выражение для ДПФ:
, то получим окончательное выражение для ДПФ:
 |
(14) |
Можно сделать вывод, что ДПФ ставит в соответствие отсчетам дискретного сигнала отсчетов дискретного спектра, при этом предполагается, что и сигнал и спектр являются периодическими и анализируются на одном периоде.
Свойство 1. Линейность
Спектр суммы сигналов равен сумме спектров этих сигналов. Если  то спектр
то спектр  равен:
равен:
 |
(2) |
где  и
и  – спектры сигналов
– спектры сигналов  и
и 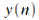 соответственно.
соответственно.
Свойство 2. Временной сдвиг
Пусть сигнал  имеет спектр
имеет спектр  . Если сдвинуть сигнал циклически на
. Если сдвинуть сигнал циклически на  отсчетов, т.е.
отсчетов, т.е.  , то спектр сдвинутого сигнала равен:
, то спектр сдвинутого сигнала равен:
 |

Поперечные профили набережных и береговой полосы: На городских территориях берегоукрепление проектируют с учетом технических и экономических требований, но особое значение придают эстетическим.

Организация стока поверхностных вод: Наибольшее количество влаги на земном шаре испаряется с поверхности морей и океанов (88‰).

Общие условия выбора системы дренажа: Система дренажа выбирается в зависимости от характера защищаемого.

Опора деревянной одностоечной и способы укрепление угловых опор: Опоры ВЛ – конструкции, предназначенные для поддерживания проводов на необходимой высоте над землей, водой.