Извлечение информации (англ. information extraction ) — это задача автоматического извлечения (построения) структурированных данных из неструктурированных или слабоструктурированных машиночитаемых документов.
Извлечение информации является разновидностью информационного поиска, связанного с обработкой текста на естественном языке. Примером извлечения информации может быть поиск деловых визитов — формально это записывается так: НанеслиВизит(Компания-Кто, Компания-Кому, ДатаВизита) , — из новостных лент, таких как: «Вчера, 1 апреля 2007 года, представители корпорации Пепелац Интернэшнл посетили офис компании Гравицап Продакшнз». Главная цель такого преобразования — возможность анализа изначально «хаотичной» информации с помощью стандартных методов обработки данных. [1] Более узкой целью может служить, например, задача выявить логические закономерности в описанных в тексте событиях. [2]
В современных информационных технологиях роль такой процедуры, как извлечение информации, всё больше возрастает — из-за стремительного увеличения количества неструктурированной (без метаданных) информации, в частности, в Интернете. Эта информация может быть сделана более структурированной посредством преобразования в реляционную форму или добавлением XML разметки. [3] При мониторинге новостных лент с помощью интеллектуальных агентов как раз и потребуются методы извлечения информации и преобразования её в такую форму, с которой будет удобнее работать позже.
Типичная задача извлечения информации: просканировать набор документов, написанных на естественном языке, и наполнить базу данных выделенной полезной информацией. Современные подходы извлечения информации используют методы обработки естественного языка, направленные лишь на очень ограниченный набор тем (вопросов, проблем) — часто только на одну тему. Например, «Конференция по Пониманию сообщений» (en:Message Understanding Conference, MUC) — это конференция соревновательного характера и в прошлом она фокусировалась на таких вопросах:
- MUC-1 (1987), MUC-2 (1989): Военно-морские операции.
- MUC-3 (1991), MUC-4 (1992): Терроризм в латиноамериканских странах.
- MUC-5 (1993): Венчурные операции в области микроэлектроники.
- MUC-6 (1995): Новостные статьи об изменениях в управляющих процессах.
- MUC-7 (1998): Отчёты о запусках спутников.
Тексты на естественном языке могут потребовать некоего предварительного преобразования на язык (например, RDF — Resource Description Framework), понятный для компьютера.
Типичные подзадачи извлечения информации:
- Распознавание именованных элементов (сущностей), например: имён людей, названий организаций, географических названий, событий, временны́х и денежных обозначений и пр.
- Разрешение анафоры и кореференций : поиск связей, относящихся к одному и тому же объекту. Типичный случай таких ссылок — местоименная анафора.
- Выделение терминологии: нахождение для данного текста ключевых слов и словосочетаний (коллокаций).
- Автореферирование: выделение из текста смысловой, эмотивной, оценочной и пр. информации. Бывает генеративным и декларативным.
Обычно мне не удаются длинные циклы статей по какой-то теме, однако писать про поиск и NLP оказалось интереснее обычного. Во-первых я сам структурирую собранные по крупицам собственные знания, во-вторых делюсь ими и возможно мотивирую нескольких читателей, которым это интересно, а в-третьих, заполняю информационный вакуум в данной теме в рунете.
Мне кажется, что многие не обратили должного внимания на отличную картинку, с которой начинался предыдущий пост, а ведь она действительно стоит того, чтобы немного её порассматривать. Если присмотреться в левый верхний угол, на оранжевую дорожку «Text Mining», можно примерно понять, какие разделы уже покрыты. Не все из них являются интересными для обсуждения, но есть одна, о которой хотелось бы рассказать поподробнее — Named Entity Recognition, по-русски — Извлечение Именованных Сущностей, или в более широком смысле — Извлечение Фактов, когда между именованными сущностями анализируются взаимосвязи.
Выделение именованных сущностей — одна из ключевых задач систем автоматической обработки текста. В заглавии поста приведена примерная иллюстрация того, что нас ждет. Именованные сущности — это объекты определенного типа, чаще всего составные, например, названия, имена людей, даты, места, денежные единицы и.т.д. В общем смысле это все те объекты, которые можно вытащить из текста.
Полезность умения вытащить именованные сущности из текста, думаю, очевидна большинству читателей. В Яндекс.Новостях, например, таким образом строятся аннотации к новостям, добавляются ссылки на «пресс-портреты» и карта. Очень популярно применение в системах, используемых маркетологами для анализа отзывов о товаре и упоминания бренда в сети.
Моя магистерская работа посвящена семантическому поиску, в котором система разбора и понимания запроса является основным направлением разработки. По идее она должна понимать запросы типа «Итальянские рестораны в центре Новосибирска со средним чеком менее 1000 руб, в которые ходили мои друзья за последний месяц», для чего мне просто необходимо уметь извлекать объекты «итальянский ресторан», «центр Новосибирска», «средний чек», «мои друзья» и «последний месяц» — то есть практически каждое слово в запросе является интересующей меня сущностью. Подробнее о том, как я это делаю, возможно будет описано в следующих статьях, но суть вполне ясна.
По доброй традиции в данном посте нашим подопытным кроликом для извлечения названий будут события из Futurise. Конкретным примером был случайно выбран концерт группы Louna в Новосибирске 4 апреля 2014. Хотя кого я обманываю, Louna — единственная рок-группа, на чьи концерты я хожу, но мы ведь не собираемся обсуждать сейчас мой ужасный музыкальный вкус? 🙂
Кто читал первую статью помнит, что под каждым событием в Futurise есть вот такие ссылочки на источники данных, из которых событие и сформировалось:
Простейшим примером улучшения аннотации после выделения именованных сущностей являются дополнительные полезные ссылки. Первой же идеей, пришедшей в голову, были ссылки на last.fm и скачивание дискографии с торрентов, однако возможности легко расширяются и зависят только от воображения:
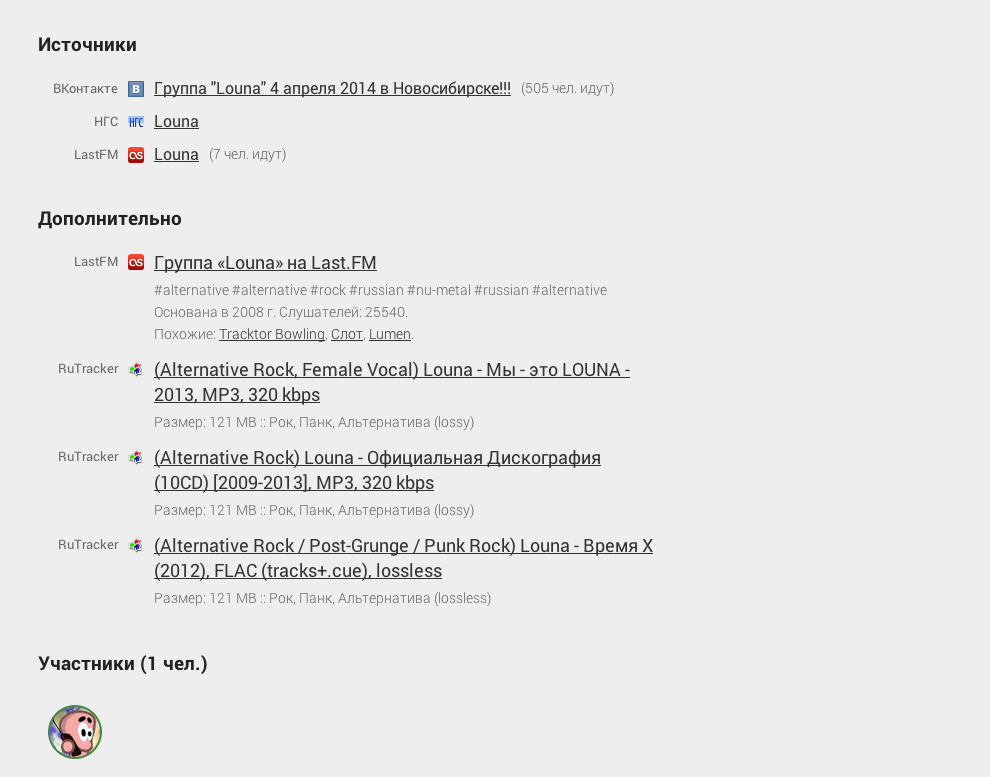
Какие идеи сразу возникают, если стоит такая задача? Наверное, первое, что приходит в голову — регулярные выражения или что-то подобное. С многообразием словоформ поможет морфологический анализ, читавшие предыдущую часть помнят, что это не сложно. Ну и дальше пишется регулярка типа «слово "клуб", за которым идет одно или несколько слов — название, возможно в кавычках». Уже сейчас понятно, что такая регулярка получается, во-первых, очень сложной, во-вторых, любое отклонение во входных данных грозит провалом. В первой части я рассказывал, что, в отличие от тех же Яндекс.Новостей, в Futurise мы имеем дело с «ну очень естественным языком» — текстами лучших SMM-профессионалов города с орфографией и пунктуацией на уровне третьеклассника и очень своеобразной стилистикой.
В регулярном выражении придется учитывать огромное множество особенностей «ну очень естественного языка» — авторы забывают закрывать кавычки, ставить знаки препинания, иногда даже пробелы считаются излишними. Не учли какую-то особенность – ничего не найдется или, того хуже, регулярка вернет половину текста в качестве «сущности». Возможно, настоящие профессионалы регулярных выражений (коим я не являюсь) смогут написать даже более-менее работающую регулярку, однако я уже представляю себе ее размер и читабельность.
Но это не значит, что регулярные выражения совершенно бесполезны. Место, где они настоящие короли бала — это даты, денежные единицы и всё остальное, что связано с цифрами. Объекты «4 апреля», «04.04.14» или «700 р» во всех системах извлечения сущностей разбираются именно регулярными выражениями. Такую регулярку, даже учитывающую все комбинации, может написать любой уважающий себя разработчик.
С датами и ценниками разобрались, но вопрос о том, как определять названия клубов или групп остается открытым. Здесь нам должна прийти в голову вторая идея: а что, если составить список всех клубов города? Для Новосибирска это пара сотен, не так уж и много, в Москве/Питере эта цифра раз в 10 больше, но всё равно не смертельна. Нормализуем, кладем в хеш-таблицу и затем ищем да тем же перебором. Или индексируем конечным автоматом и ищем по префиксам и с опечатками. Но эта методика сложная, так индексирует данные тот же 2ГИС, когда для всего словаря строится граф какая буква может идти после какой, не буду пока углубляться.
Подход многообещающий и 100% поможет нам с названиями клубов, исключив ложные срабатывания и дав максимальную точность. Особенно хорошо работает для имен известных личностей и названий известных компаний, ведь самый популярный источник таких данных — Википедия – еще частенько дает нам возможные варианты написания этих названий. Небольшая проблема может возникнуть с обновлением (например, появление нового клуба в городе), но тут нужно решать индивидуально. Кстати, такой подход называется «по словарю» или «по онтологии» (такие словари, где между терминами расставлены еще и связи).
Однако, решительно непонятно, как быть с названиями тех же музыкальных групп. Если клубы можно напарсить из открытых источников, того же Foursquare, то выгрузить все музыкальные группы в мире из last.fm, а потом еще и пытаться перебирать их, кажется нереализуемой для простого смертного задачей. Перебирать каждое слово из текста в last.fm так же займет кучу времении, повысит риск, что last.fm просто забанит вас, а так же даст кучу ложных срабатываний.
Встает проблема, что нам просто необходимо уметь хотя бы примерно определять, что какое-то словосочетание может являться названием группы. Чтобы потом полезть на тот же last.fm или в БД и проверить. Сделать это можно, например, по имеющимся где-то рядом в предложении словам «группа», «выступает», «на сцене», и.т.д. Запомним эту идею.
Третим подходом в литературе обычно выделяют «машинное обучение». По моему скромному мнению, когда лингвисты не могут придумать как решить определенную задачу, они всегда садятся в кресло, зажигают трубку, и говорят: «Нужно машинное обучение». То есть как бы сливаюся. Машинное обучение – это весело и интересно, но оно не является серебряной пулей, а скорее наоборот. Ведь главный минус машинного обучения в том, что, стоит вам выбрать немного не те или ошибиться с выбором критериев, по которым машину обучать, так всё идет, простите, по хуям. И понять, почему всё идет по хуям, чаще всего сложно или невозможно, нужно выбирать другие критерии и бегать с бубном.
Вернемся и взглянем на то, что у нас уже есть. Нужно как-то иметь находить слова «группа», «в клубе», «выступает» и названия рядом с ними. Не буду томить, это типичный алгоритм синтаксического LR-анализатора, который проходят в университете на курсе «языки программирования». На самом деле это даже GLR-парсер, который, возможно, и не проходят.
Для тех, кто прогуливал лекции или забыл, небольшое введение, так сказать «на пальцах». Кто помнит, может пропустить. Синтаксический анализатор состоит из записанной определенным образом формальной грамматики, состоящей из терминальных и нетерминальных символов.
Нетерминальный символ — объект, непосредственно присутствующий в тексте или исходном коде и имеющий конкретное, неизменяемое значение. В простых текстах это просто слово (Россия) или устойчивое словосочетание (Российская Федерация), в исходном коде это все единицы кода — названия переменных, классов, операторы, скобочки, и.т.д.
Терминальный символ — объект, обозначающий какую-либо сущность языка. Опять же в простых текстах это может быть «страна» или «название группы», в коде это «функция», «блок if», и.т.д.
LR-анализатор работает следующим образом: есть грамматика, входная строка и стек. Например дана грамматика, разбирающая последовательности типа a+a+a.
И входная цепочка:
действие – сдвиг. действие – свертка по правилу F -> a действие – сдвиг. действие – сдвиг. действие – свертка по правилу F -> a действие — свертка по правилу F -> F+F действие — свертка по правилу S -> F конечное состояние успешного LR-процесса. Пример взят отсюда и упрощен. Это условное описание работы любого LR-анализатора, остальное – всякие LR(1), LALR(1) — детали реализации. Теперь можно представить, что вместо «a» и «+» у нас слова «клуб» и его название. Идеально подходит для нас. Вот только где взять такой парсер? Для английского языка подобных парсеров очень много, даже в самый популярный пакет NLTK входит такой. А для русского? Ответ в заголовке — Томита-парсер, который Яндекс в конце 2012 года открыл для всех желающих в виде бинарника. Томита-парсер – это инструмент для извлечения структурированных данных (фактов) из текста на естественном языке. Извлечение фактов происходит при помощи контекстно-свободных грамматик и словарей ключевых слов. Парсер позволяет написать свою грамматику, добавить свои словари и запустить на текстах. В основе лежит лежит алгоритм GLR-парсинга Масару Томиты. Грамматика для Томита-парсера выглядит как-то так:
Данная грамматика очень проста и вернет нам все пары прилагательных (Adj) и существительных (Noun), согласованные по числу и падежу (nc-agr). В грамматике Adj и Noun являются терминальными символами, всё, что записано в — так называемые пометы.
Кажется, штука неплохая. Яндекс недавно громко рассказывал как они используют его в новой Яндекс.Почте. Чтобы воспользоваться нужно проделать несколько шагов.
1) Ознакомиться с лицензионным соглашением и скачать исполняемый файл Томита-парсера под вашу платформу.
2) Распаковать и положить исполняемый файл на видное или удобное для вас место.
3) Потратить вечер на изучение документации и примеров.
4) Ничего не понять, но не сдаться и найти еще больше примеров.
Разберемся на уже привычном примере: названия групп и альбомов. Написание правил для Томита-парсера начинается с главного конфига — config.proto. Да, конфиги пишутся, внезапно, на языке Google Protobuf.
dict.gzt — словарь, PrettyOutput — полезная информация для дебага, NumThreads — количество потоков парсера, Input/Output — настройки ввода вывода, читать из файла text.txt, писать в STDOUT в формате XML. Articles — используемые статьи из словаря dict.gzt, Facts — те факты, которые мы хотим извлечь.
dict.gzt выглядит так
Мы описали «мультиворд» — «слово_группа», в котором скрываются все слова, которые могут стоять перед названием группы, а так же добавили ссылку на group.cxx — файл грамматики. facttypes.proto — это описание фактов, которые мы будем извлекать, а всё остальное — служебная информация, жестко закрытая в бинарнике Томита-парсера; Яндекс говорит ее просто нужно импортировать всегда.
facttypes.proto выглядит так
Мы описали два факта, которые будем извлекать — это название группы и альбом. Наши факты состоят только из полей Name, однако, в зависимости от извлекаемой информации, они могут состоять из множества полей, причем некоторые могут быть optional.
Ну и самое интересное — group.cxx, описание грамматики.
AlbumName — состоит из слова «альбом» в любой его форме (томита поймет «альбому», «альбомы», и.т.д., так как делает нормализацию) и следующих за ним любых последовательностей символов AnyWord с открывающей кавычкой l-quoted и с большой буквы h-reg1 и любого количества слов до закрывающей кавычки (для простоты я опустит условие, что она может отсутствовать).
GroupName — состоит из слов словаря «группа», «ансамбль», и.т.д. и следующих за ним слов с большой буквы, согласованных по числу и падежу (хотя это не обязательно).
Всё, что найдет парсер, извлечется в факты благодаря конструкции interp(Group.Name::not_norm), где ::not_norm указывает, что нужно сохранять слова в таком виде, в котором они встретились в тексте.
Действительно, эта грамматика написана мной на коленке во время изучения возможностей Томита-парсера и пока не применяется, и в таком виде точно не будет применяться в Futurise. Слишком она детская и дает много ложных срабатываний, над ней нужно еще посидеть, подумать, поэкспериментировать, но это процесс творческий.
В документации Томита-парсера есть несколько примеров, а так же описаны основные структуры парсера. Мельком упомянуты алгоритмы автоматического извлечения ФИО, дат и денежных единиц, написанные на С, однако очень скудно. Могу сделать предположение, что Яндекс все еще скрывает достаточно большую часть функциональности Томита-парсера, выложив то, что мы видим сейчас, исключительно чтобы такие как я «поигрались».
Открытие исходников, понятно, скорее из разряда фантастики, однако распространение исключительно в виде бинарника, который нужно на каждый текст запускать — это палка в колеса всем, кто захочет использовать его для чего-то серьезного. Оверхед от таких перезапусков громадный, инициализация занимает почти секунду, что не позволит использовать его так же быстро, как это делает Яндекс у себя. Засранцы, короче 🙂
Но у меня для вас есть небольшой бонус. Так как я всё же планирую попытаться его использовать, я написал однофайловую обертку, которая позволяет запускать и получать данные из него на Python. Там же есть и пример, приведенный в статье.
https://github.com/vas3k/poor-python-yandex-tomita-parser
Используйте на свой страх и риск, но велкам.
В докладе рассказывается о том, как мы извлекаем сущности (например, имена людей и географические названия) из текстов и запросов. А также об извлечении фактов, т.е. связей между объектами. Мы рассмотрим несколько подходов к решению этих задач: формулирование правил, составление словарей всевозможных объектов, машинное обучение.
Лекция рассчитана на старшеклассников — студентов Малого ШАДа, но и взрослые смогут с ее помощью восполнить некоторые пробелы.
http://video.yandex.ru/users/e1coyot/view/4/
Извлечение объектов и фактов из текстов – это часть NLP (Natural Language Processing – автоматическая обработка естественного языка). Конечная цель – научить машину полноценно понимать обычный человеческий текст. И движение к этой цели мы пока только начали.
Сегодня NLP успешно применяется для нескольких целей:
- Текстовый поиск
- Извлечение фактов
- Диалоговые системы и Question Answering
- Синтез и распознавание речи
- Оценка тональности отзывов
- Кластеризация и классификация текстов.
Извлечение структурированной информации из неструктурированного текста называется Text Mining. Основная часть этого процесса посвящена определению объектов, их отношениям и свойствам в тестах. Text Mining можно условно разделить на несколько крупных задач:
- Named Entity Recognition (NER) – извлечение именованных сущностей/объектов;
- Co-reference resolution – разрешение кореференции;
- Information Extraction (IE) – извлечение фактов.
Итак, для начала разметим в тексте именованные сущности. В примере красным выделены названия компаний, а зеленым – имена людей. Это выделение соответсвует желаемому поведению алгоритма. После чего можно переходить к разрешению кореференции.

Кореференция – это попытка связать несколько разных отсылок в тексте к одному реальному объекту.

Одним из примеров кореференции является анафора – отсылка к объекту при помощи специальных указателей. В нашем случае – это местоимения.
Второй пример кореференции – это синонимия. Она может быть выражена по-разному:
- Транслитерация: Yandex – Яндекс.
- Аббревиация: ВТБ – Внешторгбанк – Банк Внешней Торговли.
- Синонимы: больница – госпиталь.
- Словообразование: Москва – московский.
- Графические: авто кредит – автокредит.
Кореференцию нужно обязательно учитывать при анализе текста, чтобы избежать извлечения лишних фактов и сущностей, не имеющих привязки к реальным объектам.
Факты можно представить как строки в таблице, в столбцах которых находятся объекты и отношения между ними. Результат процесса извлечения фактов выглядит примерно следующим образом:

Мы обычно применяем IE для извлечения следующих типов объектов: даты, адреса, телефоны, ФИО, названия товаров, компаний и т.п. Полезными фактами чаще всего являются события, мнения и отзывы, контактные данные и объявления.
Первичная обработка текста
Итак, на входе у нас текст на естественном языке. Анализировать его необходимо сразу на всех лингвистических уровнях:
- графематическом.
- лексическом
- морфологическом
- синтаксическом
- семантическом
Текст делится на абзацы, предложения, слова. Затем слова нормализуются – выделяется их начальная форма. Далее проводится полный или частичный синтаксический разбор, определяются зависимости и связи между словами в предложениях.
На первый взгляд кажется, что разбить текст на предложения не составляет никакого труда. Нужно просто ориентироваться на знаки препинания, маркирующие конец предложения. Но работает этот метод далеко не всегда. Ведь, например, точка может обозначать и сокращение, использоваться в дробных числах или URL. Любой знак препинания может использоваться в названиях компаний или сервисов. Например, Yahoo! Или Яндекс.Маркет.
С выделением начальной формы тоже не все так просто. Конечно, в большинстве случаев ее можно получить при помощи морфологического словаря. Но применимо это далеко не всегда. Например, как определить словарную форму слова «стекло»? Это может быть как существительное, так и глагол. И прежде чем обращаться к морфологическому словарю, нужно снять омонимию. Решается эта при помощи корпуса языка, в котором все слова размечены по частям речи, и омонимия снята. Таким образом, основываясь на контексте, и статистике употребления слова в корпусе, можно принять решение, к какой же части речи относится то или иное слово.
Следующий этап — полный или частичный синтаксический разбор. Выстраивается граф зависимостей и отношений между словами внутри предложения. Вот пример синтаксического дерева, которое можно построить при помощи синтаксического парсера:
Алгоритмов, которые в любых условиях могут построить полный синтаксический граф без ошибок не существует. Однако для большинства прикладных задач Text Mining достаточно и частичного разбора.
Помимо морфологической омонимии, о которой мы говорили выше, бывает также синтаксическая и «объектная» омонимия. В качестве примера синтаксической омонимии приведем пример: «Он видел их семью своими глазами». Оба варианта прочтения будут синтаксически верны: кто-то видел чью-то семью своими глазами, либо некто семиглазый кого-то видел. Для решения такой проблемы нужно привлекать уже семантический анализ.
«Объектная» омонимия предполагает, что у двух различных реальных объектов могут быть одинаковые наименования. Например, в России есть сразу два известных человека по имени Михаил Задорнов: юморист и бывший министр финансов. Если не научить систему различать этих людей, при попытке извлечения фактов о них, могут возникать разнообразные казусы.
Извлечение фактов
Когда все эти шаги пройдены, можно переходить непосредственно к извлечению фактов. При помощи специальных алгоритмов мы хотим получить из неструктурированного отрывка текст, в котором все нужные нам объекты и факты будут размечены и категорированы. Наглядно представить это можно следующим образом:

Условно можно выделить три основных подхода, применяющихся в извлечении фактов:
- по онтологиям;
- опираясь на правила (Rule-based);
- опираясь на машинное обучение (ML).
В нашем случае онтологии — это «концептуальные словари», представляющие собой структуры, в которых описываются некоторые понятия и/или объекты, отношения между ними, а также их характеристики.
Онтологии могут быть универсальными (в них предпринимается попытка описать максимально широкий набор объектов), отраслевые (с информацией по предметным областям) и узкоспециализированные (предназначенные для решения конкретной задачи). Также могут применяться онтологии объектов (базы знаний). Наиболее яркий пример базы знаний — это Википедия.
Итак, у нас есть некая онтология. Опираясь на контексты и уже имеющиеся списки объектов можно строить гипотезы по отношению к объектам и фактам в тексте, а далее верифицировать или отклонять эти гипотезы. Слева приведен текст, в котором цветом размечены объекты, о которых хотелось бы извлечь какую-нибудь информацию. В качестве онтологии применим Википедию. Отправляя туда запросы по всем ключевым словам из нашего текста, мы получим список статей, расположенный справа. Красным в нем помечены статьи, относящиеся сразу к нескольким объектам.

Теперь наша цель — отсечь неверные гипотезы. Сделать это можно разными способами. Чаще всего применяется машинное обучение, различные контекстные и синтаксические факторы.
Извлечение информации с помощью онтологий позволяет получить достаточно высокую точность NER и отсутствие случайных срабатываний. Снятие омонимии также происходит с высокой точностью. К недостаткам этого подхода можно отнести низкую полноту, ведь извлечь можно только то, что уже есть в онтологии. А в онтологию нужно либо добавлять объекты руками, либо выстраивать процедуру автоматического добавления.
Другой подход — машинное обучение — требует большого объема вводных данных. Нужно максимально покрыть лингвистической информацией обучающую выборку текстов: разметить всю морфологию, синтаксис, семантику, онтологические связи. Плюсы этого подхода в том он не требует ручного труда помимо создания размеченного корпуса. Не нужно составлять правила или онтологии. При необходимости такая система легко перенастраивается и переобучается. Правила получаются более абстрактными. Однако есть и минусы. Инструменты для автоматической разметки русскоязычных текстов пока не очень развиты, а существующие не всегда легко доступны. Корпуса должны быть достаточно объемными, размечены верно, единообразно и полностью. А это достаточно трудоемкий процесс. Кроме того, если что-то пошло не так, сложно отследить, где именно возникла ошибка, и точечно ее исправить.
Третий подход – подход, основанный на правилах, т.е. написание шаблонов вручную. Аналитик составляет описания типов информации, которые необходимо извлечь. Подход удобен тем, что если в результатах анализ обнаруживаются ошибки, очень просто найти их причину и внести необходимые изменения в правила. Проще всего составляются правила для относительно стандартизированных объектов: имен, дат, наименований компаний и т.п.
Выбор оптимального подхода определяется конкретной задачей. Сейчас чаще всего применяются онтологии и машинное обучение, однако, будущее за гибридными системами.
В Яндексе NER используется для извлечения фактов в почте, названий географических объектов и имен из запросов, фактов в вакансиях, а также для кластеризации и классификации новостей.