Успешно изучив материал, Вы будете знать :
понятие и основное назначение OLTP-систем;
понятие и основное назначение OLAP-систем;
задачи, решаемые OLTP- и OLAP-системами.
После изучения данной темы Вы будете уметь :
отличать задачи, решаемые OLTP- и OLAP-системами;
ориентироваться в классах OLAP-систем.
После изучения материала Вы будете обладать навыками использования OLTP- и OLAP-системам в работе менеджера.
OLTP-система 
OLAP-система
Data Warehousing — «хранилища (склады) данных»
В области ИТ управления существуют два взаимно дополняющих друг друга направления:
технологии, ориентированные на оперативную (транзакционную) обработку данных. Эти технологии лежат в основе КИСУ, предназначенных для оперативной обработки данных. Называются подобные системы — OLTP ( online transaction processing ) системы ;
технологии, ориентированные на анализ данных и принятие решений. Эти технологии лежат в основе КИСУ, предназначенных для анализа накопленных данных. Называются подобные системы — OLAP ( online analytical processing ) системы .
Основное назначение OLAP-систем : динамический многомерный анализ исторических и текущих данных, стабильных во времени; анализ тенденций; моделирование и прогнозирование будущего. Такие системы, как правило, ориентированы на обработку произвольных, заранее не регламентированных запросов. В качестве основных характеристик этих систем можно отметить следующие :
поддержка многомерного представления данных, равноправие всех измерений, независимость производительности от количества измерений;
прозрачность для пользователя структуры, способов хранения и обработки данных;
автоматическое отображение логической структуры данных во внешние системы;
динамическая обработка разряженных матриц эффективным способом.
Термин OLAP часто отождествляют с системами поддержки принятия решений DSS (Decision Support Systems). А в качестве синонима термина «решения» используют Data Warehousing — «хранилища (склады) данных» . Под этим понимается набор организационных решений, программных и аппаратных средств для обеспечения аналитиков информацией на основе данных из систем обработки транзакций нижнего уровня и других источников.
«Склады данных» позволяют обрабатывать данные, накопленные за длительные периоды времени. Эти данные являются разнородными (и не обязательно структурированными). Для «складов данных» присущ многомерный характер запросов. Огромные объемы данных, сложность структуры как данных, так и запросов — все это требует использования специальных методов доступа к информации.
В других источниках понятие Системы Поддержки Принятия Решений (СППР) считается более широким. Хранилища данных и средства оперативной аналитической обработки могут служить одними из компонентов архитектуры СППР.
OLAP всегда включает в себя интерактивную обработку запросов и последующий многопроходный анализ информации, который позволяет выявить разнообразные, не всегда очевидные тенденции, наблюдающиеся в предметной области.
Иногда различают OLAP в узком смысле — как системы, которые обеспечивают только выборку данных в различных разрезах, и OLAP в широком смысле, или просто OLAP, включающие в себя:
поддержку нескольких пользователей, редактирующих БД.
функции моделирования, в том числе вычислительные механизмы получения производных результатов, а также агрегирования и объединения данных;
прогнозирование, выявление тенденций и статистический анализ.
Каждый из этих типов систем требует специфической организации данных, а также специальных программных средств, обеспечивающих эффективное выполнение стоящих задач.
OLAP-средства обеспечивают проведение анализа деловой информации по множеству параметров, таких как вид товара, географическое положение покупателя, время оформления сделки и продавец, каждый из которых допускает создание иерархии представлений. Так, для времени можно пользоваться годовыми, квартальными, месячными и даже недельными и дневными промежутками; географическое разбиение может проводиться по городам, штатам, регионам, странам или, если потребуется, по целым полушариям.
OLAP-системы можно разбить на три класса.
1 класс. Наиболее сложными и дорогими из них являются основанные на патентованных технологиях серверы многомерных БД . Эти системы обеспечивают полный цикл OLAP-обработки и либо включают в себя, помимо серверного компонента, собственный интегрированный клиентский интерфейс, либо используют для анализа данных внешние программы работы с электронными таблицами. Продукты этого класса в наибольшей степени соответствуют условиям применения в рамках крупных информационных хранилищ. Для их обслуживания требуется целый штат сотрудников, занимающихся как установкой и сопровождением системы, так и формированием представлений данных для конечных пользователей. Обычно подобные пакеты довольно дороги. В качестве примеров продуктов этого класса можно привести систему Essbase корпорации Arbor Software, Express фирмы IRI (входящей теперь в состав Oracle), Lightship производства компании Pilot Software и др.
2 класс OLAP-систем — реляционные OLAP-системы (ROLAP). Здесь для хранения данных используются старые реляционные СУБД, а между БД и клиентским интерфейсом организуется определяемый администратором системы слой метаданных. Через этот промежуточный слой клиентский компонент может взаимодействовать с реляционной БД как с многомерной. Подобно средствам первого класса, ROLAP-системы хорошо приспособлены для работы с крупными информационными хранилищами, требуют значительных затрат на обслуживание специалистами информационных подразделений и предусматривают работу в многопользовательском режиме. Среди продуктов этого типа — IQ/Vision корпорации IQ Software, DSS/Server и DSS/Agent фирмы MicroStrategy и DecisionSuite компании Information Advantage.
ROLAP-средства реализуют функции поддержки принятия решений в надстройке над реляционным процессором БД.
Такие программные продукты должны отвечать ряду требований , в частности:
иметь мощный оптимизированный для OLAP генератор SQL-выражений, позволяющий применять многопроходные SQL-операторы SELECT и/или коррелированные подзапросы;
обладать достаточно развитыми средствами для проведения нетривиальной обработки, обеспечивающей ранжирование, сравнительный анализ и вычисление процентных соотношений в рамках класса;
генерировать SQL-выражения, оптимизированные для целевой реляционной СУБД, включая поддержку доступных в ней расширений этого языка;
предоставлять механизмы описания модели данных с помощью метаданных и давать возможность использовать эти метаданные для построения запросов в реальном масштабе времени;
включать в себя механизм, позволяющий оценивать качество построения сводных таблиц с точки зрения скорости вычисления, желательно с накоплением статистики по их использованию.
3 класс OLAP-систем — инструменты генерации запросов и отчетов для настольных ПК , дополненные OLAP-функциями или интегрированные с внешними средствами, выполняющими такие функции. Эти весьма развитые системы осуществляют выборку данных из исходных источников, преобразуют их и помещают в динамическую многомерную БД, функционирующую на ПК конечного пользователя. Указанный подход, позволяющий обойтись как без дорогостоящего сервера многомерной БД, так и без сложного промежуточного слоя метаданных, необходимого для ROLAP-средств, обеспечивает в то же время достаточную эффективность анализа. Эти средства для настольных ПК лучше всего подходят для работы с небольшими, просто организованными БД. Потребность в квалифицированном обслуживании для них ниже, чем для других OLAP-систем, и примерно соответствует уровню обычных сред обработки запросов. В числе основных участников этого сектора рынка — компания Brio Technology со своей системой Brio Query Enterprise, Business Objects с одноименным продуктом и Cognos с PowerPlay.
OLTP-системы , являясь высокоэффективным средством реализации оперативной обработки, оказались малопригодны для задач аналитической обработки. Это вызвано следующим.
Средствами традиционных OLTP-систем можно построить аналитический отчет и даже прогноз любой сложности, но заранее регламентированный. Любой шаг в сторону, любое нерегламентированное требование конечного пользователя, как правило, требует знаний о структуре данных и достаточно высокой квалификации программиста;
Многие необходимые для оперативных систем функциональные возможности являются избыточными для аналитических задач и в то же время могут не отражать предметной области. Для решения большинства аналитических задач требуется использование внешних специализированных инструментальных средств для анализа, прогнозирования и моделирования. Жесткая же структура баз не позволяет достичь приемлемой производительности в случае сложных выборок и сортировок и, следовательно, требует больших временных затрат для организации шлюзов.
В отличие от транзакционных, в аналитических системах не требуются и, соответственно, не предусматриваются развитые средства обеспечения целостности данных, их резервирования и восстановления. Это позволяет не только упростить сами средства реализации, но и снизить внутренние накладные расходы и, следовательно, повысить производительность при выборке данных.
Задачи, эффективно решаемые каждой из систем, определим на основе сравнительных характеристик OLTP- и OLAP-систем (табл. 7.1, 7.2).
Таблица 7.1.
Задачи, решаемые OLTP- и OLAP-системами
Характеристика
OLTP
OLAP
Частота обновления данных
Высокая частота, небольшие «порции»
Малая частота, большие «порции»
В основном внутренние
По отношению к аналитической системе, в основном внешние
Текущие (несколько месяцев)
Исторически (за годы) и прогнозируемые
Уровень агрегации данных
В основном агрегированные данные
Возможности аналитических операций
Последовательность интерактивных отчетов, динамическое изменение уровней агрегаций и срезов данных
Фиксация, оперативный поиск и обработка данных, регламентированная аналитическая обработка
Работа с историческими данными, аналитическая обработка, прогнозирование, моделирование
Таблица 7.2.
Сравнение OLTP и OLAP
Сравнение нормализованных и ненормализованных моделей
Анализ критериев для нормализованных и ненормализованных моделей данных
Соберем воедино результаты анализа критериев, по которым мы хотели оценить влияние логического моделирования данных на качество физических моделей данных и производительность базы данных:
| Критерий | Отношения слабо нормализованы (1НФ, 2НФ) | Отношения сильно нормализованы (3НФ) |
| Адекватность базы данных предметной области | ХУЖЕ (-) | ЛУЧШЕ (+) |
| Легкость разработки и сопровождения базы данных | СЛОЖНЕЕ (-) | ЛЕГЧЕ (+) |
| Скорость выполнения вставки, обновления, удаления | МЕДЛЕННЕЕ (-) | БЫСТРЕЕ (+) |
| Скорость выполнения выборки данных | БЫСТРЕЕ (+) | МЕДЛЕННЕЕ (-) |
Как видно из таблицы, более сильно нормализованные отношения оказываются лучше спроектированы (три плюса, один минус). Они больше соответствуют предметной области, легче в разработке, для них быстрее выполняются операции модификации базы данных. Правда, это достигается ценой некоторого замедления выполнения операций выборки данных.
У слабо нормализованных отношений единственное преимущество – если к базе данных обращаться только с запросами на выборку данных, то для слабо нормализованных отношений такие запросы выполняются быстрее. Это связано с тем, что в таких отношениях уже как бы произведено соединение отношений и на это не тратится время при выборке данных.
Таким образом, выбор степени нормализации отношений зависит от характера запросов, с которыми чаще всего обращаются к базе данных.
Можно выделить некоторые классы систем, для которых больше подходят сильно или слабо нормализованные модели данных.
Сильно нормализованные модели данных хорошо подходят для так называемых OLTP-приложений (On-Line Transaction Processing (OLTP) – оперативная обработка транзакций). Типичными примерами OLTP-приложений являются системы складского учета, системы заказов билетов, банковские системы, выполняющие операции по переводу денег, и т. п. Основная функция подобных систем заключается в выполнении большого количества коротких транзакций. Сами транзакции выглядят относительно просто, например, «снять сумму денег со счета А, добавить эту сумму на счет В». Проблема заключается в том, что, во-первых, транзакций очень много, во-вторых, выполняются они одновременно (к системе может быть подключено несколько тысяч одновременно работающих пользователей), в-третьих, при возникновении ошибки, транзакция должна целиком откатиться и вернуть систему к состоянию, которое было до начала транзакции (не должно быть ситуации, когда деньги сняты со счета А, но не поступили на счет В). Практически все запросы к базе данных в OLTP-приложениях состоят из команд вставки, обновления, удаления. Запросы на выборку в основном предназначены для предоставления пользователям возможности выбора из различных справочников. Большая часть запросов, таким образом, известна заранее еще на этапе проектирования системы. Таким образом, критическим для OLTP-приложений является скорость и надежность выполнения коротких операций обновления данных. Чем выше уровень нормализации данных в OLTP-приложении, тем оно, как правило, быстрее и надежнее. Отступления от этого правила могут происходить тогда, когда уже на этапе разработки известны некоторые часто возникающие запросы, требующие соединения отношений и от скорости выполнения которых существенно зависит работа приложений. В этом случае можно пожертвовать нормализацией для ускорения выполнения подобных запросов.
Другим типом приложений являются так называемые OLAP-приложения (On-Line Analitical Processing (OLAP) – оперативная аналитическая обработка данных). Это обобщенный термин, характеризующий принципы построения систем поддержки принятия решений (Decision Support System – DSS), хранилищ данных (Data Warehouse), систем интеллектуального анализа данных (Data Mining). Такие системы предназначены для нахождения зависимостей между данными (например, можно попытаться определить, как связан объем продаж товаров с характеристиками потенциальных покупателей), для проведения анализа «что если…». OLAP-приложения оперируют с большими массивами данных, уже накопленными в OLTP-приложениях, взятыми их электронных таблиц или из других источников данных. Такие системы характеризуются следующими признаками:
- Добавление в систему новых данных происходит относительно редко крупными блоками (например, раз в квартал загружаются данные по итогам квартальных продаж из OLTP-приложения).
- Данные, добавленные в систему, обычно никогда не удаляются.
- Перед загрузкой данные проходят различные процедуры «очистки», связанные с тем, что в одну систему могут поступать данные из многих источников, имеющих различные форматы представления для одних и тех же понятий, данные могут быть некорректны, ошибочны.
- Запросы к системе являются нерегламентированными и, как правило, достаточно сложными. Очень часто новый запрос формулируется аналитиком для уточнения результата, полученного в результате предыдущего запроса.
- Скорость выполнения запросов важна, но не критична.
Данные OLAP-приложений обычно представлены в виде одного или нескольких гиперкубов, измерения которого представляют собой справочные данные, а в ячейках самого гиперкуба хранятся собственно данные. Например, можно построить гиперкуб, измерениями которого являются: время (в кварталах, годах), тип товара и отделения компании, а в ячейках хранятся объемы продаж. Такой гиперкуб будет содержать данных о продажах различных типов товаров по кварталам и подразделениям. Основываясь на этих данных, можно отвечать на вопросы вроде «у какого подразделения самые лучшие объемы продаж в текущем году?», или «каковы тенденции продаж отделений Юго-Западного региона в текущем году по сравнению с предыдущим годом»?
Физически гиперкуб может быть построен на основе специальной многомерной модели данных (MOLAP – Multidimensional OLAP) или построен средствами реляционной модели данных (ROLAP – Relational OLAP).
Возвращаясь к проблеме нормализации данных, можно сказать, что в системах OLAP, использующих реляционную модель данных (ROLAP), данные целесообразно хранить в виде слабо нормализованных отношений, содержащих заранее вычисленные основные итоговые данные. Большая избыточность и связанные с ней проблемы тут не страшны, т.к. обновление происходит только в момент загрузки новой порции данных. При этом происходит как добавление новых данных, так и пересчет итогов.
Корректность процедуры нормализации – декомпозиция без потерь. Теорема Хеза
Как было показано выше, алгоритм нормализации состоит в выявлении функциональных зависимостей предметной области и соответствующей декомпозиции отношений. Предположим, что мы уже имеем работающую систему, в которой накоплены данные. Пусть данных корректны в текущий момент, т.е. факты предметной области правильно отражаются текущим состоянием базы данных. Если в предметной области обнаружена новая функциональная зависимость (либо она была пропущена на этапе моделирования предметной области, либо просто изменилась предметная область), то возникает необходимость заново нормализовать данные. При этом некоторые отношения придется декомпозировать в соответствии с алгоритмом нормализации. Возникают естественные вопросы – что произойдет с уже накопленными данными? Не будут ли данные потеряны в ходе декомпозиции? Можно ли вернуться обратно к исходным отношениям, если будет принято решение отказаться от декомпозиции, восстановятся ли при этом данные?
Для ответов на эти вопросы нужно ответить на вопрос – что же представляет собой декомпозиция отношений с точки зрения операций реляционной алгебры? При декомпозиции мы из одного отношения получаем два или более отношений, каждое из которых содержит часть атрибутов исходного отношения. В полученных новых отношениях необходимо удалить дубликаты строк, если таковые возникли. Это в точности означает, что декомпозиция отношения есть не что иное, как взятие одной или нескольких проекций исходного отношения так, чтобы эти проекции в совокупности содержали (возможно, с повторениями) все атрибуты исходного отношения. Т.е., при декомпозиции не должны теряться атрибуты отношений. Но при декомпозиции также не должны потеряться и сами данные. Данные можно считать не потерянными в том случае, если возможна обратная операция – по декомпозированным отношениям можно восстановить исходное отношение в точности в прежнем виде. Операцией, обратной операции проекции, является операция соединения отношений. Имеется большое количество видов операции соединения (см. гл. 4). Т.к. при восстановлении исходного отношения путем соединения проекций не должны появиться новые атрибуты, то необходимо использовать естественное соединение.
Определение 6. Проекция R[X] отношения R на множество атрибутов X называется собственной, если множество атрибутов X является собственным подмножеством множества атрибутов отношения R (т.е. множество атрибутов X не совпадает с множеством всех атрибутов отношения R).
Определение 7. Собственные проекции R1 и R2 отношения R называются декомпозицией без потерь, если отношение R точно восстанавливается из них при помощи естественного соединения для любого состояния отношения R: 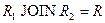 .
.
Рассмотрим пример, показывающий, что декомпозиция без потерь происходит не всегда.
Пример 2. Пусть дано отношение R:
| Таблица 7 Отношение R |
| НОМЕР | ФАМИЛИЯ | ЗАРПЛАТА |
| Иванов | ||
| Петров |
Рассмотрим первый вариант декомпозиции отношения R на два отношения:
| Таблица 8 Отношение R1 |
| НОМЕР | ЗАРПЛАТА |
Естественное соединение этих проекций, имеющих общий атрибут «ЗАРПЛАТА», очевидно, будет следующим (каждая строка одной проекции соединится с каждой строкой другой проекции):
Таблица 10 Отношение 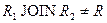 |
| НОМЕР | ФАМИЛИЯ | ЗАРПЛАТА |
| Иванов | ||
| Петров | ||
| Иванов | ||
| Петров |
Итак, данная декомпозиция не является декомпозицией без потерь, т.к. исходное отношение не восстанавливается в точном виде по проекциям.
Рассмотрим другой вариант декомпозиции:
| Таблица 11 Отношение R1 |
| НОМЕР | ФАМИЛИЯ |
| Иванов | |
| Петров |
По данным проекциям, имеющие общий атрибут «НОМЕР», исходное отношение восстанавливается в точном виде. Тем не менее, нельзя сказать, что данная декомпозиция является декомпозицией без потерь, т.к. мы рассмотрели только одно конкретное состояние отношения R, и не можем сказать, будет ли и в других состояниях отношение R восстанавливаться точно. Например, предположим, что отношение R перешло в состояние:
| Таблица 13 Отношение R |
| НОМЕР | ФАМИЛИЯ | ЗАРПЛАТА |
| Иванов | ||
| Петров | ||
| Сидоров |
Кажется, что этого не может быть, т.к. значения в атрибуте «НОМЕР» повторяются. Но мы же ничего не говорили о ключе этого отношения! Сейчас проекции будут иметь вид:
| Таблица 14 Отношение R1 |
| НОМЕР | ФАМИЛИЯ |
| Иванов | |
| Петров | |
| Сидоров |
Естественное соединение этих проекций будет содержать лишние кортежи:
Таблица 16 Отношение 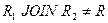 |
| НОМЕР | ФАМИЛИЯ | ЗАРПЛАТА |
| Иванов | ||
| Петров | ||
| Петров | ||
| Сидоров | ||
| Сидоров |
Вывод. Таким образом, без дополнительных ограничений на отношение R нельзя говорить о декомпозиции без потерь.
Такими дополнительными ограничениями и являются функциональные зависимости. Имеет место следующая теорема Хеза [54]:
Теорема (Хеза). Пусть  является отношением, и
является отношением, и  – атрибуты или множества атрибутов этого отношения. Если имеется функциональная зависимость
– атрибуты или множества атрибутов этого отношения. Если имеется функциональная зависимость 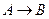 , то проекции
, то проекции 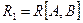 и
и 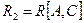 образуют декомпозицию без потерь.
образуют декомпозицию без потерь.
Доказательство. Необходимо доказать, что для любого состояния отношения R. В левой и правой части равенства стоят множества кортежей, поэтому для доказательства достаточно доказать два включения для двух множеств кортежей: 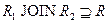 и
и 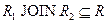 .
.
Докажем первое включение. Возьмем произвольный кортеж 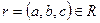 . Докажем, что он включается также и в
. Докажем, что он включается также и в 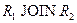 . По определению проекции, кортежи
. По определению проекции, кортежи 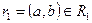 и
и 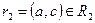 . По определению естественного соединения кортежи r1 и r2, имеющие одинаковое значение a общего атрибута A, будут соединены в процессе естественного соединения в кортеж
. По определению естественного соединения кортежи r1 и r2, имеющие одинаковое значение a общего атрибута A, будут соединены в процессе естественного соединения в кортеж 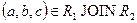 . Таким образом, включение доказано.
. Таким образом, включение доказано.
Докажем обратное включение. Возьмем произвольный кортеж  . Докажем, что он включается также и в R. По определению естественного соединения получим, что имеются кортежи и . Т.к. , то существует некоторое значение c1, такое что кортеж
. Докажем, что он включается также и в R. По определению естественного соединения получим, что имеются кортежи и . Т.к. , то существует некоторое значение c1, такое что кортеж 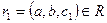 . Аналогично, существует некоторое значение b1, такое что кортеж
. Аналогично, существует некоторое значение b1, такое что кортеж 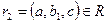 . Кортежи r1 и r2 имеют одинаковое значение атрибута A, равное a. Из этого, в силу функциональной зависимости , следует, что
. Кортежи r1 и r2 имеют одинаковое значение атрибута A, равное a. Из этого, в силу функциональной зависимости , следует, что 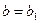 . Таким образом, кортеж
. Таким образом, кортеж 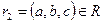 . Обратное включение доказано.
. Обратное включение доказано.
Теорема доказана.
Замечание. В доказательстве теоремы Хеза наличие функциональной зависимости не использовалось при доказательстве включения . Это означает, что при выполнении декомпозиции и последующем восстановлении отношения при помощи естественного соединения, кортежи исходного отношения не будут потеряны. Основной смысл теоремы Хеза заключается в доказательстве того, что при этом не появятся новые кортежи, отсутствовавшие в исходном отношении.
Т.к. алгоритм нормализации (приведения отношений к 3НФ) основан на имеющихся в отношениях функциональных зависимостях, то теорема Хеза показывает, что алгоритм нормализации является корректным, т.е. в ходе нормализации не происходит потери информации.
Не нашли то, что искали? Воспользуйтесь поиском:
Можно выделить некоторые классы информационных систем, для которых больше подходят сильно или слабо нормализованные модели данных.
Сильно нормализованные модели данных хорошо подходят для так называемых OLTP-систем (On-Line Transaction Processing – оперативная обработка транзакций).
Типичными примерами OLTP-систем являются системы складского учета, системы заказов билетов, банковские системы, выполняющие операции по переводу денег, и т.п. Основная функция подобных систем заключается в выполнении большого количества коротких транзакций. Механизм транзакций будет подробно рассмотрен лекции 16, для понимания принципов работы OLTP-систем достаточно представлять транзакцию как атомарное действие, изменяющее состояние базы данных.
Транзакции в OLTP–системе являются относительно простыми, например, «снять сумму денег со счета А и добавить эту сумму на счет В». Проблема заключается в том, что, во-первых, транзакций очень много, во-вторых, выполняются они одновременно (к системе может быть подключено несколько тысяч одновременно работающих пользователей), в-третьих, при возникновении ошибки, транзакция должна целиком откатиться и вернуть систему к состоянию, которое было до начала транзакции (не должно быть ситуации, когда деньги сняты со счета А, но не поступили на счет В).
Практически все запросы к базе данных в OLTP-приложениях состоят из команд вставки, обновления, удаления. Запросы на выборку в основном предназначены для предоставления пользователям возможности выбора из различных справочников. Большая часть запросов известна заранее еще на этапе проектирования системы. Таким образом, критическим для OLTP-приложений является скорость и надежность выполнения коротких операций обновления данных.
База данных, с которой работают OLTP-приложения, постоянно обновляется, в связи с этим ее обычно называют оперативной БД. Чем выше уровень нормализации оперативной БД, тем быстрее и надежнее работают OLTP-приложения. Отступления от этого правила могут происходить тогда, когда уже на этапе разработки известны некоторые часто возникающие запросы, требующие соединения отношений и от скорости выполнения которых существенно зависит работа приложений. В этом случае можно сознательно внести некоторую избыточность в базу данных для ускорения выполнения подобных запросов.
Другим типом информационных систем являются так называемые OLAP-системы (On-Line Analitical Processing – оперативная аналитическая обработка данных). OLAP используется для принятия управленческих решений, поэтому системы, использующие технологию OLAP, называют системами поддержки принятия решений (Decision Support System – DSS).
Концепция OLAP была описана в 1993 году Эдгаром Коддом, автором реляционной модели данных.
В 1995 году на основе требований, изложенных Коддом, был сформулирован так называемый тест FASMI (Fast Analysis of Shared Multidimensional Information — быстрый анализ разделяемой многомерной информации), включающий следующие требования к приложениям для многомерного анализа:
· предоставление пользователю результатов анализа за приемлемое время (обычно не более 5 с), пусть даже ценой менее детального анализа;
· возможность осуществления любого логического и статистического анализа, характерного для данного приложения, и его сохранения в доступном для конечного пользователя виде;
· многопользовательский доступ к данным с поддержкой соответствующих механизмов блокировок и средств авторизованного доступа;
· многомерное концептуальное представление данных, включая полную поддержку для иерархий и множественных иерархий (это — ключевое требование OLAP);
· возможность обращаться к любой нужной информации независимо от ее объема и места хранения.
OLAP-приложения оперируют с большими массивами данных, уже накопленными в оперативных баз данных OLTP-систем, взятыми из электронных таблиц или из других источников данных. Такие системы характеризуются следующими признаками:
· Добавление в систему новых данных происходит относительно редко крупными блоками (например, раз в квартал загружаются данные по итогам квартальных продаж из OLTP-системы).
· Данные, добавленные в систему, обычно никогда не удаляются и не изменяются.
· Перед загрузкой данные проходят различные процедуры "очистки", связанные с тем, что в одну систему могут поступать данные из многих источников, имеющих различные форматы представления, данные могут быть некорректны, ошибочны.
· Запросы к системе являются нерегламентированными и, как правило, достаточно сложными. Очень часто новый запрос формулируется аналитиком для уточнения результата, полученного в результате предыдущего запроса.
· Скорость выполнения запросов важна, но не критична.
Исходя из перечисленных признаков OLAP-систем, можно сделать вывод, что база данных такой системы может быть в значительной степени денормализованной. Поскольку основным видом запросов к базе данных являются запросы на выборку, положительные моменты нормализации не могут быть использованы, а сокращение операций соединения в запросах окажется весьма полезным.
В последнее время активно развивается еще одно направление аналитической обработки данных, получившее название Data Mining (осмысление данных, иногда говорят «раскопка данных»). Это направление направлено на поиск скрытых закономерностей в данных и решение задач прогнозирования. Приложения DataMining также не изменяют данные, с которыми они работают, поэтому для них более предпочтительной является денормализованная база данных.
Для того, чтобы подчеркнуть особый способ организации данных, которые могут эффективно использоваться для анализа приложениями OLAP и Data Mining, к ним применяют специальный термин «хранилища данных» (DataWare House). Важно отметить, что хранилища данных, в отличие от оперативной БД, хранят исторические данные, т.е. отражают те факты из деятельности предприятия, которые уже произошли, следовательно, могут храниться в неизменном виде («историю не переписывают») и накапливаться годами, в связи с чем их размеры могут стать весьма внушительными. После перекачки данных в хранилище они обычно удаляются из оперативной БД, что позволять поддерживать ее размеры в заданных пределах.
Таким образом, можно представить корпоративную информационную систему современного предприятия в виде совокупности нескольких различных подсистем, среди которых есть OLTP, OLAP-системы, а также приложения DataMining (рис 3.12).
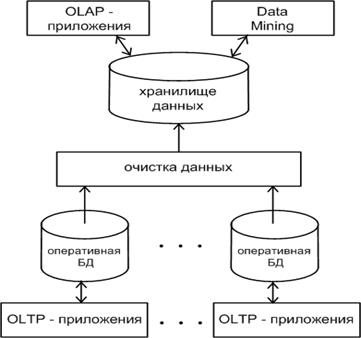
Рис.3.12 – Интегрированная информационная система предприятия
Корпоративные данные могут собираться в одной или нескольких оперативных БД, а все исторические данные концентрируются в едином хранилище, которое объединяет все данные в целях выполнения различных видов их анализа и предоставления управленческому персоналу информации, необходимой для принятия обоснованных решений по управлению бизнесом.
Дата добавления: 2015-08-26 ; просмотров: 7399 ; ЗАКАЗАТЬ НАПИСАНИЕ РАБОТЫ