Гистограмма распределения – это инструмент, позволяющий визуально оценить величину и характер разброса данных. Создадим гистограмму для непрерывной случайной величины с помощью встроенных средств MS EXCEL из надстройки Пакет анализа и в ручную с помощью функции ЧАСТОТА() и диаграммы.
Гистограмма (frequency histogram) – это столбиковая диаграмма MS EXCEL, в каждый столбик представляет собой интервал значений (корзину, карман, class interval, bin, cell), а его высота пропорциональна количеству значений в ней (частоте наблюдений).
Гистограмма поможет визуально оценить распределение набора данных, если:
- в наборе данных как минимум 50 значений;
- ширина интервалов одинакова.
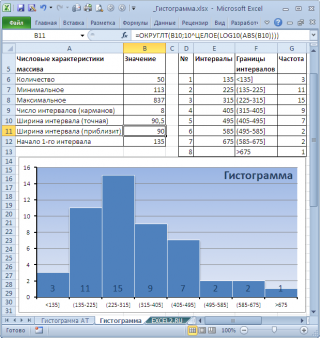
Построим гистограмму для набора данных, в котором содержатся значения непрерывной случайной величины. Набор данных (50 значений), а также рассмотренные примеры, можно взять на листе Гистограмма AT в файле примера. Данные содержатся в диапазоне А8:А57.
Примечание: Для удобства написания формул для диапазона А8:А57 создан Именованный диапазон Исходные_данные.
Построение гистограммы с помощью надстройки Пакет анализа
Вызвав диалоговое окно надстройки Пакет анализа, выберите пункт Гистограмма и нажмите ОК.
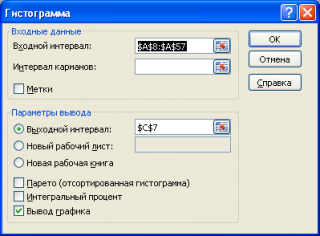
В появившемся окне необходимо как минимум указать: входной интервал и левую верхнюю ячейку выходного интервала. После нажатия кнопки ОК будут:
- автоматически рассчитаны интервалы значений (карманы);
- подсчитано количество значений из указанного массива данных, попадающих в каждый интервал (построена таблица частот);
- если поставлена галочка напротив пункта Вывод графика, то вместе с таблицей частот будет выведена гистограмма.
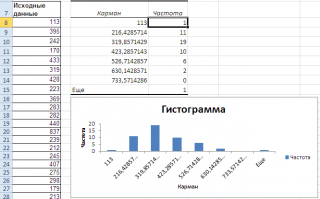
Перед тем как анализировать полученный результат – отсортируйте исходный массив данных.
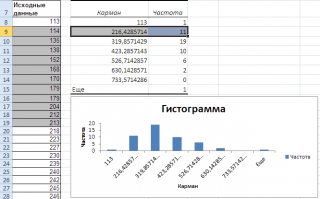
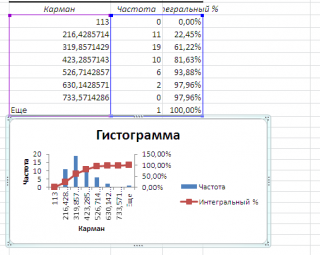
Как видно из рисунка, первый интервал включает только одно минимальное значение 113 (точнее, включены все значения меньшие или равные минимальному). Если бы в массиве было 2 или более значения 113, то в первый интервал попало бы соответствующее количество чисел (2 или более).
Второй интервал (отмечен на картинке серым) включает значения больше 113 и меньше или равные 216,428571428571. Можно проверить, что таких значений 11. Предпоследний интервал, от 630,142857142857 (не включая) до 733,571428571429 (включая) содержит 0 значений, т.к. в этом диапазоне значений нет. Последний интервал (со странным названием Еще) содержит значения больше 733,571428571429 (не включая). Таких значений всего одно – максимальное значение в массиве (837).
Размеры карманов одинаковы и равны 103,428571428571. Это значение можно получить так:
=(МАКС(Исходные_данные)-МИН(Исходные_данные))/7
где Исходные_данные – именованный диапазон, содержащий наши данные.
Почему 7? Дело в том, что количество интервалов гистограммы (карманов) зависит от количества данных и для его определения часто используется формула √n, где n – это количество данных в выборке. В нашем случае √n=√50=7,07 (всего 7 полноценных карманов, т.к. первый карман включает только значения равные минимальному).
Примечание: Похоже, что инструмент Гистограмма для подсчета общего количества интервалов (с учетом первого) использует формулу
=ЦЕЛОЕ(КОРЕНЬ(СЧЕТ(Исходные_данные)))+1
Попробуйте, например, сравнить количество интервалов для диапазонов длиной 35 и 36 значений – оно будет отличаться на 1, а у 36 и 48 – будет одинаковым, т.к. функция ЦЕЛОЕ() округляет до ближайшего меньшего целого (ЦЕЛОЕ(КОРЕНЬ(35))=5 , а ЦЕЛОЕ(КОРЕНЬ(36))=6) .
Если установить галочку напротив поля Парето (отсортированная гистограмма), то к таблице с частотами будет добавлена таблица с отсортированными по убыванию частотами.
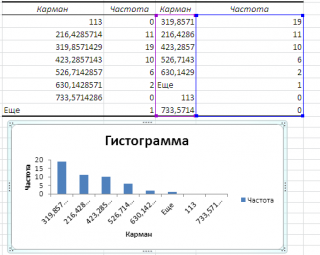
Если установить галочку напротив поля Интегральный процент, то к таблице с частотами будет добавлен столбец с нарастающим итогом в % от общего количества значений в массиве.
Если выбор количества интервалов или их диапазонов не устраивает, то можно в диалоговом окне указать нужный массив интервалов (если интервал карманов включает текстовый заголовок, то нужно установить галочку напротив поля Метка).
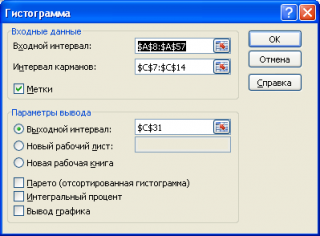
Для нашего набора данных установим размер кармана равным 100 и первый карман возьмем равным 150.
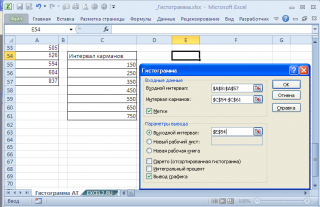
В результате получим практически такую же по форме гистограмму, что и раньше, но с более красивыми границами интервалов.
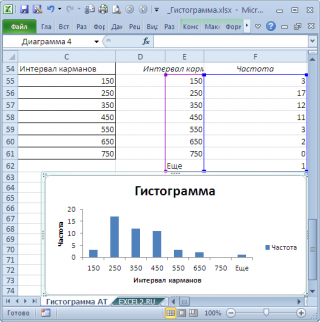
Как видно из рисунков выше, надстройка Пакет анализа не осуществляет никакого дополнительного форматирования диаграммы. Соответственно, вид такой гистограммы оставляет желать лучшего (столбцы диаграммы обычно располагают вплотную для непрерывных величин, кроме того подписи интервалов не информативны). О том, как придать диаграмме более презентабельный вид, покажем в следующем разделе при построении гистограммы с помощью функции ЧАСТОТА() без использовании надстройки Пакет анализа.
Построение гистограммы распределения без использования надстройки Пакет анализа
Порядок действий при построении гистограммы в этом случае следующий:
- определить количество интервалов у гистограммы;
- определить ширину интервала (с учетом округления);
- определить границу первого интервала;
- сформировать таблицу интервалов и рассчитать количество значений, попадающих в каждый интервал (частоту);
- построить гистограмму.
СОВЕТ: Часто рекомендуют, чтобы границы интервала были на один порядок точнее самих данных и оканчивались на 5. Например, если данные в массиве определены с точностью до десятых: 1,2; 2,3; 5,0; 6,1; 2,1, …, то границы интервалов должны быть округлены до сотых: 1,25-1,35; 1,35-1,45; …
Для небольших наборов данных вид гистограммы сильно зависит количества интервалов и их ширины. Это приводит к тому, что сам метод гистограмм, как инструмент описательной статистики, может быть применен только для наборов данных состоящих, как минимум, из 50, а лучше из 100 значений.
В наших расчетах для определения количества интервалов мы будем пользоваться формулой =ЦЕЛОЕ(КОРЕНЬ(n))+1 .
Примечание: Кроме использованного выше правила (число карманов = √n), используется ряд других эмпирических правил, например, правило Стёрджеса (Sturges): число карманов =1+log2(n). Это обусловлено тем, что например, для n=5000, количество интервалов по формуле √n будет равно 70, а правило Стёрджеса рекомендует более приемлемое количество – 13.
Расчет ширины интервала и таблица интервалов приведены в файле примера на листе Гистограмма . Для вычисления количества значений, попадающих в каждый интервал, использована формула массива на основе функции ЧАСТОТА() . О вводе этой функции см. статью Функция ЧАСТОТА() – Подсчет ЧИСЛОвых значений в MS EXCEL.
В MS EXCEL имеется диаграмма типа Гистограмма с группировкой, которая обычно используется для построения Гистограмм распределения.
В итоге можно добиться вот такого результата.
Примечание: О построении и настройке макета диаграмм см. статью Основы построения диаграмм в MS EXCEL.
Одной из разновидностей гистограмм является график накопленной частоты (cumulative frequency plot).
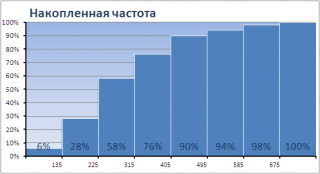
На этом графике каждый столбец представляет собой число значений исходного массива, меньших или равных правой границе соответствующего интервала. Это очень удобно, т.к., например, из графика сразу видно, что 90% значений (45 из 50) меньше чем 495.
СОВЕТ : О построении двумерной гистограммы см. статью Двумерная гистограмма в MS EXCEL.
Примечание: Альтернативой графику накопленной частоты может служить Кривая процентилей, которая рассмотрена в статье про Процентили.
Примечание: Когда количество значений в выборке недостаточно для построения полноценной гистограммы может быть полезна Блочная диаграмма (иногда она называется Диаграмма размаха или Ящик с усами).
Excel 2016 обзавелся новыми типами графиков. Причем, это не какие-нибудь дизайнерские новшества, а самые настоящие статистические диаграммы.
Так, «ящик с усами» применяется для анализа выборки. Диаграмма Парето пригодится при анализе вклада отдельных элементов в общую сумму. В этой заметке рассмотрим еще одну новую диаграмму из Excel 2016 – гистограмму частот.
На первый взгляд и в более ранних версиях Excel можно изобразить частоты с помощью диаграмм. Можно, но для этого предварительно необходимо числовые данные сгруппировать. То есть для каждой категории (интервала, группы, года и т.д.) нужно посчитать частоту. Теперь появилась возможность изобразить распределение данных буквально в один клик без предварительных расчетов и группировок.
Строится такая диаграмма в один клик. Выделяем ряд данных и нажимаем кнопку гистограммы частот.

Собственно, все. Тут же появляется соответствующая диаграмма.
Возникает вопрос: как Excel делит данные на интервалы? Справка Excel говорит, что с помощью формулы.
Количество интервалов получается достаточным для того, чтобы визуально прикинуть, каков характер распределения анализируемых данных.
Интервалы легко перестроить под свои потребности. Можно, например, задать нижнюю и верхнюю границу, за пределами которых данные будут объединены в один интервал.
При выборе опции выхода за нижнюю и верхнюю границы, судя по той же справке, их значения рассчитываются, как расстояние ±3σ от средней арифметической.
Однако рассчитываемые автоматически значения легко изменить в окне настроек.
Это был пример, когда данные разбиваются на интервалы. Такой вариант группировки установлен по умолчанию (см. окно параметров настройки оси выше).
Распределение частот можно получить и по имеющимся категориям (должен быть указан соответствующий столбец). Выбираем в настройках «По категориям» и получаем новые частоты.
Проведем эксперимент. С помощью функции СЛУЧМЕЖДУ смоделируем равномерно распределенную выборку в пределах, скажем, от 0 до 200. Пусть выборка состоит из 100 значений. Теперь изобразим гистограмму частот.
Как видно, частоты примерно одинаковы.
На предыдущем уроке по математической статистике (Занятие 1) мы разобрали дискретный вариационный ряд (Занятие 2), и сейчас на очереди интервальный. Его понятие, графическое представление (гистограмма и эмпирическая функция распределения), а также рациональные методы вычислений, как ручные, так и программные. В том числе будут рассмотрены задачи с достаточно большим количеством (100-200) вариант – что делать в таких случаях, как обработать большой массив данных.
Предпосылкой построения интервального вариационного ряда (ИВР) является тот факт, что исследуемая величина принимает слишком много различных значений. Зачастую ИВР появляется в результате измерения непрерывной характеристики изучаемых объектов. Типично – это время, масса, размеры и другие физические характеристики. Подходящие примеры встретились в первой же статье по матстату, вспоминаем Константина, который замерял время на лабораторной работе и Фёдора, который взвешивал помидоры.
Для изучения интервального вариационного ряда затруднительно либо невозможно применить тот же подход, что и для дискретного ряда. Это связано с тем, что ВСЕ варианты многих ИВР различны. И даже если встречаются совпадающие значения, например, 50 грамм и 50 грамм, то связано это с округлением, ибо полученные значения всё равно отличаются хоть какими-то микрограммами.
Поэтому для исследования ИВР используется другой подход, а именно, определяется интервал, в пределах которого варьируются значения, затем данный интервал делится на частичные интервалы, и по каждому интервалу подсчитываются частоты – количество вариант, которые в него попали.
Разберём всю кухню на конкретной задаче, и чтобы как-то разнообразить физику, я приведу пример с экономическим содержанием, кои десятками предлагают студентам экономических отделений. Деньги, строго говоря, дискретны, но если надо, непрерывны :), и по причине слишком большого разброса цен, для них целесообразно строить интервальный ряд:
По результатам исследования цены некоторого товара в различных торговых точках города, получены следующие данные (в некоторых денежных единицах): 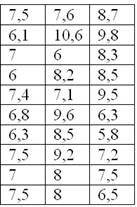
Требуется составить вариационный ряд распределения, построить гистограмму и полигон относительных частот + бонус – эмпирическую функцию распределения.
Такое обывательское исследование проводит каждый из нас, начиная с анализа цены на пакет молока вот это дожил в нескольких магазинах, и заканчивая ценами на недвижимость по гораздо бОльшей выборке. Что называется, не какие-то там унылые сантиметры.
Поэтому представьте свой любимый товар / услугу и наслаждайтесь решением🙂
Очевидно, что перед нами выборочная совокупность объемом 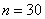 наблюдений (таблица 10*3), и вопрос номер один: какой ряд составлять – дискретный или интервальный? Смотрим на таблицу: среди предложенных цен есть одинаковые, но их разброс довольно велик, и поэтому здесь целесообразно провести интервальное разбиение. К тому же цены могут быть округлёнными.
наблюдений (таблица 10*3), и вопрос номер один: какой ряд составлять – дискретный или интервальный? Смотрим на таблицу: среди предложенных цен есть одинаковые, но их разброс довольно велик, и поэтому здесь целесообразно провести интервальное разбиение. К тому же цены могут быть округлёнными.
Начнём с экстремальной ситуации, когда у вас под рукой нет Экселя или другого подходящего программного обеспечения. Только ручка, карандаш, тетрадь и калькулятор.
Тактика действий похожа на исследование дискретного вариационного ряда. Сначала окидываем взглядом предложенные числа и определяем примерный интервал, в который вписываются эти значения. «Навскидку» все значения заключены в пределах от 5 до 11. Далее делим этот интервал на удобные подынтервалы, в данном случае напрашиваются промежутки единичной длины. Записываем их на черновик: 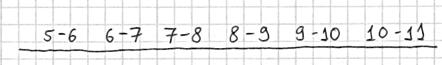
Теперь начинаем вычёркивать числа из исходного списка и записывать их в соответствующие колонки нашей импровизированной таблицы: 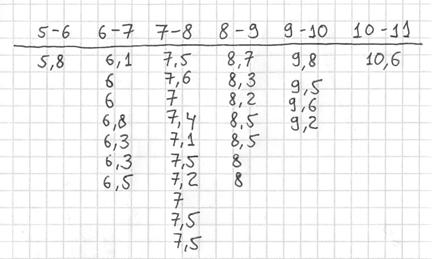
После этого находим самое маленькое число в левой колонке и самое большое значение – в правой. Тут даже ничего искать не пришлось, честное слово, не нарочно получилось:)
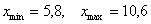 ден. ед. – хорошим тоном считается указывать размерность.
ден. ед. – хорошим тоном считается указывать размерность.
Вычислим размах вариации:
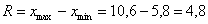 ден. ед. – длина общего интервала, в пределах которого варьируется цена.
ден. ед. – длина общего интервала, в пределах которого варьируется цена.
Теперь его нужно разбить на частичные интервалы. Сколько интервалов рассмотреть? По умолчанию на этот счёт существует формула Стерджеса:
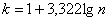 , где
, где 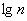 – десятичный логарифм* от объёма выборки и
– десятичный логарифм* от объёма выборки и 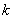 – оптимальное количество интервалов, при этом результат округляют до ближайшего левого целого значения.
– оптимальное количество интервалов, при этом результат округляют до ближайшего левого целого значения.
* есть на любом более или менее приличном калькуляторе
В нашем случае получаем:
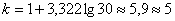 интервалов.
интервалов.
Следует отметить, что правило Стерджеса носит рекомендательный, но не обязательный характер. Нередко в условии задачи прямо сказано, на какое количество интервалов нужно проводить разбиение (на 4, 5, 6, 10 и т.д.), и тогда следует придерживаться именно этого указания.
Длины частичных интервалов могут быть различны, но в большинстве случаев использует равноинтервальную группировку:
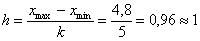 – длина частичного интервала. В принципе, здесь можно было не округлять и использовать длину 0,96, но удобнее, ясен день, 1.
– длина частичного интервала. В принципе, здесь можно было не округлять и использовать длину 0,96, но удобнее, ясен день, 1.
И коль скоро мы прибавили 0,04, то по 5 частичным интервалам у нас получается «перебор»: 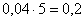 . Посему от самой малой варианты
. Посему от самой малой варианты 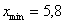 отмеряем влево 0,1 влево (половину «перебора») и к значению 5,7 начинаем прибавлять по
отмеряем влево 0,1 влево (половину «перебора») и к значению 5,7 начинаем прибавлять по 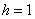 , получая тем самым частичные интервалы. При этом сразу рассчитываем их середины
, получая тем самым частичные интервалы. При этом сразу рассчитываем их середины 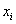 (например,
(например, 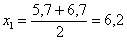 ) – они требуются почти во всех тематических задачах:
) – они требуются почти во всех тематических задачах: 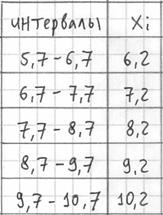
– убеждаемся в том, что самая большая варианта 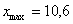 вписалась в последний частичный интервал и отстоит от его правого конца на 0,1.
вписалась в последний частичный интервал и отстоит от его правого конца на 0,1.
Далее подсчитываем частоты по каждому интервалу. Для этого в черновой «таблице» обводим значения, попавшие в тот или иной интервал, подсчитываем их количество и вычёркиваем: 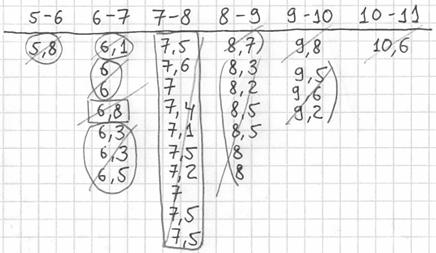
Так, значения из 1-го интервала я обвёл овалами (7 штук) и вычеркнул, значения из 2-го интервала – прямоугольниками (11 штук) и вычеркнул и так далее.
Правило: если варианта попадает на «стык» интервалов, то её следует относить в правый интервал. У нас такая варианта встретилась одна: 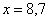 – и её нужно причислить к интервалу
– и её нужно причислить к интервалу 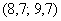 .
.
В результате получаем интервальный вариационный ряд, при этом обязательно убеждаемся в том, что ничего не потеряно: 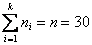 , и, кроме того, рассчитываем относительные частоты
, и, кроме того, рассчитываем относительные частоты 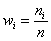 по каждому интервалу, которые уместно округлить до двух знаков после запятой:
по каждому интервалу, которые уместно округлить до двух знаков после запятой: 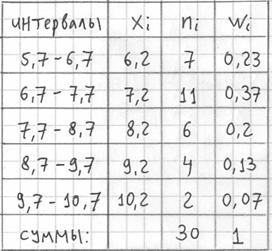
Дело за чертежами. Для ИВР чаще всего требуется построить гистограмму.
Гистограмма относительных частот – это фигура, состоящая из прямоугольников, ширина которых равна длинам частичных интервалов, а высота – соответствующим относительным частотам: 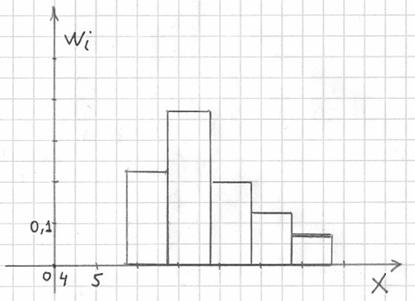
При этом вполне допустимо использовать нестандартную шкалу по оси абсцисс, в данном случае я начал нумерацию с четырёх.
Площадь гистограммы равна единице, и это статистический аналог функции плотности распределения непрерывной случайной величины. Построенный чертёж даёт наглядное и весьма точное представление о распределении цен на ботинки по всей генеральной совокупности. Но это при условии, что выборка представительна.
Вместе с гистограммой нередко требуют построить полигон. Без проблем, полигон относительных частот – это ломаная, соединяющая соседние точки 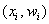 , где
, где 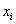 – середины интервалов:
– середины интервалов: 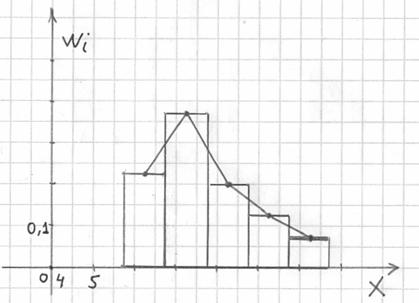
Большим достоинством приведённого решения является тот факт, что многие вычисления здесь устные, а если вы помните, как делить «столбиком», то можно обойтись даже без калькулятора. Вот она где притаилась, смерть Терминатора 🙂 😉
Автоматизируем решение в Экселе:
 Как составить ИВР и представить его графически? (Ютуб)
Как составить ИВР и представить его графически? (Ютуб)
И бонус – эмпирическая функция распределения. Она определяется точно так же, как в дискретном случае:
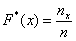 , где
, где 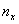 – количество вариант СТРОГО МЕНЬШИХ, чем «икс», который «пробегает» все значения от «минус» до «плюс» бесконечности.
– количество вариант СТРОГО МЕНЬШИХ, чем «икс», который «пробегает» все значения от «минус» до «плюс» бесконечности.
Но вот построить её для интервального ряда намного проще. Находим накопленные относительные частоты: 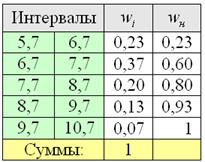
И строим кусочно-ломаную линию, с промежуточными точками  , где
, где  – правые концы интервалов, а
– правые концы интервалов, а  – относительная частота, которая успела накопиться на всех «пройденных» интервалах:
– относительная частота, которая успела накопиться на всех «пройденных» интервалах: 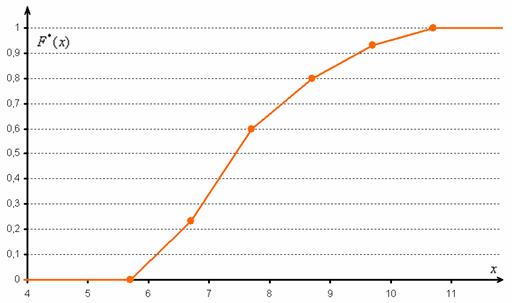
При этом 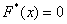 если
если 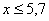 и
и 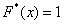 если
если 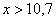 .
.
Напоминаю, что данная функция не убывает, принимает значения из промежутка 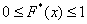 и, кроме того, для ИВР она ещё и непрерывна.
и, кроме того, для ИВР она ещё и непрерывна.
Эмпирическая функция распределения является аналогом функции распределения НСВ и приближает теоретическую функцию 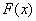 , которую теоретически, а иногда и практически можно построить по всей генеральной совокупности.
, которую теоретически, а иногда и практически можно построить по всей генеральной совокупности.
Помимо перечисленных графиков, вариационные ряды также можно представить с помощью кумуляты и огивы частот либо относительных частот, но в классическом учебном курсе эта дичь редкая, и поэтому о ней буквально пару абзацев:
Кумулята – это ломаная, соединяющая точки:
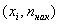 * либо
* либо 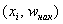 – для дискретного вариационного ряда;
– для дискретного вариационного ряда;
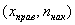 либо
либо 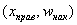 – для интервального вариационного ряда.
– для интервального вариационного ряда.
* 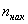 – накопленные «обычные» частоты
– накопленные «обычные» частоты
В последнем случае кумулята относительных частот 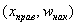 представляет собой «главный кусок» недавно построенной эмпирической функции распределения.
представляет собой «главный кусок» недавно построенной эмпирической функции распределения.
Огива – это обратная функция по отношению к кумуляте – здесь варианты откладываются по оси ординат, а накопленные частоты либо относительные частоты – по оси абсцисс.
С построением данных линий, думаю, проблем быть не должно, чего не скажешь о другой проблеме. Хорошо, если в вашей задаче всего лишь 20-30-50 вариант, но что делать, если их 100-200 и больше? В моей практике встречались десятки таких задач, и ручной подсчёт здесь уже не торт. Считаю нужным снять небольшое видео:
Как быстро составить ИВР при большом объёме выборки? (Ютуб)
Ну, теперь вы монстры 8-го уровня 🙂
Но не всё так сурово. В большинстве задач вам предложат готовый вариационный ряд, и на счёт молока, то, конечно, была шутка:
Выборочная проверка партии чая, поступившего в торговую сеть, дала следующие результаты: 
Требуется построить гистограмму и полигон относительных частот, эмпирическую функцию распределения
Проверяем свои навыки работы в Экселе! (исходные числа и краткая инструкция прилагается) И на всякий случай краткое решение для сверки в конце урока.
Что ещё важного по теме? Время от времени встречаются ИВР с открытыми крайними интервалами, например: 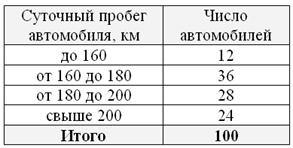
В таких случаях, что убийственно логично, интервалы «закрывают». Обычно поступают так: сначала смотрим на средние интервалы и выясняем длину частичного интервала: 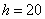 км. И для дальнейшего решения можно считать, что крайние интервалы имеют такую же длину: от 140 до 160 и от 200 до 220 км. Тоже логично. Но уже не убийственно:)
км. И для дальнейшего решения можно считать, что крайние интервалы имеют такую же длину: от 140 до 160 и от 200 до 220 км. Тоже логично. Но уже не убийственно:)
Ну вот, пожалуй, и вся практически важная информация по ИВР.
На очереди числовые характеристики вариационных рядов и начнём мы с их центральных характеристик, а именно – Моды, медианы и средней.
До скорых встреч!
Решения и ответы:
Пример 7. Решение: заполним расчётную таблицу 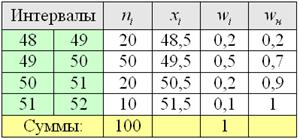
Построим гистограмму и полигон относительных частот: 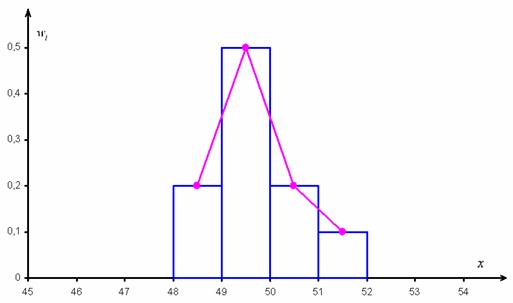
Построим эмпирическую функцию распределения: 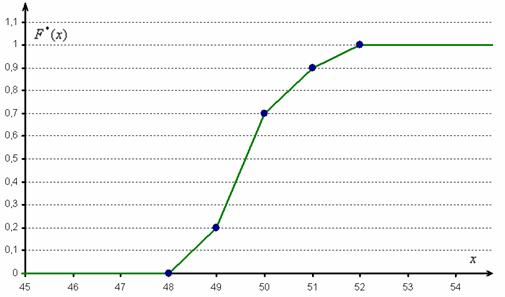
Автор: Емелин Александр
(Переход на главную страницу)
 Профессиональная помощь по любому предмету – Zaochnik.com
Профессиональная помощь по любому предмету – Zaochnik.com