Содержание
Воспользуйтесь бесплатным доступом к архиву интернет
ВВЕДИТЕ АДРЕС СТРАНИЦЫ, ЧТОБЫ УВИДЕТЬ ЕЕ АРХИВНЫЕ КОПИИ:
Архив интернет (Web archive) – это бесплатный сервис по поиску архивных копий сайтов. С помощью данного сервиса вы можете проверить внешний вид и содержимое страницы в сети интернет на определенную дату.
Информацию из Вебархива вы можете использовать в ознакомительных целях, либо для доказывания определенных обстоятельств в суде. В данном случае рекомендуем вам надлежащим образом зафиксировать или нотариально заверить найденную архивную копию страницы сайта.
История интернет архива, описание проекта, награды и блокировка
The Wayback Machine – это архив интернета (Internet Archive). По сути это некоммерческая организация, которая была основана в 1996 году. Задачей данной организации является сбор и хранение всевозможной публичной информации собранной из интернета: веб-страницы, электронные книги, фото- и, видео материалы. Основные сервера расположены в Сан-Франциско. Размер архива на февраль 2017 года составляет 13 петабайт и включает в себя 525 миллиардов копий веб-страниц.

Краткая история Archive.org
Основателем является Брюстер Кейл, который основал организацию в 1996 году. В том же оду начал процесс по архивации веб страниц. Проект назывался Wayback Machine. По сей день сохраненные копии доступны любому пользователю посетившему сайт.
Расширение организации в 1999 году, ознаменовалось хранением не только веб-страниц, но и видео, аудио, изображения и даже программное обеспечение.
Здравствуйте, уважаемые читатели блога KtoNaNovenkogo.ru. Не так давно я писал про то, что такое народная энциклопедия Википедия, которая безусловно заслуживает всяких лестных эпитетов, несмотря на присущие ей небольшие недостатки и критику ее статей со стороны научного сообщества.
Сам факт того, что некоммерческий проект уже не одно десятилетие трудится на благо всего интернет сообщества, заслуживает огромного уважения. Но в сети есть еще подобный масштабный проект, который не получая с этого дохода выполняет очень важную роль — сохраняет архивы сайтов, видео, аудио и печатной продукции.

Я говорю, конечно же, про web.archive.org — глобальный проект с казалось бы невыполнимой миссией — создание архива всех сайтов, когда либо размещенных в интернете. Причем, сайты сохраняются не в виде скриншотов, а в виде полноценно работающих веб-страниц со всеми ссылками, картинками и стилевым оформлением (CSS). Причем, для каждого сайта за время его существования в сети в этом архиве может накопиться и по несколько сотен копий, датированных разными этапами жизни ресурса.
Как можно использовать архив сайтов интернета
Чем же может быть полезен данный webarchive?
- Ну, во-первых, вы можете погрузиться в приятную ностальгию путешествуя по вашему сайту многолетней давности. Проследить историю изменений можно будет для любого другого ресурса интернета (например, я брал скриншоты для статей про уже умерший Апорт именно из это вебархива, да и скриншоты, иллюстрирующие эволюцию главной страницы Яндекса, имеют тоже самое происхождение).
- Но это не все. Если страница добавленного вами в закладки сайта не открывается, то вы, конечно же, можете попробовать вытащить ее из кеша Яндекса или Гугла (читайте подробнее про то, как лучше искать в Google). Но если ресурс недоступен уже очень давно, то такие мертвые ссылки нигде кроме archive.org открыть уже будет не возможно (правда, и там его может не оказаться по описанным чуть ниже причинам).
- Так же, если вы по каким-либо форс-мажорным обстоятельствам не делали бэкап (резервное копирование) вашего сайта, то данный web archive будет единственной возможностью восстановить свой сайт. Имеется возможность очистить все ссылки от привязки к web.archive.org и сделать их прямыми именно для вашего ресурса (читайте об этом ниже).
Ну, и последнее, что приходит в голову — поиск уникального контента. Если вы не способны сами создавать уникальный контента для сайта (писать статьи), то здесь вы сможете ими разжиться, правда, усилия приложить все равно придется. Суть такова, что многие сайты умирают и становятся недоступны вместе с имеющимся на них контентом.
Отыскав такие ресурсы вы сможете вытащить тексты из интернет-архива и разместить их у себя, предварительно проверив их на уникальность. Таким образом вы не занимаетесь плагиатом и не нарушаете авторские права (копирайт), но искать в вебархиве многим может показаться очень уж трудоемкой задачей.
Онлайн сервис Webarchive ведет свою историю аж с 1996 года. Поставленная перед проектом задача казалась невыполнимой даже с учетом того, что сайтов на то время в интернете было значительно меньше, чем сейчас (на несколько порядков). По началу, сайты архивировались не очень часто, но со временем, повышая мощности хранилищ, Веб-архив стал делать все больше и больше слепков сайтов.
Сам себя этот веб архив занес в базу лишь в 1997 году и выглядела его главная страница тогда так:
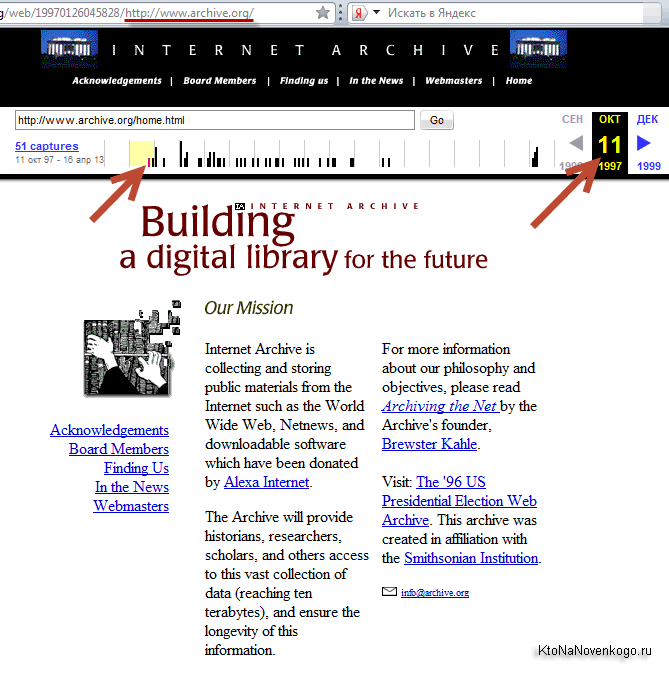
Сейчас на все про все (включая аудио, видео и отсканированные книги) у этой некоммерческой организации задействовано дисковое пространство чудовищных размеров, измеряемое десяткой с пятнадцатью нулями байт. Сайт имеет зеркала в различных дата центрах, а сам проект с недавних пор получил официальный статус библиотеки. Если рассматривать только архив страниц сайтов, то их уже там насчитывается около ста миллиардов (тут учитываются все слепки страниц когда-либо снятые и сохраненные).
На главной странице доступен не только архив страниц интернета Wayback Machine, но и архивы различных кинохроник, телепередач, аудио записей и отсканированных в различных библиотеках книг:
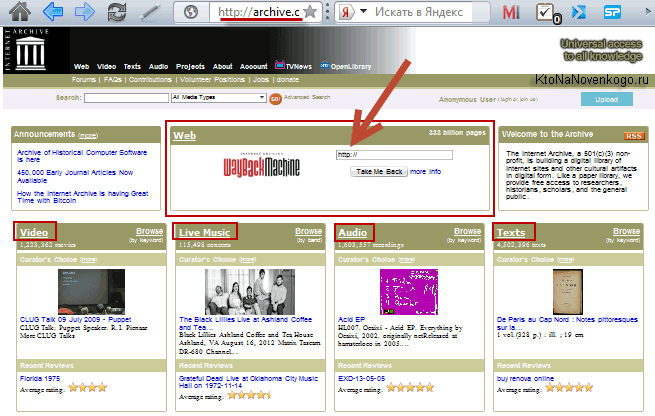
Но нас интересует именно область WEB с логотипом Wayback Machine. В расположенную там форму можно ввести URL или доменное имя интересующего вас сайта (читайте про то, что такое домен и чем он отличается от URL), чтобы попасть на страницу с календарем:
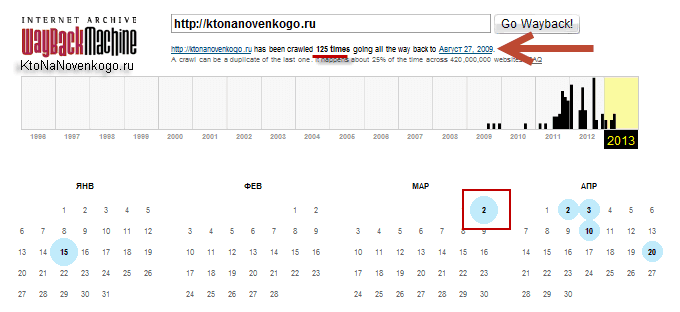
Из приведенного примера видно, что мой блог был впервые архивирован 27 августа 2009 года (через пять дней после регистрации (покупки) домена ktonanovenkogo.ru). За прошедший интервал времени было создано 125 архивных копий сайта, каждую из которым можно будет посмотреть и потрогать руками (осуществляя переходы по внутренним ссылкам).
Открытие мертвых ссылок и условия попадания сайта в archive.org
В календаре голубыми кружочками отмечены даты, в которые был создан слепок (вебархив) данного сайта. Естественно, что моменты снятия слепка никак не будет коррелироваться с производимыми на вашем ресурсе изменениями, и их время Webarchive определяет строго исходя из своих внутренних алгоритмов и таймеров.
Поэтому использовать архив интернета, как инструмент для открытия временно недоступных сайтов, наверное, не всегда будет резонным. Для этого у Яндекса имеется возможность просмотра архивной копии документа:

Да, и в Google можно всегда посмотреть сохраненную копию веб-страницы:

Данный же онлайн сервис понадобится в особо тяжелых случаях, когда искомая страница уже не существует и вряд ли уже будет существовать в реальном интернете, но зато она по прежнему будет доступна в машине времени.
Правда, тут должно быть соблюдено несколько условий того, чтобы сайт попал в archive.org:
Он не должен содержать в своем файле robots.txt запрет для его индексации роботом с web.archive.org. Такой запрет, обычно выглядит так:
Когда я писал статью про электронную почту mail.ru, то не смог найти в Архиве Интернета сохраненных копий сайта mail.ru, т.к. его файл robots.txt содержал в себе похожий запрет:

Как найти нужный веб-архив и восстановить сайт без бекапа
По архивам можно перемещаться и с помощью временной шкалы расположенной вверху страницы, где вертикальными черными черточками отмечены имеющиеся для этого сайта слепки. Иногда, веб-архивы могут быть битыми, тогда придется открыть ближайший к нему слепок.
Щелкнув по голубому кружочку мы можем увидеть ссылки на несколько архивов, отличающихся временем их снятия.
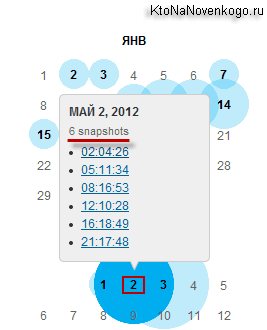
Возможно, что это делается во избежании потери данных за счет неизбежной порчи жестких дисков в хранилищах. Перейдя к просмотру одного из веб-архивов, вы увидите копию своего (в данном примере моего) сайта с работающими внутренними ссылками и подключенным стилевым оформлением. Правда, не идеально работающим.
Например, кое-что из дизайна у меня все же перекосило и боковое меню работающее на ДжаваСкрипте полностью исчезло:
Но это не столь важно, ибо в исходном коде страницы с web.archive.org это меню, естественно, присутствует. Однако, просто так скопировать текст этой страницы к себе на сайт взамен утерянной не получится. Почему? Да потому что путешествие внутри сайта из прошлого будет возможно лишь в случае замены всех внутренних ссылок на те, что генерит Webarchive (в противном случае вас перебросило бы на современную версию ресурса).
Выглядят эти ссылки примерно так:
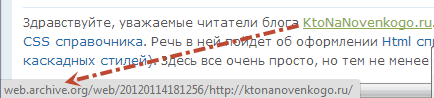
Понятно, что можно будет вручную отсечь вступительную часть ссылок ( http://web.archive.org/web/20111013120145/ ), получив таким образом рабочий вариант. Можно этот процесс даже автоматизировать с помощью инструмента поиска и замены редактора Notepad, но еще проще будет воспользоваться встроенной в этот сервис возможностью замены внутренних ссылок на оригинальные.
Для этого копируете адрес страницы с нужным слепком вашего сайта (из адресной строки браузера — начинается с http://web.archive.org/ ). Он будет иметь примерно такой вид:
И вставляете в него конструкцию «id_» в конце даты ( 20111013120145 ), чтобы получилось так:
Теперь измененный адрес обратно возвращаете в адресную строку браузера и жмете на Enter. После этого страница c архивом вашего сайта обновится и все внутренние ссылки станут прямыми. Можно будет копировать текст статьи из исходного кода вебархива.
Понятно, что восстановление таким образом огромного сайта займет чудовищное количество времени, но когда другого варианта нет, то и такой покажется манной небесной. К тому же, страдают невозвратной потерей контента обычно только начинающие вебмастера, у которых этого самого контента было мало, а более-менее опытные сайтовладельцы, уж не раз обжигавшиеся на подобных вещах, делают бэкапы файлов и базы по пять раз на дню.
Если вы захотите увидеть все страницы вашего (или чужого) сайта, которые содержатся в недрах этого мастодонта, то вам нужно будет вставить в адресную строку браузера следующий адрес и нажать Enter:
Вместо моего домена можно использовать свой. На открывшейся странице вы получите возможность наложить фильтр в предназначенной для этого форме:
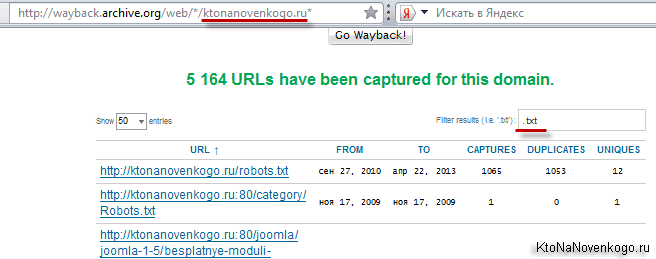
Например, я захотел увидеть лишь текстовые файлы своего блога, которые заглотил Web Archive. Зачем — не знаю, но захотел.
Как вытянуть из Webarchive уникальный контент для сайта
Описанный ниже способ лично я не использовал, но чисто теоретически все должно работать. Саму идею я почерпнул на этом молодом ресурсе, где и были описаны все шаги. Принцип метода состоит в том, что каждый день умирают и никогда не возрождаются десятки сайтов.
Причин этому может быть много и большинство из почивших в бозе ресурсов никакой особой ценности в плане контента никогда и не представляли. Но из всякого правила бывают исключения и нужно будет всего-навсего отделить зерна от плевел. Главное чтобы исчезнувшие сайты с более-менее удобоваримым контентом были бы представлены в Web Archive, хотя бы одной копией.
Т.к. после смерти контент этих сайтов постепенно выпадет из индекса поисковых систем, то взяв его из интернет-архива вы, по идее, станете его законным владельцем и первоисточником для поисковых систем. Замечательно, если будет именно так (есть вариант, что еще при жизни ресурса его нещадно могли откопипастить). Но кроме проблемы уникальности текстов, существует проблема их отыскания.
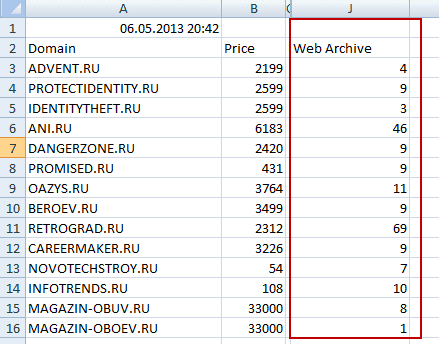
Во-первых, нам нужен список сайтов, которые скоро умрут или уже померли. Автор метода предлагает скачать с сайта регистратора доменных имен Nic.ru список освобождающихся или уже освободившихся доменов.
Что примечательно, в последней колонке этого списка (его можно открыть в Excel) будет отображаться количество архивов, созданных для каждого сайта в Web Archive (правда, проверить наличие домена в веб-архиве можно и в ряде онлайн сервисов).
Список буржуйских доменных имен, освобождающихся или уже освободившихся, предлагается скачать по этой ссылке. Ну, а дальше просматриваем содержимое сайтов, которое сохранил Web Archive и пытаемся найти что-то стоящее. Потом проверяем уникальность этих материалов (ссылку приводил чуть выше) и в случае удачи публикуем их на своем ресурсе, либо продаем в какой-нибудь бирже контента.
Да, способ муторный и мною лично не проверенный. Но, думаю, что при некоторой степени автоматизации и обмозговывания он может давать неплохой выхлоп. Наверное, кто-нибудь уже это поставил на поток. А вы как думаете?