Содержание
- 1 Как работает ИНДЕКСИРОВАТЬ ПО?
- 2 Где и как нужно использовать ИНДЕКСИРОВАТЬ ПО ?
- 3 1. Чтение данных с диска
- 4 2. Поиск данных в MySQL
- 5 3. Сортировка данных
- 6 4. Выбор индексов в MySQL
- 7 5. Составные индексы
- 8 6. Использование EXPLAIN для анализа индексов
- 9 7. Селективность индексов
- 10 8. Первичные ключи
- 11 Overhead
- 12 Когда создавать индексы?
- 13 Самое важное
Разработчики 1С очень часто игнорируют использование конструкции «ИНДЕКСИРОВАТЬ ПО» в запросе.
Зачем нужно индексировать поля в запросе 1С 8.3, я расскажу ниже.

Как работает ИНДЕКСИРОВАТЬ ПО?
Индексация в запросе нужна для более быстрого формирования результате запроса. Как это работает? Система строит индекс для временной таблицы, чтобы быстрее найти нужное значение.
Т.е. система работает точно так же, как и обычные индексы 1С, только для временной таблицы.
Где и как нужно использовать ИНДЕКСИРОВАТЬ ПО ?
Конструкцию рекомендуется использовать по полям временных таблиц, по которым эта временная таблица будет соединяться с другими таблицами баз данных. Это существенно повышает скорость выполнения соединения таблиц.
Однако следует учесть один момент. Построение индекса временной таблицы также требует времени на выполнение. Поэтому целесообразно использовать конструкцию «ИНДЕКСИРОВАТЬ ПО», только если Вы знаете, что во временной таблице будет не 1-2 записи. В противном случае эффект может быть обратным — быстродействие от индексированных полей не компенсирует времени построения индекса.
- 5
- 4
- 3
- 2
- 1
( голосов, в среднем: из 5)
Поддержите нас, расскажите друзьям!
СПРОСИТЕ в комментариях!
1. Что значит «рекомендуется использовать по полям временных таблиц, по которым эта временная таблица будет соединяться с другими таблицами баз данных»? У меня есть левое соединение где в правой части — таблица базы данных. Зачем индексировать временную таблицу если при выборке будет проводиться поиск в правой таблице? То есть индекс временной таблицы в данном случае не функционален.
2. Если я связываю 2 временные таблицы левым соединением, какую таблицу я должен индексировать?
3. В приведённом примере — какой смысл индексировать таблицу по единственному полю, если в индексе получается такое же количество записей как в таблице и (следовательно) обход индекса при выборке занимает примерно столько же времени?
Такое впечатление, что писали статью «чтоб было», не думая.
1. Вы просто индексы готовить не умеете, потому как у Вас поверхностные знания общих принципов применения и работы индексов на платформах БД. Вообще есть определенные стандарты, согласно которым проектировщики платформ БД (вменяемые) следуют, иначе спроса на их платформу не будет.
Так вот ответ на ваш вопрос — раз у вас в левом соединении временная таблица и по ней в самом запросе не идут поиск — значит у вас данные из левой таблицы выводятся в результат запроса (иначе зачем тогда Вам вообще левое соединение). А соответственно соединение по имеющимся записям в левой таблице может идти по ее (левой таблицы) индексу или по поиску (перебору) всех записей этой левой таблицы. И так по каждой строке правой. Да, если записей мало — то результат не так заметен, а то и даже… но когда записей много… Поймите — соединение, какое оно бы ни было — это соединение. И в данном случае можно всю таблицу перебирать, а можно по индексу сработать.
2. Если нужно получить максимально быстро результат выборки, особенно если многократно с этими временными таблицами — то обе. При соединении (не важно каком именно) платформа БД при наличии индекса на поле таблице — работает всегда по индексу. Это всегда быстрее.
3. Автор как раз понимает тему, это Вы не в теме и совершенно не представляете как работают индексы. Да, записей в индексе столько же будет, но принцип работы по индексу совершенно другой. Возможно, если у вас обе таблицы абсолютно аналогично отсортированы по полям соединения — то может и не такой эффект будет — но ведь это как правило не так…
В общем вывод — статью писали думая — это Вы ответили, не подумав…
Прочитав парочку статей, решил собрать их воедино, чтобы получилась по возможности полностью покрывающая данный вопрос статья.
Начну с того, что часто вижу ошибки, связанные с созданием индексов в MySQL. Многие разработчики (и не только новички в MySQL) создают много индексов на тех колонках, которые будут использовать в выборках, и считают это оптимальной стратегией. Например, если мне нужно выполнить запрос типа AGE=18 AND STATE=’CA’, то многие люди просто создадут 2 отдельных индекса на колонках AGE и STATE.
Намного лучшей (здесь и далее прим. переводчика: а обычно и единственной верной) стратегией является создание комбинированного индекса вида (AGE,STATE). Давайте рассмотрим почему это так.
Обычно (но не всегда) индексы в MySQL являются BTREE-индексами — такой тип индекса способна быстро просматривать информацию, содержащуюся в своих префиксах, и перебирать диапазоны отсортированных значений. Например, когда Вы запрашиваете AGE = 18 с BTREE-индексом по колонке AGE MySQL найдёт в таблице первую отвечающую запросу строку и продолжит поиск до тех пор, пока не найдёт первую неподходящую строку — тогда он останавливает поиск, т.к. считает, что дальше ничего подходящего не будет. Диапазоны, например запросы вида BETWEEN 18 AND 20, работают сходным образом — MySQL останавливается на других значениях.
Несколько сложнее ситуация с запросами типа AGE IN (18,20,30), т.к. на самом деле MySQL приходится несколько раз проходить по индексу.
Итак, мы обсудили как MySQL ищет по индексу, но не определили что же он возвращает после поиска — обычно (если речь не идёт о покрывающих (covering) индексах) получает «указатель строки», который может быть значением первичного ключа (если используется движок InnoDB), физическое смещение в файле (для MyISAM) или что-нибудь в этом роде. Важно, что внутренний движок MySQL может по этому указателю найти полную строку со всеми необходимыми данными, отвечающими заданному значению индекса.
А какие есть варианты у MySQL, если Вы создали два отдельных индекса? Он может либо использовать только один из них, чтобы отобрать подходящие строки (а потом отфильтровать извлечённые данные, руководствуясь WHERE — но уже без использования индексов), либо может получить указатели на строки от всех подходящих индексов и вычислить их пересечение, а затем уже вернуть данные.
Какой из способов будет более подходящим зависит от избирательности и корреляции индексов. Если после отработки WHERE по первой колонке будет отобрано 5% строк, а применение далее WHERE по второй колонке отфильтровывает строки до 1% от общего количества, то применение пересечений, конечно, имеет смысл. Но если второй WHERE отфильтрует только до 4.5%, то обычно значительно выгоднее использовать только первый индекс и отфильтровать ненужные нас строки после извлечения данных.
Давайте рассмотрим несколько примеров:
CREATE TABLE ‘idxtest’ (
‘i1’ int(10) UNSIGNED NOT NULL,
‘i2’ int(10) UNSIGNED NOT NULL,
‘val’ varchar(40) DEFAULT NULL,
KEY ‘i1’ (‘i1’),
KEY ‘i2’ (‘i2’),
KEY ‘combined’ (‘i1′,’i2’)
) ENGINE=MyISAM DEFAULT CHARSET=latin1
Я создал колонки i1 и i2 независимыми друг от друга, причём каждая из них отбирает около 1% строк в таблице, которая содержит в общей сложности 10 млн. записей.
mysql> EXPLAIN SELECT avg(length(val)) FROM >
Как Вы можете видеть MySQL предпочёл использовать комбинированный индекс, и запрос выполнился меньше, чем за 10 мс!
А теперь предположим, что у нас есть индекс только по отдельным колонкам (сказать оптимизатору игнорировать комбинированный индекс):
mysql> EXPLAIN SELECT avg(length(val)) FROM >
Как Вы можете видеть в данном случае MySQL выполнил поиск пересечений индексов, а на выполнение запроса понадобилось 70 мс — в 7 раз дольше!
Теперь давайте посмотрим, что будет, если использовать только один индекс и отфильтровывать полученные данные:
mysql> EXPLAIN SELECT avg(length(val)) FROM >
На этот раз MySQL пришлось обойти значительно больше строк, а выполнение запроса заняло 290 мс. Таким образом мы видим, что использование пересечения индексов намного лучше, чем использование одного индекса, но значительно лучше использовать комбинированные индексы.
Однако на этом проблемы с пересечениями индексов не заканчиваются. В настоящее время возможности использования этой процедуры в MySQL значительно ограничены, поэтому MySQL использует их далеко не всегда:
mysql> EXPLAIN SELECT avg(length(val)) FROM >
Как только запрос по одной из колонок становится не сравнением, а перечислением, MySQL больше не сможет использовать пересечение индексов, несмотря на то, что в данном случае при запросе i2 IN (49,50) это было бы более, чем разумно, т.к. запрос остаётся достаточно селективным.
Теперь давайте проведём ещё один тест. Я очистил таблицу и вновь наполнил её данными таким образом, чтобы значения в i1 и i2 сильно коррелировали. На самом деле они теперь вообще равны:
Query OK, 10900996 rows affected (6 min 47.87 sec)
Rows matched: 11010048 Changed: 10900996 Warnings: 0
Давайте посмотрим, что произойдёт в этом случае:
mysql> EXPLAIN SELECT avg(length(val)) FROM >
Оптимизатор решил использовать пересечение индексов, хотя это было едва ли не самым худшим решением! Выполнение запроса заняло 360 мс. Также обратите внимания на большую погрешность в оценке примерного количества строк.
Это произошло из-за того, что MySQL считает значения в колонках i1 и i2 независимыми, и потому выбирает пересечение индексов. На самом деле он не может предположить другого, т.к. никакой статистики о корреляции значений в колонках у него нет.
mysql> EXPLAIN SELECT avg(length(val)) FROM >
А теперь, когда мы запретили MySQL использовать индекс по колонке i2 (а значит он не может и найти пересечение индексов), он использует индекс по одной колонке, а не комбинированный. Произошло так потому, что у MySQL есть статистика о примерном количестве подходящих строк, и так как оно равно для обоих индексов, то MySQL выбрал меньший по размеру. Выполнение запроса опять заняло 290 мс — в точности столько же, сколько и в прошлый раз.
Заставим MySQL использовать только combined индекс:
mysql> EXPLAIN SELECT avg(length(val)) FROM >
Видно, что MySQL примерно на 20% ошибается в оценке количества перебираемых строк, что, конечно, неверно, т.к. используется тот же префикс, что и при использовании индекса только по колонке i1. MySQL не знает этого, т.к. просматривает статистику по отдельным индексам и не пытается согласовывать их.
Из-за того, что используемый комбинированный индекс больше, чем индекс по одной колонке, выполнение запроса заняло 300 мс.
Таким образом мы видим, что MySQL может решить использовать пересечение индексов даже в том случае, если это худший вариант, хотя с технической точки зрения это, конечно, будет лучший план, учитывая, что другой статистики у него нет.
Есть простые способы заставить MySQL не использовать пересечение индексов, но, к сожалению, мне не известно как заставить его использовать пересечения, если он считает этот вариант неоптимальным. Надеюсь, что такая возможность в будущем будет добавлена.
Наконец, давайте рассмотрим ситуацию, когда процедура нахождения пересечения индексов работает значительно лучше, чем комбинированные индексы по нескольким колонкам. Речь идёт о случае, когда мы используете OR при выборке между колонками. В этом случае комбинированный индекс становится совершенно бесполезным, и у MySQL есть выбор между полным сканированием таблицы (FULL SCAN) и выполнением объединения (UNION) значений вместо поиска пересечения на данных, которые он получил из одной таблице.
Я вновь изменил взначения в столбцах i1 и i2 таким образом, чтобы в них содержались независимые данные (типичная ситуация для таблиц).
mysql> EXPLAIN SELECT avg(length(val)) FROM >
Такой запросы выполняется 660 мс. Отключив индекс по второй колонке мы получим FULL SCAN:
mysql> EXPLAIN SELECT avg(length(val)) FROM >
Обратите внимание, что MySQL указал ключи i1,combined как возможные к использованию, однако на самом деле такой возможности у него нет. Выполнение такого запросы занимает 3370 мс!
Также обратите внимание на то, что выполнение запроса заняло в 5 раз больше времени несмотря на то, что FULL SCAN прошёл примерно в 50 раз больше строк. Это показывает очень большую разницу в производительности между полным проходом по таблице и доступе по ключу, который занимает в 10 раз больше времени (в смысле «стоимости» доступа на строку), несмотря на то, что выполняется в памяти.
В случае UNION оптизатор действует более продвинуто и вполне способен справится с диапазонами:
mysql> EXPLAIN SELECT avg(length(val)) FROM >
Подводя итоги
В большинстве случаев использование комбинированных индексов по нескольким колонкам является лучшим решением, если вы используете AND между подобными колонками в WHERE. Использование пересечения индексов в принципе улучшает производительность, но она всё равно значительно хуже, чем при использовании комбинированных ключей. В случае, если Вы используете OR между колонками Вам потребуется иметь по индексу на каждой из колонок, чтобы MySQL смог найти их пересечения, а комбинированные индексы не могут использоваться в таких запросах.
Все индексы MySQL (PRIMARY, UNIQUE, и INDEX) хранятся в виде B-деревьев. Строки автоматически сжимаются с удалением пробелов в префиксах и оконечных пробелов (see Раздел 6.5.7, «Синтаксис оператора CREATE INDEX»).
Индексы используются для того, чтобы:
- Быстро найти строки, соответствующие выражению WHERE.
- Извлечь строки из других таблиц при выполнении объединений.
- Найти величины MAX() или MIN() для заданного индексированного столбца. Эта операция оптимизируется препроцессором, который проверяет, не используете ли вы WHERE key_part_4 = константа, по всем частям составного ключа SELECT * FROM tbl_name WHERE col1=val1 AND col2=val2;
Если по столбцам col1 и col2 существует многостолбцовый индекс, то соответствующие строки могут выбираться напрямую. В случае, когда по столбцам col1 и col2 существуют раздельные индексы, оптимизатор пытается найти наиболее ограничивающий индекс путем определения, какой индекс найдет меньше строк, и использует данный индекс для выборки этих строк.
Если данная таблица имеет многостолбцовый индекс, то любой крайний слева префикс этого индекса может использоваться оптимизатором для нахождения строк. Например, если имеется индекс по трем столбцам (col1,col2,col3), то существует потенциальная возможность индексированного поиска по (col1), (col1,col2) и (col1,col2,col3).
В MySQL нельзя использовать частичный индекс, если столбцы не образуют крайний слева префикс этого индекса. Предположим, что имеются команды SELECT, показанные ниже:
mysql> SELECT * FROM tbl_name WHERE col1=val1;
mysql> SELECT * FROM tbl_name WHERE col2=val2;
mysql> SELECT * FROM tbl_name WHERE col2=val2 AND col3=val3;
mysql> SELECT * FROM tbl_name WHERE col1=val1 AND col2=val2;
Если индекс существует по (col1,col2,col3), то только первый и четвертый показанные выше запросы использует данный индекс. Второй и третий запросы действительно включают индексированные столбцы, но (col2) и (col2,col3) не являются крайней слева частью префиксов (col1,col2,col3).
*при этом, индексы будут работать не зависимо от типа индекса, т.е. и тип индекса: INDEX и тип индекса UNIQUE отработают очень быстро.
MySQL применяет индексы также для сравнений LIKE, если аргумент в выражении LIKE представляет собой постоянную строку, не начинающуюся с символа-шаблона. Например, следующие команды SELECT используют индексы:
mysql> SELECT * FROM tbl_name WHERE key_col LIKE "Patrick%";
mysql> SELECT * FROM tbl_name WHERE key_col LIKE "Pat%_ck%";
В первой команде рассматриваются только строки с "Patrick" SELECT * FROM tbl_name WHERE key_col LIKE "%Patrick%";
mysql> SELECT * FROM tbl_name WHERE key_col LIKE other_col;
В первой команде величина LIKE начинается с шаблонного символа. Во второй команде величина LIKE не является константой.
В версии MySQL 4.0 производится другая оптимизация на выражении LIKE. Если используется выражение . LIKE "%string%" и длина строки (string) больше, чем 3 символа, то MySQL будет применять алгоритм Турбо Бойера-Мура для инициализации шаблона для строки и затем использовать этот шаблон, чтобы выполнить поиск быстрее.
При поиске с использованием column_name IS NULL будут использоваться индексы, если column_name является индексом.
MySQL обычно использует тот индекс, который находит наименьшее количество строк. Индекс применяется для столбцов, которые сравниваются с помощью следующих операторов: =, >, >=,
Индексы в MySQL (Mysql indexes) — отличный инструмент для оптимизации SQL запросов. Чтобы понять, как они работают, посмотрим на работу с данными без них.
1. Чтение данных с диска
На жестком диске нет такого понятия, как файл. Есть понятие блок. Один файл обычно занимает несколько блоков. Каждый блок знает, какой блок идет после него. Файл делится на куски и каждый кусок сохраняется в пустой блок. 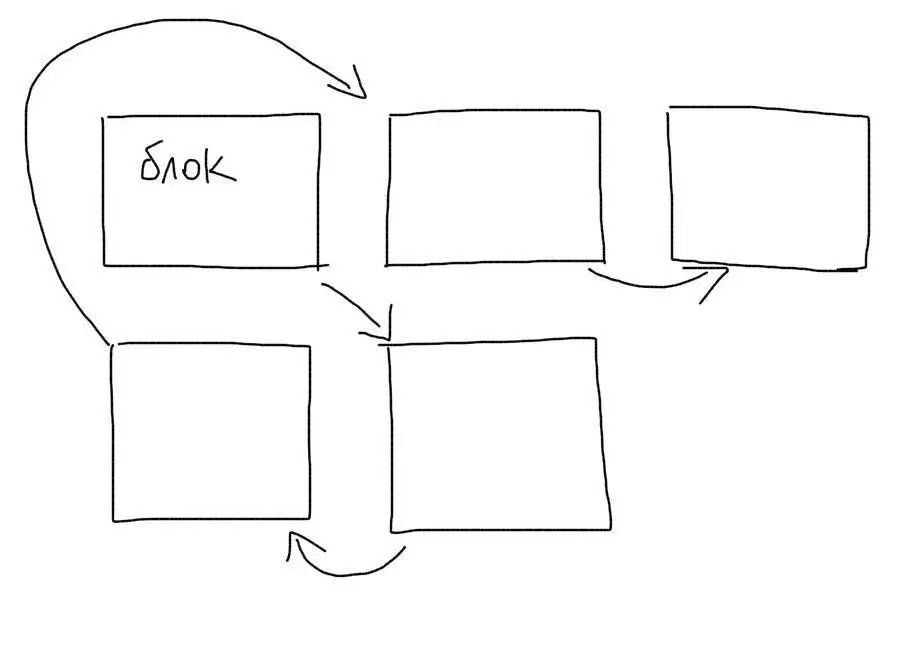
При чтении файла, мы по очереди проходимся по всем блокам и собираем файл из кусков. Блоки одного файла могут быть раскиданы по диску (фрагментация). Тогда чтение файла замедлится, т.к. понадобится прыгать разным участкам диска.
Когда мы ищем что-то внутри файла, нам понадобится пройтись по всем блокам, в которых он сохранен. Если файл очень большой, то и количество блоков будет значительным. Необходимость перепрыгивать с блока на блок, которые могут находиться в разных местах, сильно замедлит поиск данных.
2. Поиск данных в MySQL
Таблицы MySQL — это обычные файлы. Выполним запрос такого вида:
MySQL при этом открывает файл, где хранятся данные из таблицы users. А дальше — начинает перебирать весь файл, чтобы найти нужные записи.
Кроме этого, MySQL будет сравнивать данные в каждой строке таблицы со значением в запросе. Допустим работа ведется с таблицей, в которой есть 10 записей. Тогда MySQL прочитает все 10 записей, сравнит колонку age каждой из них со значением 29 и отберет только подходящие данные: 
Итак, есть две проблемы при чтении данных:
- Низкая скорость чтения файлов из-за расположения блоков в разных частях диска (фрагментация).
- Большое количество операций сравнения для поиска нужных данных.
3. Сортировка данных
Представим, что мы отсортировали наши 10 записей по убыванию. Тогда используя алгоритм бинарного поиска, мы могли бы максимум за 4 операции отобрать нужные нам значения: 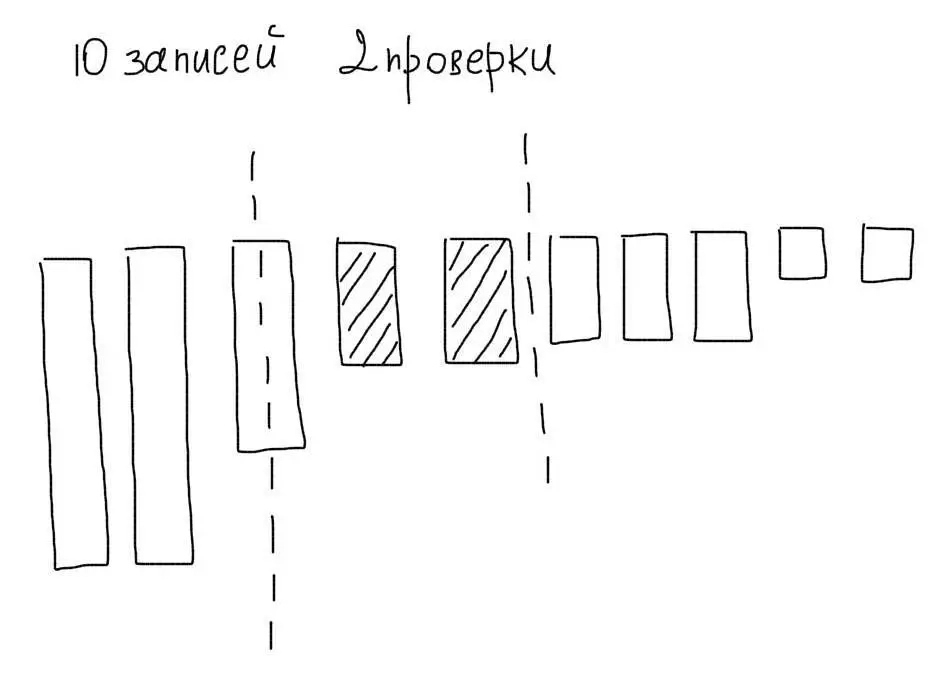
Кроме меньшего количества операций сравнения, мы сэкономили бы на чтении ненужных записей.
Индекс — это и есть отсортированный набор значений. В MySQL индексы всегда строятся для какой-то конкретной колонки. Например, мы могли бы построить индекс для колонки age из примера.
4. Выбор индексов в MySQL
В самом простом случае, индекс необходимо создавать для тех колонок, которые присутствуют в условии WHERE. 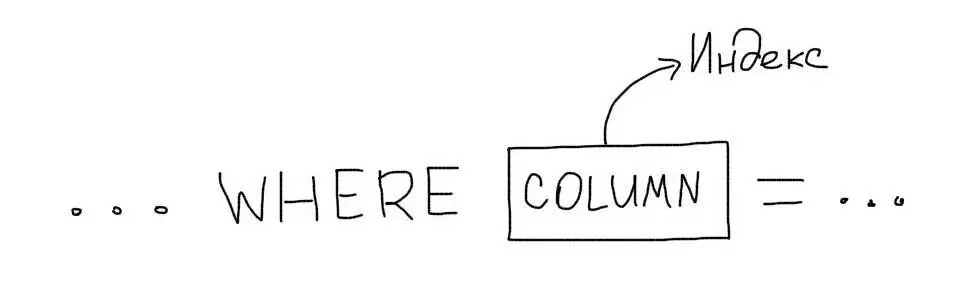
Рассмотрим запрос из примера:
Нам необходимо создать индекс на колонку age:
После этой операции MySQL начнет использовать индекс age для выполнения подобных запросов. Индекс будет использоваться и для выборок по диапазонам значений этой колонки:
Сортировка
Для запросов такого вида:
действует такое же правило — создаем индекс на колонку, по которой происходит сортировка:
Внутренности хранения индексов
Представим, что наша таблица выглядит так:
После создания индекса на колонку age, MySQL сохранит все ее значения в отсортированном виде:
Кроме этого, будет сохранена связь между значением в индексе и записью, которой соответствует это значение. Обычно для этого используется первичный ключ:
Уникальные индексы
MySQL поддерживает уникальные индексы. Это удобно для колонок, значения в которых должны быть уникальными по всей таблице. Такие индексы улучшают эффективность выборки для уникальных значений. Например:
На колонку email необходимо создать уникальный индекс:
Тогда при поиске данных, MySQL остановится после обнаружения первого соответствия. В случае обычного индекса будет обязательно проведена еще одна проверка (следующего значения в индексе).
5. Составные индексы
MySQL может использовать только один индекс для запроса (кроме случаев, когда MySQL способен объединить результаты выборок по нескольким индексам). Поэтому, для запросов, в которых используется несколько колонок, необходимо использовать составные индексы. 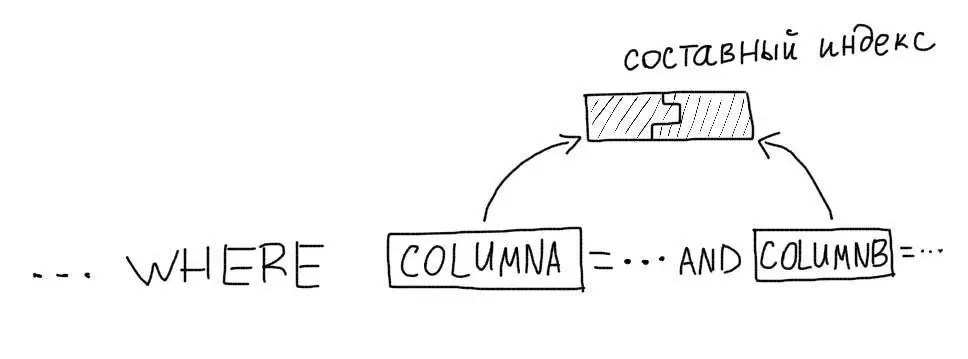
Рассмотрим такой запрос:
Нам следует создать составной индекс на обе колонки:
Устройство составного индекса
Чтобы правильно использовать составные индексы, необходимо понять структуру их хранения. Все работает точно так же, как и для обычного индекса. Но для значений используются значений всех входящих колонок сразу. Для таблицы с такими данными:
значения составного индекса будут такими:
Это означает, что очередность колонок в индексе будет играть большую роль. Обычно колонки, которые используются в условиях WHERE, следует ставить в начало индекса. Колонки из ORDER BY — в конец.
Поиск по диапазону
Представим, что наш запрос будет использовать не сравнение, а поиск по диапазону:
Тогда MySQL не сможет использовать полный индекс, т.к. значения gender будут отличаться для разных значений колонки age. В этом случае база данных попытается использовать часть индекса (только age), чтобы выполнить этот запрос:
Сначала будут отфильтрованы все данные, которые подходят под условие age . Затем, поиск по значению "male" будет произведен без использования индекса.
Сортировка
Составные индексы также можно использовать, если выполняется сортировка:
В этом случае нам нужно будет создать индекс в другом порядке, т.к. сортировка (ORDER) происходит после фильтрации (WHERE):
Такой порядок колонок в индексе позволит выполнить фильтрацию по первой части индекса, а затем отсортировать результат по второй.
Колонок в индексе может быть больше, если требуется:
В этом случае следует создать такой индекс:
6. Использование EXPLAIN для анализа индексов
Инструкция EXPLAIN покажет данные об использовании индексов для конкретного запроса. Например:
Колонка key показывает используемый индекс. Колонка possible_keys показывает все индексы, которые могут быть использованы для этого запроса. Колонка rows показывает число записей, которые пришлось прочитать базе данных для выполнения этого запроса (в таблице всего 336 записей).
Как видим, в примере не используется ни один индекс. После создания индекса:
Прочитана всего одна запись, т.к. был использован индекс.
Проверка длинны составных индексов
Explain также поможет определить правильность использования составного индекса. Проверим запрос из примера (с индексом на колонки age и gender):
Значение key_len показывает используемую длину индекса. В нашем случае 24 байта — длинна всего индекса (5 байт age + 19 байт gender).
Если мы выполним изменим точное сравнение на поиск по диапазону, увидим что MySQL использует только часть индекса:
Это сигнал о том, что созданный индекс не подходит для этого запроса. Если же мы создадим правильный индекс:
В этом случае MySQL использует весь индекс gender_age, т.к. порядок колонок в нем позволяет сделать эту выборку.
7. Селективность индексов
Вернемся к запросу:
Для такого запроса необходимо создать составной индекс. Но как правильно выбрать последовательность колонок в индексе? Варианта два:
- age, gender
- gender, age
Подойдут оба. Но работать они будут с разной эффективностью.
Чтобы понять это, рассмотрим уникальность значений каждой колонки и количество соответствующих записей в таблице:
Эта информация говорит нам вот о чем:
- Любое значение колонки age обычно содержит около 200 записей.
- Любое значение колонки gender — около 6000 записей.
Если колонка age будет идти первой в индексе, тогда MySQL после первой части индекса сократит количество записей до 200. Останется сделать выборку по ним. Если же колонка gender будет идти первой, то количество записей будет сокращено до 6000 после первой части индекса. Т.е. на порядок больше, чем в случае age.
Это значит, что индекс age_gender будет работать лучше, чем gender_age. 
Селективность колонки определяется количеством записей в таблице с одинаковыми значениями. Когда записей с одинаковым значением мало — селективность высокая. Такие колонки необходимо использовать первыми в составных индексах.
8. Первичные ключи
Первичный ключ (Primary Key) — это особый тип индекса, который является идентификатором записей в таблице. Он обязательно уникальный и указывается при создании таблиц:
При использовании таблиц InnoDB всегда определяйте первичные ключи. Если первичного ключа нет, MySQL все равно создаст виртуальный скрытый ключ.
Кластерные индексы
Обычные индексы являются некластерными. Это означает, что сам индекс хранит только ссылки на записи таблицы. Когда происходит работа с индексом, определяется только список записей (точнее список их первичных ключей), подходящих под запрос. После этого происходит еще один запрос — для получения данных каждой записи из этого списка. 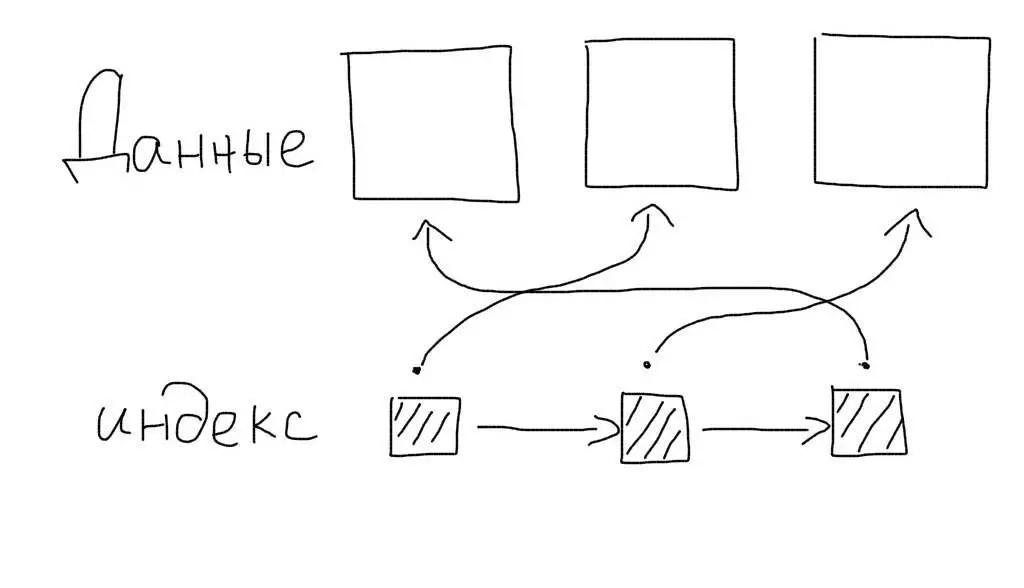
Кластерные индексы сохраняют данные записей целиком, а не ссылки на них. При работе с таким индексом не требуется дополнительной операции чтения данных. 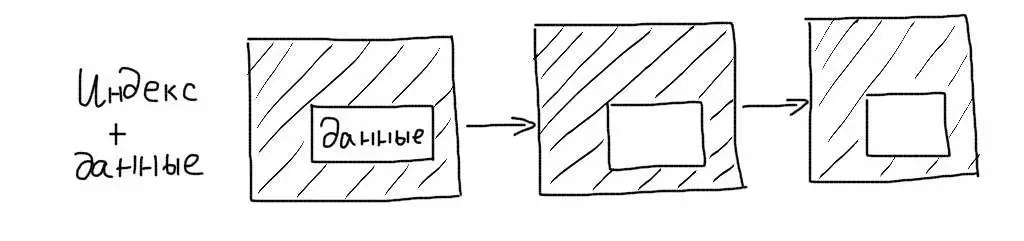
Первичные ключи таблиц InnoDB являются кластерными. Поэтому выборки по ним происходят очень эффективно.
Overhead
Важно помнить, что индексы предполагают дополнительные операции записи на диск. При каждом обновлении или добавлении данных в таблицу, происходит также запись и обновление данных в индексе. 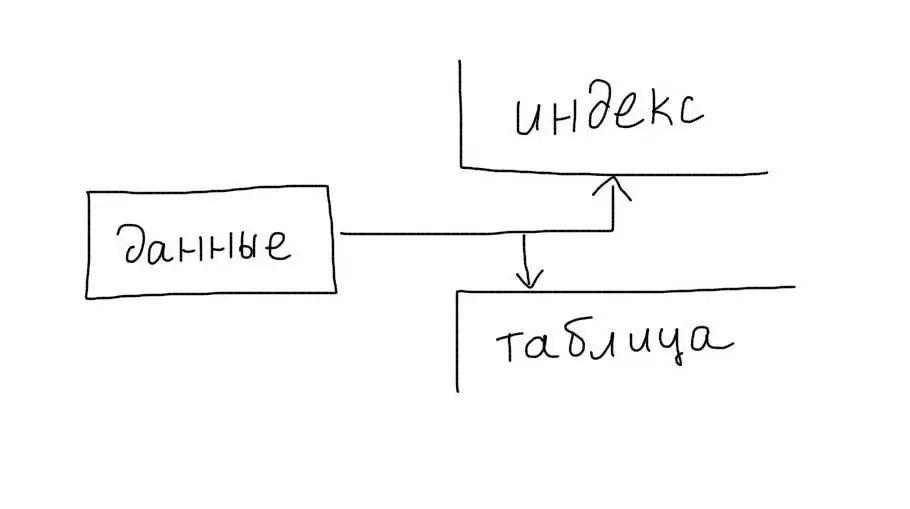
Создавайте только необходимые индексы, чтобы не расходовать зря ресурсы сервера. Контролируйте размеры индексов для Ваших таблиц:
Когда создавать индексы?
- Индексы следует создавать по мере обнаружения медленных запросов. В этом поможет slow log в MySQL. Запросы, которые выполняются более 1 секунды являются первыми кандидатами на оптимизацию.
- Начинайте создание индексов с самых частых запросов. Запрос, выполняющийся секунду, но 1000 раз в день наносит больше ущерба, чем 10-секундный запрос, который выполняется несколько раз в день.
- Не создавайте индексы на таблицах, число записей в которых меньше нескольких тысяч. Для таких размеров выигрыш от использования индекса будет почти незаметен.
- Не создавайте индексы заранее, например, в среде разработки. Индексы должны устанавливаться исключительно под форму и тип нагрузки работающей системы.
- Удаляйте неиспользуемые индексы.
Самое важное
Выделяйте достаточно времени на анализ и организацию индексов в MySQL (и других базах данных). На это может уйти намного больше времени, чем на проектирование структуры базы данных. Удобно будет организовать тестовую среду с копией реальных данных и проверять там разные структуры индексов.
Не создавайте индексы на каждую колонку, которая есть в запросе, MySQL так не работает. Используйте уникальные индексы, где необходимо. Всегда устанавливайте первичные ключи.
Ускорение репликации в Mysql 5.6+
Правильная настройка Mysql под нагрузки и не только. Обновлено.
Анализ медленных запросов с помощью EXPLAIN
3 примера установки индексов в JOIN запросах
Check-unused-keys для определения неиспользуемых индексов в базе данных
Включение и использование логов ошибок, запросов и медленных запросов, бинарного лога для проверки работы MySQL
Сравнение Vertica и Mysql на практике
Правила выбора типов данных для максимальной производительности в Mysql
Повышение скорости работы запросов с MySQL Handlersocket
Как восстановить данные, если MySQL упал и не поднимается
Правильный поиск по тексту в Mysql (full-text search)
Анализ медленных запросов (профилирование) в MySQL с помощью Percona Toolkit
Синтаксис и оптимизация Mysql LIMIT
Оптимизация постраничного вывода данных
Использование партиций для ускорения сложных удалений
Быстрая альтернатива Mysqldump для больших таблиц без блокировок и выключений.
Анализ работы СУБД при помощи pgFouine
Сравнение двух движков и когда стоит использовать каждый из них
Эффективная замена ORDER BY RAND()
Рекомендации по настройке Redis для оптимизации ресурсов и повышения стабильности на производственном сервере
Создание и использование Real-Time индексов в Sphinx’e
Настройки для улучшения производительности Postgres
Устройство колоночных баз данных
Как устроена распределенная база данных на основе blockchain механизма