Содержание
Распознавание по голосу — одна из форм биометрической аутентификации, позволяющая идентифицировать личность человека по совокупности уникальных характеристик голоса. Относится к динамическим методам биометрии. Однако, поскольку голос человека может меняться в зависимости от возраста, эмоционального состояния, здоровья, гормонального фона и целого ряда других факторов, не является абсолютно точным [1] . По мере развития звукозаписывающей и воспроизводящей техники, технология распознавания применяется с различным успехом в сфере защиты информации, охраны и систем доступа, криминалистике.
Содержание
История [ править | править код ]
Работы по распознаванию речи берут начало с середины прошлого века. Первая система была создана в начале 1950 годов: её разработчики поставили перед собой задачу распознавания цифр. Разработанная система могла идентифицировать цифры, но сказанные одним голосом, как, например, система «Audrey» компании Bell Laboratories. Она работала на основе определения форманты в спектре мощности каждого речевого отрывка [2] . В общих чертах система состояла из трёх главных частей: анализаторов и квантователей, шаблонов согласователей сети и, наконец, датчиков. Создано было, соответственно, на элементной базе различных частотных фильтров, переключателей, так же в составе датчиков были газонаполненные трубки [3] [ нет в источнике ] .
К концу десятилетия появились системы, распознающие гласные независимо от диктора [4] . В 70-х годах начали использоваться новые методы, позволившие добиться более совершенных результатов — метод динамического программирования [5] и метод линейного предсказания (Linear Predictive Coding — LPC). В вышеупомянутой компании, Bell Laboratories были созданы системы, использующие именно эти методы [6] . В 80-х годах следующим шагом в развитии систем распознавания голоса стало использование скрытых марковский моделей (H >[7] . В конце 80-х также стали применяться методы искусственных нейронных сетей (Artificial Neural Network — ANN) [8] . В 1987 году на рынке появились куклы Worlds of Wonder’s Julie doll, которые были способны понимать голос [7] . А ещё через 10 лет Dragon Systems выпустила программу «NaturallySpeaking 1.0» [9] .
Надёжность [ править | править код ]
Основными источниками ошибок распознавания голоса являются:
- среда записи (уровень и тип шума среды, уровень реверберации);
- эффект представления (длительность речи, психофизиологическое состояние говорящего (болезнь, эмоциональное состояние и т. п.), язык речевого сообщения, акцент, громкость речи);
- низкое качество канала (помехи, искажения микрофона и канала передачи, вид кодирования в канале и т. д.) [10] .
Распознавание пола можно выделить в отдельный тип задач, который довольно успешно решается — при больших объёмах начальных данных пол определяется практически безошибочно, а на коротких отрывках вроде ударного гласного звука вероятность ошибки — 5,3 % для мужчин и 3,1 % для женщин [11] .
Также рассматривалась проблема имитации голоса. Исследования France Telecom показали, что профессиональная имитация голоса практически не увеличивает вероятность ошибки определения личности — имитаторы подделывают голос лишь внешне, подчеркивая особенности речи, но базовую канву голоса подделать не способны. Даже голоса близких родственников, близнецов будет иметь различие, как минимум, в динамике управления [11] . Но с развитием компьютерных технологий возникла новая проблема, требующая использования новых способов анализа, — трансформация голоса, которая увеличивает вероятность ошибки до 50 % [11] .
Для описания надёжности системы есть два используемых критерия: FRR (False Rejection Rate) — вероятность ложного отказа в доступе (ошибка первого рода) и FAR (False Acceptance Rate) — вероятность ложного допуска, когда система ошибочно опознаёт чужого как своего (ошибка второго рода). Также иногда системы распознавания характеризуются таким параметром, как EER (Equal Error Rates), представляющим точку совпадения вероятностей FRR и FAR. Чем надежней система, тем более низкий EER имеет [12] .
Значения ошибок идентификации для различных биометрических модальностей [10]
| Биометрический признак | Тест | Условия тестирования | FRR % | FAR % |
|---|---|---|---|---|
| Отпечатки пальцев | FVC 2006 | Неоднородная популяция (включает работников ручного труда и пожилых людей) | 2,2 | 2,2 |
| Лицо | MBE 2010 | Полицейская база фотографий |
База фотографий с документов
Применение [ править | править код ]
Распознавание можно разделить на два главных направления: идентификацию и верификацию. В первом случае система должна самостоятельно установить личность пользователя по голосу; во втором случае система должна подтвердить или опровергнуть идентификатор, который предъявляет пользователь [11] . Определение исследуемого диктора состоит в попарном сравнении голосовых моделей, которые учитывают индивидуальные особенности речи каждого диктора. Таким образом, нам необходимо для начала собрать достаточно большую базу данных. А по результатам этого сравнения может быть сформирован список фонограмм, являющихся с некоторой вероятностью речью интересующего нас пользователя [11] .
Хотя распознавание по голосу не может гарантировать стопроцентную правильность результата, оно может довольно эффективно использоваться в таких областях, как криминалистика и судебная экспертиза; разведка; антитеррористический мониторинг; безопасность; банковское дело и так далее [11] .
Анализ [ править | править код ]
Весь процесс обработки речевого сигнала можно разбить на несколько главных этапов:
- предобработка сигнала;
- выделение критериев;
- распознавание диктора.
Каждый этап представляет алгоритм или некоторую совокупность алгоритмов, что в итоге даёт требуемый результат [13] .
Главные черты голоса формируются тремя главными свойствами: механикой колебаний голосовых складок, анатомией речевого тракта и системой управления артикуляцией. Кроме этого, иногда есть возможность пользоваться словарём говорящего, его оборотами речи [11] . Главные признаки, по которым принимается решение о личности диктора, формируются с учётом всех факторов процесса речеобразования: голосового источника, резонансных частот речевого тракта и их затуханий, а также динамикой управления артикуляцией. Если рассмотреть источники подробнее, то в свойства голосового источника входят: средняя частота основного тона, контур и флюктуации частоты основного тона и форма импульса возбуждения. Спектральные характеристики речевого тракта описываются огибающей спектра и его средним наклоном, формантными частотами, долговременным спектром или кепстром. Кроме того, рассматривается также длительность слов, ритм (распределение ударений), уровень сигнала, частота и длительность пауз [14] . Чтобы определить эти характеристики приходится использовать довольно сложные алгоритмы, но так как, к примеру, погрешность формантных частот довольно велика, для упрощения используются коэффициенты кепстра, вычисляемые по огибающей спектра или передаточная функция речевого тракта, найденная методом линейного предсказания. Кроме упомянутых коэффициентов кепстра также используются их первые и вторые разности по времени [11] . Этот метод был впервые предложен в работах Дэвиса и Мермельштейна [15] .
Кепстральный анализ [ править | править код ]
В работах по распознаванию голоса наиболее популярен метод кепстрального преобразования спектра речевых сигналов [11] . Схема метода такова: на интервале времени в 10 — 20 мс вычисляется текущий спектр мощности, а затем применяется обратное преобразование Фурье от логарифма этого спектра (кепстр) и находятся коэффициенты: c n = 1 Θ ∫ 0 Θ ∣ S ( j , ω , t ) ∣ 2 exp − j n ω Ω d ω <displaystyle c_ , Ω = 2 2 π Θ , Θ <displaystyle Omega =2<frac <2pi ><Theta >>,Theta > – верхняя частота в спектре речевого сигнала, ∣ S ( j , ω , t ) ∣ 2 <displaystyle <mid S(j,omega ,t)mid >^<2>> – спектр мощности. Число кепстральных коэффициентов n зависит от требуемого сглаживания спектра, и находится в пределах от 20 до 40. Если используется гребёнка полосовых фильтров, то коэффициенты дискретного кепстрального преобразования вычисляются как c n = ∑ m = 1 N log Y ( m ) 2 cos π n M ( m − 1 2 ) ) <displaystyle c_, где Y(m) — выходной сигнал m-го фильтра, c n <displaystyle c_— n-й коэффициент кепстра.
, Ω = 2 2 π Θ , Θ <displaystyle Omega =2<frac <2pi ><Theta >>,Theta > – верхняя частота в спектре речевого сигнала, ∣ S ( j , ω , t ) ∣ 2 <displaystyle <mid S(j,omega ,t)mid >^<2>> – спектр мощности. Число кепстральных коэффициентов n зависит от требуемого сглаживания спектра, и находится в пределах от 20 до 40. Если используется гребёнка полосовых фильтров, то коэффициенты дискретного кепстрального преобразования вычисляются как c n = ∑ m = 1 N log Y ( m ) 2 cos π n M ( m − 1 2 ) ) <displaystyle c_, где Y(m) — выходной сигнал m-го фильтра, c n <displaystyle c_— n-й коэффициент кепстра.
Свойства слуха учитываются путём нелинейного преобразования шкалы частот, обычно в шкале мел [11] . Эта шкала формируется исходя из присутствия в слухе так называемых критических полос, таких, что сигналы любой частоты в пределах критической полосы неразличимы. Шкала мел вычисляется как M ( f ) = 1125 ln ( 1 + f 700 ) <displaystyle M(f)=1125ln <(1+<frac , где f — частота в Гц, M — частота в мелах. Либо используется другая шкала — барк, такая, что разность между двумя частотами, равная критической полосе, равна 1 барк. Частота B вычисляется как B = 13 a r c t g ( 0 , 00076 f ) + 3 , 5 a r c t g f 7500 <displaystyle B=13operatorname > +3,5operatorname. Найденные коэффициенты в литературе иногда обозначаются как MFCC — Mel Frequiency Cepstral Coefficients. Их число лежит в диапазоне от 10 до 30. Использование первых и вторых разностей по времени кепстральных коэффициентов втрое увеличивает размерность пространства принятия решений, но улучшает эффективность распознавания диктора [11] .
Кепстр описывает форму огибающей спектра сигнала, на которую влияют и свойства источника возбуждения, и особенности речевого тракта. В экспериментах было установлено, что огибающая спектра сильно влияет на узнаваемость голоса. Поэтому использование различных способов анализа огибающей спектра в целях распознавания голоса вполне оправдано [11] .
Методы [ править | править код ]
Так как во многих системах используется пространство кепстральных коэффициентов, их первых и вторых разностей, большое внимание уделяется построению решающих правил. Наиболее популярны методы аппроксимации плотности вероятности в пространстве признаков взвешенной смесью нормальных распределений (GMM — Gauss Mixture Models), метод опорных векторов (SVM — Support Vector Machines), метод скрытых Марковских моделей (HMM — H >[11] .
Метод GMM следует из теоремы о том, что любая функция плотности вероятности может быть представлена как взвешенная сумма нормальных распределений:
p ( x | λ ) = ∑ j = 1 k ω j ϕ ( χ , Θ j ) <displaystyle p(x|lambda )=sum _^; λ <displaystyle lambda > — модель диктора;k — количество компонентов модели; ω j <displaystyle <omega _— веса компонентов такие, что ∑ j = 1 n ω j = 1. <displaystyle sum _^ϕ ( χ , Θ j ) <displaystyle phi (chi ,Theta _– функция распределения многомерного аргумента χ , Θ j <displaystyle chi ,Theta _[11] . ϕ ( χ , Θ j ) = p ( χ ∣ μ j , R j ) = 1 ( 2 π ) n 2 ∣ R j ∣ 1 2 exp − 1 ( χ − μ j ) T R j − 1 ( χ − μ j ) 2 <displaystyle phi (chi ,Theta _, ω j <displaystyle omega _– её вес, k — количество компонент в смеси. Здесь n — размерность пространства признаков, μ j ∈ R n <displaystyle mu _— вектор математического ожидания j-й компоненты смеси, R j ∈ R n × n <displaystyle R_– ковариационная матрица.
Очень часто в системах с этой моделью используется диагональная ковариационнная матрица. Она может использоваться для всех компонент модели или даже для всех моделей. Чтобы найти матрицу ковариации, веса, векторы средних часто используют EM-алгоритм. На входе имеем обучающую последовательность векторов X = 1, . . . , xT > . Параметры модели инициализируются начальными значениями и затем на каждой итерации алгоритма происходит переоценка параметров. Для определения начальных параметров обычно используют алгоритм кластеризации такой, как алгоритм К-средних. После того как произошло разбиение множества обучающих векторов на M кластеров, параметры модели могут быть определены так: начальные значения μ j <displaystyle mu _совпадают с центрами кластеров, матрицы ковариации рассчитываются на основе попавших в данный кластер векторов, веса компонентов определяются долей векторов данного кластера среди общего количества обучающих векторов.
Переоценка параметров происходит по следующим формулам:
- вычисление апостериорных вероятностей (Estimation-step): p ( i | χ t , λ ) = ω i ϕ ( χ t , Θ i ) ∑ j = 1 k ω j ϕ ( χ t , Θ j ) <displaystyle <displaystyle p(i|chi _
,lambda )=<frac <omega _phi (chi _ ,Theta _)><sum _^ <omega _ phi (chi _ ,Theta _ )>>>>>  .
.
- вычисление новых параметров модели (Maximization-step): ω j = ∑ j = 1 k p ( i | χ j , λ ) T <displaystyle omega _
=<frac <sum _^ ,lambda )>> >> ; μ i = ∑ t = 1 n p ( i | χ t , λ ) χ t ∑ t = 1 n p ( i | χ t , λ ) <displaystyle <mu _=<frac <sum _^,lambda )chi _ >><sum _^ ,lambda )>>>>> ; R i = ∑ t = 1 n p ( i | χ t , λ ) ( χ t − μ i ) ( χ t − μ i ) T ∑ t = 1 n p ( i | χ t , λ ) <displaystyle =<frac <sum _^,lambda )(chi _ -mu _)<(chi _ -mu _)>^ >><sum _^ ,lambda )>>>>> . Шаги повторяются, пока не будет достигнуто схождение параметров [16] .
GMM можно также назвать продолжением метода векторного квантования (метод центроидов). При его использовании создаётся кодовая книга для непересекающихся областей в пространстве признаков (часто с использованием кластеризации методом K-means). Векторное квантование является простейшей моделью в системах распознавания, независимых от контекста [11] .
Метод опорных векторов (SVM) строит гиперплоскость в многомерном пространстве, разделяющую два класса — параметров целевого диктора и параметров дикторов из референтной базы. Гиперплоскость вычисляется c помощью опорных векторов — выбранных особым образом. Будет выполняться нелинейное преобразование пространства измеренных параметров в некоторое пространство признаков более высокой размерности, так как разделяющая поверхность может и не соответствовать гиперплоскости. Разделяющая поверхность в гиперплоскости строится методом опорных векторов, если выполняется условие линейной разделимости в новом пространстве признаков. Таким образом успех применения SMM зависит от подобранного нелинейного преобразования в каждом конкретном случае. Метод опорных векторов применяется часто с методом GMM или HMМ. Обычно для коротких фраз длительностью в несколько секунд для контестно-зависимого подхода лучше применяются фонемно-зависимые HMM [11] .
Популярность [ править | править код ]
По информации консалтинговой компании International Biometric Group из Нью-Йорка, наиболее распространённой технологией является сканирование отпечатков пальцев. Отмечается, что из 127 млн долларов, вырученных от продажи биометрических устройств, 44 % приходится на дактилоскопические сканеры. Системы распознавания черт лица занимают второе место по уровню спроса, который составляет 14 %, далее следуют устройства распознавания по форме ладони (13 %), по голосу (10 %) и радужной оболочке глаза (8 %). Устройства верификации подписи в этом списке составляют 2 %. Одни из самых известных производителей на рынке голосовой биометрии — Nuance Communications, SpeechWorks, VeriVoice [17] .
В феврале 2016 года The Telegraph опубликовала статью, в которой сообщается, что клиенты британского банка HSBC смогут получать доступ к счетам и проводить транзакции с помощью идентификации по голосу. Переход должен был состояться в начале лета [18] .
В нашем мире все чаще проявляется интерес к технологиям идентификации человеческого голоса. С одной стороны это объясняется реализацией высокопроизводительных систем которые могут считать сложные сигналы к примеру голоса. Методы распознавания личности по голосу есть с тех пор, как человек научился говорить. Плюсы и минусы нам известны уже. Плюсы такого метода это удобство в применении. На сегодня более 20 компаний могут предоставляют свои продукты с реализацией такого метода аутентификации в информационную систему. К примеру компания Keyware Technologies реализует продукцию с вероятностной ошибкой в 2-5%. такая технология отлично реализуется с помощью коммутируемой телефонной сетью. Основная проблема, которая связанна с таким подходом — это точность идентификации. Голос создается из комбинаций поведенческих и физиологических факторов. На сегодня идентификация по голосу реализована для управление доступом в помещения, где объективная оценка степени безопасности не критическая. Но к примеру человек с болезнью горла или простудой испытает трудности с такой системой.
Технология распознавания голоса — возможно самое практичное решения для множества приложений. такие системы анализируют характеристики уже после оцифровыванния, смотрят высоту, тон и ритм. Схема ввода голосовых сообщений показана на рис.1. Несмотря на снижение надежности в плане распознавания с наличием шумов, это все равно выгодное экономическое решение, так как звуковые карты и микрофоны уже давно прописаны в сети.

Есть множество разных микрофонов, но принцип работы у них один. звуковая волна ударяется об мембрану, где колебания мембраны передаются на упругий элемент который преобразует колебания в электрический сигнал. Сигнал усиливается и подается на вход звуковой карты. Звуковая карта это аналого-цифровой преобразователь. Основные параметры это разрядность кодирования и частота дискретизации. Данные параметры на прямую влияют на качество записи, а в следствии и на размер самой записи. Системы идентификации голоса работает по следующей схеме:
- Создается регистрация пользователя и делается расчет шаблона.
- Выбираются временные диапазоны речевого потока для анализа.
- Реализуется первичная обработка сигнала.
- Считаются первичные параметры.
- Создается отпечаток-шаблон голоса.
- Сравниваются шаблон и другие шаблоны уже имеющийся в базе.
При регистрации пользователь вводит свой идентификатор, к примеру ФИО и говорит несколько раз ключевую фразу. После первой обработки фрагменты сравниваются, и вычисляются сходства для отпечатка.
При выборе участков фрагментов, применяют разные способы. Можно использовать весь речевой поток исключая паузы. Можно же выбрать фрагменты где самые мощные звуки, так как там вероятность шумов самая маленькая. Также можно выбирать гласные звуки, так как по ним можно определить характер произношения и тд.
На рис.2. показа вероятность присутствия определенных особенности голоса личности в 18 фонемах.

В процессе первой обработки сигнала идет анализ спектральных параметров речи. Базовой процедурой есть узкополосная фильтрация сигнала и восстановление огибающей. При произношении контрольной фразы сигнал приводится к единому масштабу амплитуд засчет усилителя. Первичные параметры сигнала имеют свойства:
- отражения индивидуальности диктора
- не зависеть от шумов
- легко выделяемыми из сигнала
- быть независимыми к физическому и эмоциональному стану диктора
- мало поддаваться имитации
Первичные параметры могут использовать АЧХ, фон, расстояние между обертонами, форманты, длительность отдельных звуков и тд. При произношении паузка между звуками может меняться в пределах 10 — 50%. Для компенсации такой нестабильности можно использовать следующие способы:
- Сжатие или растяжение отдельных участков.
- Выделение центра звуковой области, тогда измерения вокруг центра не играют сильную роль.
Недостатком таких систем также есть то, что тайную фразу сложно сохранить в тайне. Так как при произношении фразы ее можно записать разными радиозаписывающими устройствами. Голосовой шаблон занимает примерно 2-5 Кбайт, а фраза длится не дольше 2-3 секунд.
Содержание статьи
Характеристики голоса
В первую очередь голос определяется его высотой. Высота — это основная частота звука, вокруг которой строятся все движения голосовых связок. Эту частоту легко почувствовать на слух: у кого-то голос выше, звонче, а у кого-то ниже, басовитее.
Другой важный параметр голоса — это его сила, количество энергии, которую человек вкладывает в произношение. От силы голоса зависит его громкость, насыщенность.
Еще одна характеристика — то, как голос переходит от одного звука к другому. Этот параметр наиболее сложный для понимания и для восприятия на слух, хотя и самый точный — как и отпечаток пальца.
Предобработка звука
Человеческий голос — это не одинокая волна, это сумма множества отдельных частот, создаваемых голосовыми связками, а также их гармоники. Из-за этого в обработке сырых данных волны тяжело найти закономерности голоса.
Нам на помощь придет преобразование Фурье — математический способ описать одну сложную звуковую волну спектрограммой, то есть набором множества частот и амплитуд. Эта спектрограмма содержит всю ключевую информацию о звуке: так мы узнаем, какие в исходном голосе содержатся частоты.
Но преобразование Фурье — математическая функция, которая нацелена на идеальный, неменяющийся звуковой сигнал, поэтому она требует практической адаптации. Так что, вместо того чтобы выделять частоты из всей записи сразу, эту запись мы поделим на небольшие отрезки, в течение которых звук не будет меняться. И применим преобразование к каждому из кусочков.
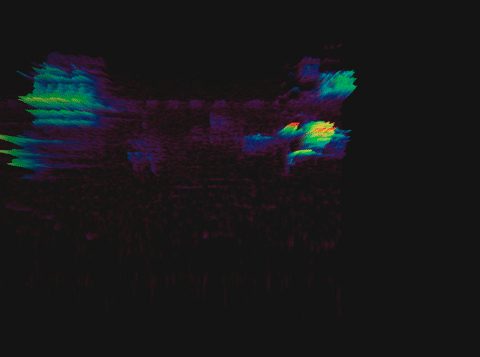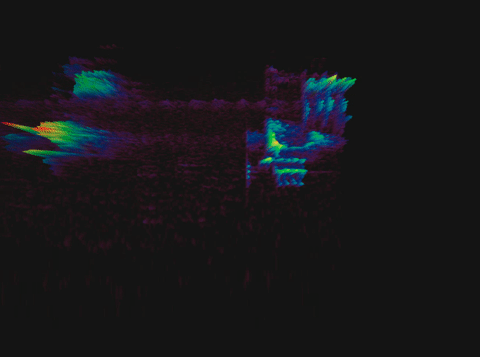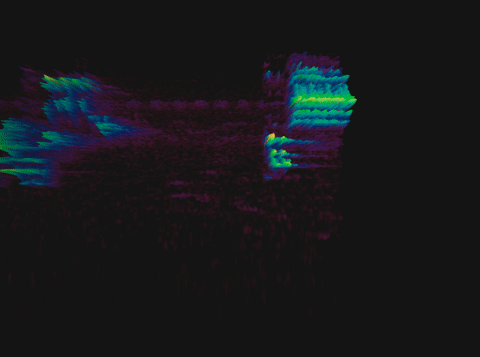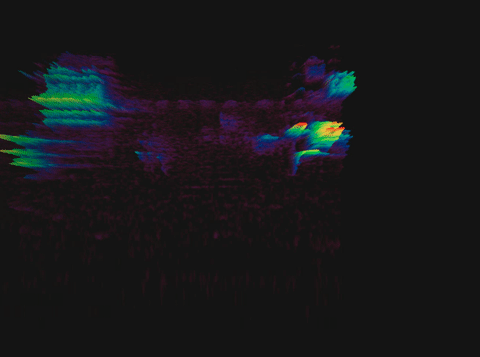 Спектрограмма пения птицы
Спектрограмма пения птицы
Выбрать длительность блока несложно: в среднем один слог человек произносит за 70–80 мс, а интонационно выделенный вдвое дольше — 100–150 мс. Подробнее об этом можно почитать в исследовании.
Следующий шаг — посчитать спектрограмму второго порядка, то есть спектрограмму от спектрограммы. Это нужно сделать, поскольку спектрограмма, помимо основных частот, также содержит гармоники, которые не очень удобны для анализа: они дублируют информацию. Расположены эти гармоники на равном друг от друга расстоянии, единственное их различие — уменьшение амплитуды.
Давай посмотрим, как выглядит спектр монотонного звука. Начнем с волны — синусоиды, которую издает, например, проводной телефон при наборе номера.
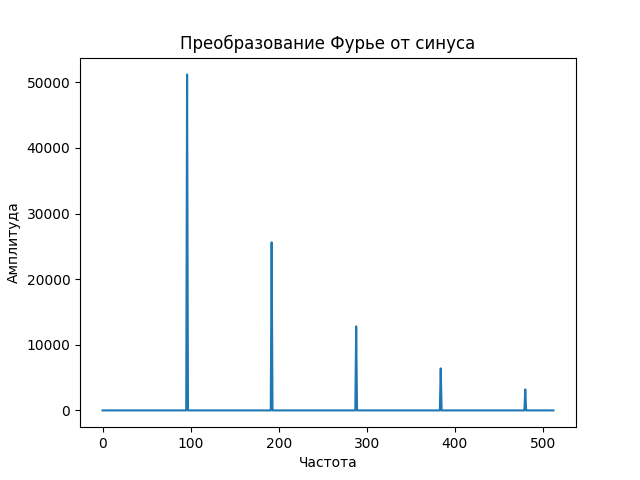
Видно, что, кроме основного пика, на самом деле представляющего сигнал, есть меньшие пики, гармоники, которые полезной информации не несут. Именно поэтому, прежде чем получать спектрограмму второго порядка, первую спектрограмму логарифмируют, чем получают пики схожего размера.
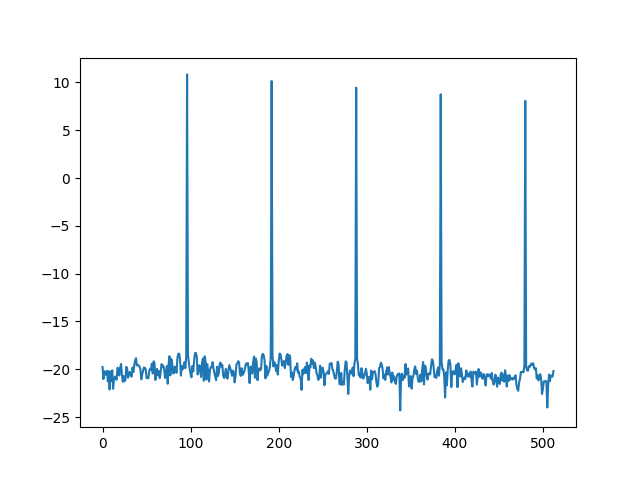 Логарифм спектрограммы синуса
Логарифм спектрограммы синуса
Теперь, если мы будем искать спектрограмму второго порядка, или, как она была названа, «кепстр» (анаграмма слова «спектр»), мы получим во много раз более приличную картинку, которая полностью, одним пиком, отображает нашу изначальную монотонную волну.
 Кепстр
Кепстр
Одна из самых полезных особенностей нашего слуха — его нелинейная природа по отношению к восприятию частот. Путем долгих экспериментов ученые выяснили, что эту закономерность можно не только легко вывести, но и легко использовать.
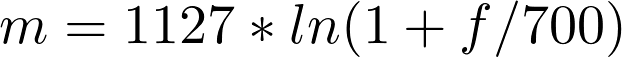 Зависимость мела от герца
Зависимость мела от герца
Эту новую величину назвали мел, и она отлично отражает способность человека распознавать разные частоты — чем выше частота звука, тем сложнее ее различить.
 График перевода герца в мелы
График перевода герца в мелы
Теперь попробуем применить все это на практике.
Идентификация с использованием MFCC
Мы можем взять длительную запись голоса человека, посчитать кепстр для каждого маленького участка и получить уникальный отпечаток голоса в каждый момент времени. Но этот отпечаток слишком большой для хранения и анализа — он зависит от выбранной длины блока и может доходить до двух тысяч чисел на каждые 100 мс. Поэтому из такого многообразия необходимо извлечь определенное количество признаков. С этим нам поможет мел-шкала.
Мы можем выбрать определенные «участки слышимости», на которых просуммируем все сигналы, причем количество этих участков равно количеству необходимых признаков, а длины и границы участков зависят от мел-шкалы.
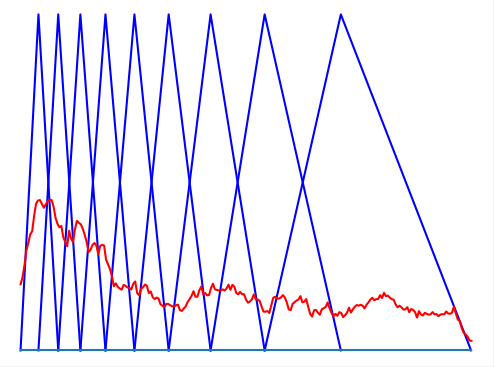 Вычисление мел-частотных кепстральных коэффициентов
Вычисление мел-частотных кепстральных коэффициентов
Вот мы и познакомились с мел-частотными кепстральными коэффициентами (MFCC). Количество признаков может быть произвольным, но чаще всего варьируется от 20 до 40.
Эти коэффициенты отлично отражают каждый «частотный блок» голоса в каждый момент времени, а значит, если обобщить время, просуммировав коэффициенты всех блоков, мы сможем получить голосовой отпечаток человека.
Тестирование метода
Давай скачаем несколько записей видео с YouTube, из которых извлечем голос для наших экспериментов. Нам нужен чистый звук без шумов. Я выбрал канал TED Talks.
Скачаем несколько видеозаписей любым удобным способом, например с помощью утилиты youtube-dl. Она доступна через pip или через официальный репозиторий Ubuntu или Debian. Я скачал три видеозаписи выступлений: двух женщин и одного мужчины.
Затем преобразуем видео в аудио, создаем несколько кусков разной длины без музыки или аплодисментов.
Теперь разберемся с программой на Python 3. Нам понадобятся библиотеки numpy для вычислений и librosa для обработки звука, которые можно установить с помощью pip . Для твоего удобства все сложные вычисления коэффициентов упаковали в одну функцию librosa.feature.mfcc . Загрузим звуковую дорожку и извлечем характеристики голоса.
Продолжение доступно только участникам
Вариант 1. Присоединись к сообществу «Xakep.ru», чтобы читать все материалы на сайте
Членство в сообществе в течение указанного срока откроет тебе доступ ко ВСЕМ материалам «Хакера», увеличит личную накопительную скидку и позволит накапливать профессиональный рейтинг Xakep Score! Подробнее