Содержание
| Двоичное дерево поиска | |
|---|---|
 |
|
| Тип | дерево |
| Изобретена в | 1960 |
| Создатель | Andrew Donald Booth [d] |
| Сложность в О-символике | |
| В среднем | В худшем случае | |
|---|---|---|
| Расход памяти | O(n) | O(n) |
| Поиск | O(log n) | O(n) |
| Вставка | O(log n) | O(n) |
| Удаление | O(log n) | O(n) |
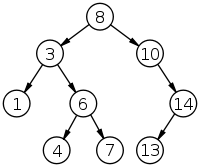
Двоичное дерево поиска (англ. binary search tree , BST) — это двоичное дерево, для которого выполняются следующие дополнительные условия (свойства дерева поиска):
- Оба поддерева — левое и правое — являются двоичными деревьями поиска.
- У всех узлов левого поддерева произвольного узла X значения ключей данных меньше, нежели значение ключа данных самого узла X.
- У всех узлов правого поддерева произвольного узла X значения ключей данных больше либо равны, нежели значение ключа данных самого узла X.
Очевидно, данные в каждом узле должны обладать ключами, на которых определена операция сравнения меньше.
Как правило, информация, представляющая каждый узел, является записью, а не единственным полем данных. Однако это касается реализации, а не природы двоичного дерева поиска.
Для целей реализации двоичное дерево поиска можно определить так:
- Двоичное дерево состоит из узлов (вершин) — записей вида (data, left, right), где data — некоторые данные, привязанные к узлу, left и right — ссылки на узлы, являющиеся детьми данного узла — левый и правый сыновья соответственно. Для оптимизации алгоритмов конкретные реализации предполагают также определения поля parent в каждом узле (кроме корневого) — ссылки на родительский элемент.
- Данные (data) обладают ключом (key), на котором определена операция сравнения «меньше». В конкретных реализациях это может быть пара (key, value) — (ключ и значение), или ссылка на такую пару, или простое определение операции сравнения на необходимой структуре данных или ссылке на неё.
- Для любого узла X выполняются свойства дерева поиска: key[left[X]]
Содержание
Основные операции в двоичном дереве поиска [ править | править код ]
Базовый интерфейс двоичного дерева поиска состоит из трёх операций:
- FIND(K) — поиск узла, в котором хранится пара (key, value) с key = K.
- INSERT(K, V) — добавление в дерево пары (key, value) = (K, V).
- REMOVE(K) — удаление узла, в котором хранится пара (key, value) с key = K.
Этот абстрактный интерфейс является общим случаем, например, таких интерфейсов, взятых из прикладных задач:
- «Телефонная книжка» — хранилище записей (имя человека, его телефон) с операциями поиска и удаления записей по имени человека и операцией добавления новой записи.
- Domain Name Server — хранилище пар (доменное имя, IP адрес) с операциями модификации и поиска.
- Namespace — хранилище имён переменных с их значениями, возникающее в трансляторах языков программирования.
По сути, двоичное дерево поиска — это структура данных, способная хранить таблицу пар (key, value) и поддерживающая три операции: FIND, INSERT, REMOVE.
Кроме того, интерфейс двоичного дерева включает ещё три дополнительных операции обхода узлов дерева: INFIX_TRAVERSE, PREFIX_TRAVERSE и POSTFIX_TRAVERSE. Первая из них позволяет обойти узлы дерева в порядке неубывания ключей.
Поиск элемента (FIND) [ править | править код ]
Дано: дерево Т и ключ K.
Задача: проверить, есть ли узел с ключом K в дереве Т, и если да, то вернуть ссылку на этот узел.
- Если дерево пусто, сообщить, что узел не найден, и остановиться.
- Иначе сравнить K со значением ключа корневого узла X.
- Если K=X, выдать ссылку на этот узел и остановиться.
- Если K>X, рекурсивно искать ключ K в правом поддереве Т.
- Если K Добавление элемента (INSERT) [ править | править код ]
Дано: дерево Т и пара (K, V).
Задача: вставить пару (K, V) в дерево Т (при совпадении K, заменить V).
- Если дерево пусто, заменить его на дерево с одним корневым узлом ((K, V), null, null) и остановиться.
- Иначе сравнить K с ключом корневого узла X.
- Если K>X, рекурсивно добавить (K, V) в правое поддерево Т.
- Если K Удаление узла (REMOVE) [ править | править код ]
Дано: дерево Т с корнем n и ключом K.
Задача: удалить из дерева Т узел с ключом K (если такой есть).
- Если дерево T пусто, остановиться;
- Иначе сравнить K с ключом X корневого узла n.
- Если K>X, рекурсивно удалить K из правого поддерева Т;
- Если K right->left)
- Копируем из правого узла в удаляемый поля K, V и ссылку на правый узел правого потомка.
Обход дерева (TRAVERSE) [ править | править код ]
Есть три операции обхода узлов дерева, отличающиеся порядком обхода узлов.
Первая операция — INFIX_TRAVERSE — позволяет обойти все узлы дерева в порядке возрастания ключей и применить к каждому узлу заданную пользователем функцию обратного вызова f, операндом которой является адрес узла. Эта функция обычно работает только с парой (K, V), хранящейся в узле. Операция INFIX_TRAVERSE может быть реализована рекурсивным образом: сначала она запускает себя для левого поддерева, потом запускает данную функцию для корня, потом запускает себя для правого поддерева.
- INFIX_TRAVERSE (tr) — обойти всё дерево, следуя порядку (левое поддерево, вершина, правое поддерево). Элементы по возрастанию
- PREFIX_TRAVERSE (tr) — обойти всё дерево, следуя порядку (вершина, левое поддерево, правое поддерево). Элементы, как в дереве
- POSTFIX_TRAVERSE (tr) — обойти всё дерево, следуя порядку (левое поддерево, правое поддерево’, вершина). Элементы в обратном порядке, как в дереве
В других источниках эти функции именуются inorder, preorder, postorder соответственно [1]
Дано: дерево Т и функция f
Задача: применить f ко всем узлам дерева Т в порядке возрастания ключей
- Если дерево пусто, остановиться.
- Иначе
- Рекурсивно обойти левое поддерево Т.
- Применить функцию f к корневому узлу.
- Рекурсивно обойти правое поддерево Т.
В простейшем случае функция f может выводить значение пары (K, V). При использовании операции INFIX_TRAVERSE будут выведены все пары в порядке возрастания ключей. Если же использовать PREFIX_TRAVERSE, то пары будут выведены в порядке, соответствующем описанию дерева, приведённого в начале статьи.
Разбиение дерева по ключу [ править | править код ]
Операция «разбиение дерева по ключу» позволяет разбить одно дерево поиска на два: с ключами Объединение двух деревьев в одно [ править | править код ]
Обратная операция: есть два дерева поиска, у одного ключи Балансировка дерева [ править | править код ]
Всегда желательно, чтобы все пути в дереве от корня до листьев имели примерно одинаковую длину, то есть чтобы глубина и левого, и правого поддеревьев была примерно одинакова в любом узле. В противном случае теряется производительность.
В вырожденном случае может оказаться, что всё левое дерево пусто на каждом уровне, есть только правые деревья, и в таком случае дерево вырождается в список (идущий вправо). Поиск (а значит, и удаление и добавление) в таком дереве по скорости равен поиску в списке и намного медленнее поиска в сбалансированном дереве.
Для балансировки дерева применяется операция «поворот дерева». Поворот налево выглядит так:

- было Left(A) = L, Right(A) = B, Left(B) = C, Right(B) = R
- поворот меняет местами A и B, получая Left(A) = L, Right(A) = C, Left(B) = A, Right(B) = R
- также меняется в узле Parent(A) ссылка, ранее указывавшая на A, после поворота она указывает на B.
Поворот направо выглядит так же, достаточно заменить в вышеприведенном примере все Left на Right и обратно. Достаточно очевидно, что поворот не нарушает упорядоченность дерева и оказывает предсказуемое (+1 или −1) влияние на глубины всех затронутых поддеревьев. Для принятия решения о том, какие именно повороты нужно совершать после добавления или удаления, используются такие алгоритмы, как «красно-чёрное дерево» и АВЛ. Оба они требуют дополнительной информации в узлах — 1 бит у красно-чёрного или знаковое число у АВЛ. Красно-чёрное дерево требует не более двух поворотов после добавления и не более трёх после удаления, но при этом худший дисбаланс может оказаться до 2 раз (самый длинный путь в 2 раза длиннее самого короткого). АВЛ-дерево требует не более двух поворотов после добавления и до глубины дерева после удаления, но при этом идеально сбалансировано (дисбаланс не более, чем на 1).
По книге Laszlo
"Вычислительная геометрия и компьютерная графика на С++"
Двоичные деревья

Двоичные деревья представляют эффективный способ поиска. Двоичное дерево представляет собой структурированную коллекцию узлов. Коллекция может быть пустой и в этом случае мы имеем пустое двоичное дерево. Если коллекция непуста, то она подразделяется на три раздельных семейства узлов: корневой узел n (или просто корень), двоичное дерево, называемое левым поддеревом для n, и двоичное дерево, называемое правым поддеревом для n. На рис. 1а узел, обозначенный буквой А, является корневым, узел В называется левым потомком А и является корнем левого поддерева А, узел С называется правым потомком А и является корнем правого поддерева А.
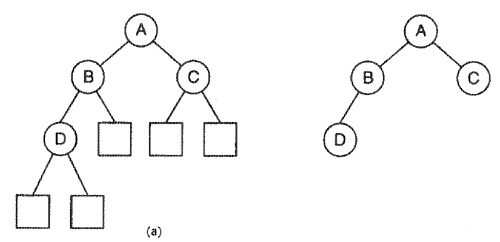
Двоичное дерево на рис. 1а состоит из четырех внутренних узлов (обозначенных на рис. кружками) и пяти внешних (конечных) узлов (обозначены квадратами). Размер двоичного дерева определяется числом содержащихся в нем внутренних узлов. Внешние узлы соответствуют пустым двоичным деревьям. Например, левый потомок узла В — непустой (содержит узел D), тогда как правый потомок узла В — пустое дерево. В некоторых случаях внешние узлы обозначаются каким-либо образом, в других — на них совсем не ссылаются и они считаются пустыми двоичными деревьями (на рис. 16 внешние узлы не показаны).
Основанная на генеалогии метафора дает удобный способ обозначения узлов внутри двоичного дерева. Узел р является родителем (или предком) узла n, если n — потомок узла р. Два узла являются братьями, если они принадлежат одному и тому же родителю. Для двух заданных узлов n1 и nk таких, что узел nk принадлежит поддереву с корнем в узле n1, говорят, что узел nk является потомком узла n1, а узел n1 — предком узла nk. Существует уникальный путь от узла n1 вниз к каждому из потомков nk, a именно: последовательность узлов n1 и n2. nk такая, что узел ni является родителем узла ni+1 для i = 1, 2. k-1. Длина пути равна числу ребер (k-1), содержащихся в нем. Например, на рис. 1а уникальный путь от узла А к узлу D состоит из последовательности А, В, D и имеет длину 2.
Глубина узла n определяется рекурсивно:
| < 0 | если n — корневой узел |
| глубина (n) = | < |
| < 1 + глубина (родителя (n)) | в противном случае |
Глубина узла равна длине уникального пути от корня к узлу. На рис. 1а узел А имеет глубину 0, а узел D имеет глубину, равную 2.
Высота узла n также определяется рекурсивно:
| < 0 | если n — внешний узел |
| высота (n) = | < |
| < 1 + max( высота(лев(n)), высота(прав(n)) ) | в противном случае |
где через лев(n) обозначен левый потомок узла n и через прав(n) — правый потомок узла n. Высота узла n равна длине самого длинного пути от узла n вниз до внешнего узла поддерева n. Высота двоичного дерева определяется как высота его корневого узла. Например, двоичное дерево на рис. 1а имеет высоту 3, а узел D имеет высоту 1.
При реализации двоичных деревьев, основанной на точечном представлении, узлы являются объектами класса TreeNode.
Элементы данных _lchild и _rchild обозначают связи текущего узла с левым и правым потомками соответственно, а элемент данных val содержит сам элемент.
Конструктор класса формирует двоичное дерево единичного размера — единственный внутренний узел имеет два пустых потомка, каждое из которых представлено нулем NULL:
TreeNode рекурсивно удаляет оба потомка текущего узла (если они существуют) перед уничтожением самого текущего узла:
Двоичные деревья поиска
Основное назначение двоичных деревьев заключается в повышении эффективности поиска. При поиске выполняются такие операции, как нахождение заданного элемента из набора различных элементов, определение наибольшего или наименьшего элемента в наборе, фиксация факта, что набор содержит заданный элемент. Для эффективного поиска внутри двоичного дерева его элементы должны быть организованы соответствующим образом. Например, двоичное дерево будет называться двоичным деревом поиска, если его элементы расположены так, что для каждого элемента n все элементы в левом поддереве n будут меньше, чем n, а все элементы в правом поддереве — будут больше, чем n. На рис. 2 изображены три двоичных дерева поиска, каждое из которых содержит один и тот же набор целочисленных элементов.
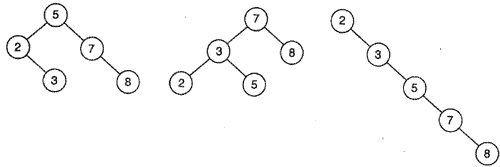
В общем случае существует огромное число двоичных деревьев поиска (различной формы) для любого заданного набора элементов.
Предполагается, что элементы располагаются в линейном порядке и, следовательно, любые два элемента можно сравнить между собой. Примерами линейного порядка могут служить ряды целых или вещественных чисел в порядке возрастания, а также слов или строк символов, расположенных в лексикографическом (алфавитном, или словарном) порядке. Поиск осуществляется путем обращения к функции сравнения для сопоставления любых двух элементов относительно их линейного порядка. В нашей версии деревьев поиска действие функции сравнения ограничено только явно определенными объектами деревьев поиска.
Также очень полезны функции для обращения к элементам дерева поиска и воздействия на них. Такие функции обращения могут быть полезны для вывода на печать, редактирования и доступа к элементу или воздействия на него каким-либо иным образом. Функции обращения не принадлежат деревьям поиска, к элементам одного и того же дерева поиска могут быть применены различные функции обращения.
Класс SearchTree (дерево поиска)
Определим шаблон нового класса SearchTree для представления двоичного дерева поиска. Класс содержит элемент данных root, который указывает на корень двоичного дерева поиска (объект класса TreeNode) и элемент данных cmp, который указывает на функцию сравнения.
Для упрощения реализации предположим, что элементами в дереве поиска являются указатели на объект заданного типа, когда шаблон класса SearchTree используется для создания действительного класса. Параметр Т передается в виде типа указателя.
Конструкторы и деструкторы
Конструктор SearchTree инициализирует элементы данных cmp для функции сравнения и root для пустого дерева поиска:
Дерево поиска пусто только, если в элементе данных root содержится нуль (NULL) вместо разрешенного указателя:
Деструктор удаляет все дерево путем обращения к деструктору корня:
Поиск
Чтобы найти заданный элемент val, мы начинаем с корня и затем следуем вдоль ломаной линии уникального пути вниз до узла, содержащего val. В каждом узле n вдоль этого пути используем функцию сравнения для данного дерева на предмет сравнения val с элементом n->val, записанном в n. Если val меньше, чем n->val, то поиск продолжается, начиная с левого потомка узла n, если val больше, чем n->val, то поиск продолжается, начиная с правого потомка n, в противном случае возвращается значение n->val (и задача решена). Путь от корневого узла вниз до val называется путем поиска для val.
Этот алгоритм поиска реализуется в компонентной функции find, которая возвращает обнаруженный ею указатель на элемент или NULL, если такой элемент не существует в дереве поиска.
Этот алгоритм поиска можно сравнить с турниром, в котором участвуют некоторые кандидаты. В начале, когда мы начинаем с корня, в состав кандидатов входят все элементы в дереве поиска. В общем случае для каждого узла n в состав кандидатов входят все потомки n. На каждом этапе производится сравнение val с n->val. Если val меньше, чем n->val, то состав кандидатов сужается до элементов, находящихся в левом поддереве, а элементы в правом поддереве n, как и сам элемент n->val, исключаются из соревнования. Аналогичным образом, если val больше, чем n->val, то состав кандидатов сужается до правого поддерева n. Процесс продолжается до тех пор, пока не будет обнаружен элемент val или не останется ни одного кандидата, что означает, что элемент val не существует в дереве поиска.
Для нахождения наименьшего элемента мы начинаем с корня и прослеживаем связи с левым потомком до тех пор, пока не достигнем узла n, левый потомок которого пуст — это означает, что в узле n содержится наименьший элемент. Этот процесс также можно уподобить турниру. Для каждого узла n состав кандидатов определяется потомками узла n. На каждом шаге из состава кандидатов удаляются те элементы, которые больше или равны n->val и левый потомок n будет теперь выступать в качестве нового n. Процесс продолжается до тех пор, пока не будет достигнут некоторый узел n с пустым левым потомком и, полагая, что не осталось кандидатов меньше, чем n->val, и будет возвращено значение n->val.
Компонентная функция findMin возвращает наименьший элемент в данном дереве поиска, в ней происходит обращение к компонентной функции _findMin, которая реализует описанный ранее алгоритм поиска, начиная с узла n :
Наибольший элемент в дереве поиска может быть найден аналогично, только отслеживаются связи с правым потомком вместо левого.
Симметричный обход
Обход двоичного дерева — это процесс, при котором каждый узел посещается точно только один раз. Компонентная функция inorder выполняет специальную форму обхода, известную как симметричный обход. Стратегия заключается сначала в симметричном обходе левого поддерева, затем посещения корня и потом в симметричном обходе правого поддерева. Узел посещается путем применения функции обращения к элементу, записанному в узле.
Компонентная функция inorder служит в качестве ведущей функции. Она обращается к собственной компонентной функции _inorder, которая выполняет симметричный обход от узла n и применяет функцию visit к каждому достигнутому узлу.
При симметричном обходе каждого из двоичных деревьев поиска, показанных на рис. 2, узлы посещаются в возрастающем порядке: 2, 3, 5, 7, 8. Конечно, при симметричном обходе любого двоичного дерева поиска все его элементы посещаются в возрастающем порядке. Чтобы выяснить, почему это так, заметим, что при выполнении симметричного обхода в некотором узле n элементы меньше, чем n->val посещаются до n, поскольку они принадлежат к левому поддереву n, а элементы больше, чем n->val посещаются после n, поскольку они принадлежат правому поддереву n. Следовательно, узел n посещается в правильной последовательности. Поскольку n — произвольный узел, то это же правило соблюдается для каждого узла.
Компонентная функция inorder обеспечивает способ перечисления элементов двоичного дерева поиска в отсортированном порядке. Например, если а является деревом поиска SearchTree для строк, то эти строки можем напечатать в лексикографическом порядке одной командой а.inorder(printstring). Для этого функция обращения printstring может быть определена как:
При симметричном обходе двоичного дерева узел, посещаемый после некоторого узла n, называется последователем узла n, а узел, посещаемый непосредственно перед n, называется предшественником узла n. Не существует никакого предшественника для первого посещаемого узла и никакого последователя для последнего посещаемого узла (в двоичном дереве поиска эти узлы содержат наименьший и наибольший элемент соответственно).
Включение элементов
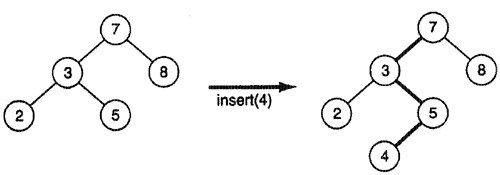
Для включения нового элемента в двоичное дерево поиска вначале нужно определить его точное положение — а именно внешний узел, который должен быть заменен путем отслеживания пути поиска элемента, начиная с корня. Кроме сохранения указателя n на текущий узел мы будем хранить указатель р на предка узла n. Таким образом, когда n достигнет некоторого внешнего узла, р будет указывать на узел, который должен стать предком нового узла. Для осуществления включения узла мы создадим новый узел, содержащий новый элемент, и затем свяжем предок р с этим новым узлом (рис. 3).
Компонентная функция insert включает элемент val в это двоичное дерево поиска:
Удаление элементов
Удаление элемента из двоичного дерева поиска гораздо сложнее, чем включение, поскольку может быть значительно изменена форма дерева. Удаение узла, у которого есть не более чем один непустой потомок, является равнительно простой задачей — устанавливается ссылка от предка узла на потомок. Однако ситуация становится гораздо сложнее, если у подлежащего удалению узла есть два непустых потомка: предок узла может быть связан с одним из потомков, а что делать с другим? Решение может заключаться не в удалении узла из дерева, а скорее в замене элемента, содержащегося в нем, на последователя этого элемента, а затем в удалении узла, содержащего этот последователь.
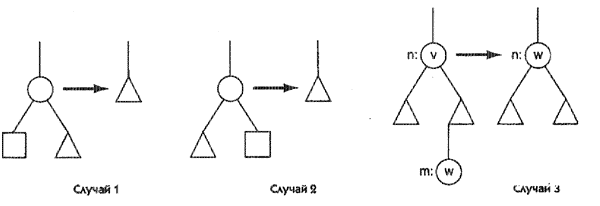
Чтобы удалить элемент из дерева поиска, вначале мы отслеживаем путь поиска элемента, начиная с корня и вниз до узла n, содержащего элемент. В этот момент могут возникнуть три ситуации, показанные на рис. 4:
- Узел n имеет пустой левый потомок. В этом случае ссылка на n (записанная в предке n, если он есть) заменяется на ссылку на правого потомка n.
- У узла n есть непустой левый потомок, но правый потомок пустой. В этом случае ссылка вниз на n заменяется ссылкой на левый потомок узла n.
- Узел n имеет два непустых потомка. Найдем последователя для n (назовем его m), скопируем данные, хранящиеся в m, в узел n и затем рекурсивно удалим узел m из дерева поиска.
Очень важно проследить, как будет выглядеть результирующее двоичное дерево поиска в каждом случае. Рассмотрим случай 1. Если подлежащий удалению узел n, является левым потомком, то элементы, относящиеся к правому поддереву n будут меньше, чем у узла р, предка узла n. При удалении узла n его правое поддерево связывается с узлом р и элементы, хранящиеся в новом левом поддереве узла р конечно остаются меньше элемента в узле р. Поскольку никакие другие ссылки не изменяются, то дерево остается двоичным деревом поиска. Аргументы остаются подобными, если узел n является правым потомком, и они тривиальны, если n — корневой узел. Случай 2 объясняется аналогично. В случае 3 элемент v, записанный в узле n, перекрывается следующим большим элементом, хранящимся в узле m (назовем его w), после чего элемент w удаляется из дерева. В получающемся после этого двоичном дереве значения в левом поддереве узла n будут меньше w, поскольку они меньше v. Более того, элементы в правом поддереве узла n больше, чем w, поскольку (1) они больше, чем v, (2) нет ни одного элемента двоичного дерева поиска, лежащего между v и w и (3) из них элемент w был удален.
Заметим, что в случае 3 узел m должен обязательно существовать, поскольку правое поддерево узла n непустое. Более того, рекурсивный вызов для удаления m не может привести к срыву рекурсивного вызова, поскольку если узел m не имел бы левого потомка, то был бы применен случай 1, когда его нужно было бы удалить.
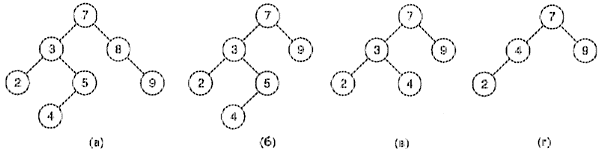
На рис. 5 показана последовательность операций удаления, при которой возникают все три ситуации. Напомним, что симметричный обход каждого дерева в этой последовательности проходит все узлы в возрастающем порядке, проверяя, что в каждом случае это двоичные деревья поиска.
Компонентная функция remove является общедоступной компонентной функцией для удаления узла, содержащего заданный элемент. Она обращается к собственной компонентной функции _remove, которая выполняет фактическую работу:
Параметр n (типа ссылки) служит в качестве псевдонима для поля ссылки, которое содержит ссылку вниз на текущий узел. При достижении узла, подлежащего удалению (old), n обозначает поле ссылки (в предке узла old), содержащее ссылку вниз на old. Следовательно команда n=old->_rchild заменяет ссылку на old ссылкой на правого потомка узла old.
Компонентная функция removeMin удаляет из дерева поиска наименьший элемент и возвращает его:
Древовидная сортировка — способ сортировки массива элементов — реализуется в виде простой программы, использующей деревья поиска. Идея заключается в занесении всех элементов в дерево поиска и затем в интерактивном удалении наименьшего элемента до тех пор, пока не будут удалены все элементы. Программа heapSort(пирамидальная сортировка) сортирует массив s из n элементов, используя функцию сравнения cmp:
Также доступна реализация двоичного дерева на Си с базовыми функциями. Операторы typedef T и compGT следует изменить так, чтобы они соответствовали данным, хранимым в дереве. Каждый узел Node содержит указатели left, right на левого и правого потомков, а также указатель parent на предка. Собственно данные хранятся в поле data. Адрес узла, являющегося корнем дерева хранится в укзателе root, значение которого в самом начале, естественно, NULL. Функция insertNode запрашивает память под новый узел и вставляет узел в дерево, т.е. устанавливает нужные значения нужных указателей. Функция deleteNode, напротив, удаляет узел из дерева (т.е. устанавливает нужные значения нужных указателей), а затем освобождает память, которую занимал узел. Функция findNode ищет в дереве узел, содержащий заданное значение.
Я искал, как рассчитать высоту дерева двоичного поиска, и мои исследования привели меня к следующей реализации. Я все еще пытаюсь обернуть голову, почему это должно работать, но я также не уверен, почему это не работает. Вот моя функция роста.
и вот мое определение класса для узла
Когда я пытаюсь запустить его, моя программа зависает и вылетает. Я что-то упускаю из виду?
РЕДАКТИРОВАТЬ: Почему это не должно работать?
Решение
Ваше дерево не бесконечно. Итак, я предполагаю, что некоторые узлы не имеют левого или правого потомка, и указатели left и / или right являются нулевыми в этом случае. Вы должны проверить их существование, прежде чем пытаться их использовать.
Попробуйте эту функцию вместо:
Примечание: я упростил ваши вычисления высоты.
Другие решения
Проблема в том, что ваша функция никогда не проверяет, являются ли дочерние указатели NULL поэтому, кроме разыменования недопустимого указателя, у вас есть рекурсивная функция, которая пропускает базовый случай:
Попробуйте эту версию:
Даже когда я сталкивался с той же проблемой, проблема с вашим кодом заключается в том, что в вашей функции вы дважды используете рекурсию и идете к левой и правой конечностям, но вы не проверяете возможность, если правый потомок одного из родителей узел в левом поддереве имеет своих дочерних элементов, поэтому вы не переходите к последнему листовому узлу в своем дереве! надеюсь это поможет