Содержание
Содержание урока:

 |
14.1. Кодировка ASCII и её расширения |  |
| Кодирование текстовой информации |  |
14.2. Стандарт Unicode |
14.1. Кодировка ASCII и её расширения
Основой для компьютерных стандартов кодирования символов послужил код ASCII (American Standard Code for Information Interchange) — американский стандартный код для обмена информацией, разработанный в 1960-х годах в США и применявшийся для любых, в том числе и некомпьютерных, способов передачи информации (телеграф, факсимильная связь и т. д.). Этот код 7-битовый: общее количество символов составляет 2 7 = 128, из них первые 32 символа — управляющие, а остальные — изображаемые, т. е. имеющие графическое изображение. К изображаемым символам в ASCII относятся буквы латинского алфавита (прописные и строчные), цифры, знаки препинания и арифметических операций, скобки и некоторые специальные символы. Кодировка ASCII приведена в табл. 3.8.
Таблица 3.8
Кодировка ASCII
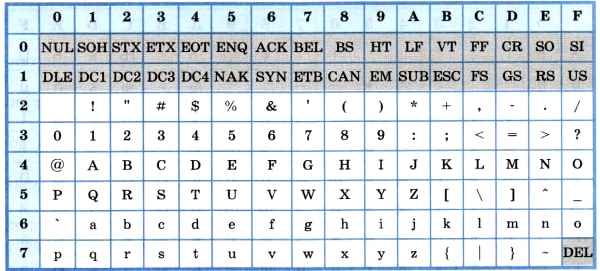
Хотя для кодирования символов в ASCII достаточно 7 битов, в памяти компьютера под каждый символ отводится ровно 1 байт (8 битов), при этом код символа помещается в младшие биты, а в старший бит заносится 0.
Например, 01000001 — код прописной латинской буквы «А»; с помощью шестнадцатеричных цифр его можно записать как 41.
Стандарт ASCII рассчитан на передачу только английского текста. Со временем возникла необходимость кодирования и неанглийских букв. Во многих странах для этого стали разрабатывать расширения ASCII -кодировки, в которых применялись однобайтовые коды символов. При этом первые 128 символов кодовой таблицы совпадали с кодировкой ASCII, а остальные (со 128-го по 255-й) использовались для кодирования букв национального алфавита, символов национальной валюты и т. п. Из-за несогласованности этих разработок для многих языков было создано несколько вариантов кодовых таблиц (например, для русского языка их было создано около десятка!).
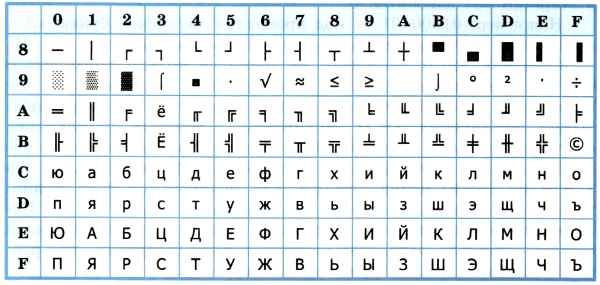
Впоследствии использование кодовых таблиц было несколько упорядочено: каждой кодовой таблице было присвоено особое название и номер. Для русского языка наиболее распространёнными стали однобайтовые кодовые таблицы CP-866, Windows-1251 (табл. 3.9) и КОИ-8 (табл. 3.10). В них первые 128 символов совпадают с ASCII-кодировкой, а русские буквы размещены во второй части таблицы. Обратите внимание на то, что коды русских букв в этих кодировках различны.
Таблица 3.9
Кодировка Windows-1251
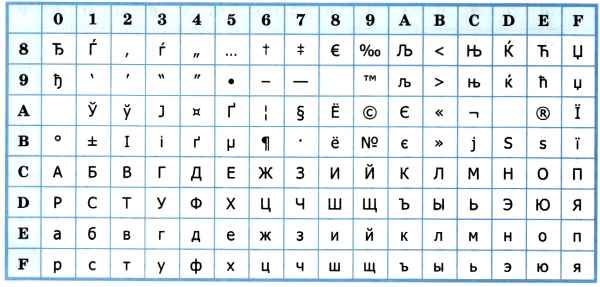
Таблица 3.10
Кодировка КОИ-8
Мы выяснили, что при нажатии на алфавитно-цифровую клавишу в компьютер посылается некоторая цепочка нулей и единиц. В текстовых файлах хранятся не изображения символов, а их коды.
При выводе текста на экран монитора или принтера необходимо восстановить изображения всех символов, составляющих данный текст, причём изображения эти могут быть разнообразны и достаточно причудливы. Внешний вид выводимых на экран символов кодируется и хранится в специальных шрифтовых файлах. Современные текстовые процессоры умеют внедрять шрифты в файл. В этом случае файл содержит не только коды символов, но и описание используемых в этом документе шрифтов. Кроме того, файлы, создаваемые с помощью текстовых процессоров, включают в себя и такие данные о форматировании текста, как его размер, начертание, размеры полей, отступов, межстрочных интервалов и другую дополнительную информацию.
Cкачать материалы урока
Кодировка символов (часто называемая также кодовой страницей ) – это набор числовых значений, которые ставятся в соответствие группе алфавитно-цифровых символов, знаков пунктуации и специальных символов.
Для кодировки символов в Windows используется таблица ASCII (American Standard Code for Interchange of Information).
В ASCII первые 128 символов всех кодовых страниц состоят из базовой таблицы символов. Первые 32 кода базовой таблицы, начиная с нулевого, размещают управляющие коды.
| Символ | Код | Клавиши | Значение |
| nul | Ctrl + @ | Нуль | |
| soh | 1 | Ctrl + A | Начало заголовка |
| stx | 2 | Ctrl + B | Начало текста |
| etx | 3 | Ctrl + C | Конец текста |
| eot | 4 | Ctrl + D | Конец передачи |
| enq | 5 | Ctrl + E | Запрос |
| ack | 6 | Ctrl + F | Подтверждение |
| bel | 7 | Ctrl + G | Сигнал (звонок) |
| bs | 8 | Ctrl + H | Забой (шаг назад) |
| ht | 9 | Ctrl + I | Горизонтальная табуляция |
| lf | 10 | Ctrl + J | Перевод строки |
| vt | 11 | Ctrl + K | Вертикальная табуляция |
| ff | 12 | Ctrl + L | Новая страница |
| cr | 13 | Ctrl + M | Возврат каретки |
| so | 14 | Ctrl + N | Выключить сдвиг |
| si | 15 | Ctrl + O | Включить сдвиг |
| dle | 16 | Ctrl + P | Ключ связи данных |
| dc1 | 17 | Ctrl + Q | Управление устройством 1 |
| dc2 | 18 | Ctrl + R | Управление устройством 2 |
| dc3 | 19 | Ctrl + S | Управление устройством 3 |
| dc4 | 20 | Ctrl + T | Управление устройством 4 |
| nak | 21 | Ctrl + U | Отрицательное подтверждение |
| syn | 22 | Ctrl + V | Синхронизация |
| etb | 23 | Ctrl + W | Конец передаваемого блока |
| can | 24 | Ctrl + X | Отказ |
| em | 25 | Ctrl + Y | Конец среды |
| sub | 26 | Ctrl + Z | Замена |
| esc | 27 | Ctrl + [ | Ключ |
| fs | 28 | Ctrl + | Разделитель файлов |
| gs | 29 | Ctrl + ] | Разделитель группы |
| rs | 30 | Ctrl + ^ | Разделитель записей |
| us | 31 | Ctrl + _ | Разделитель модулей |
Базовая таблица кодировки ASCII
| 32 пробел | 48 0 | 64 @ | 80 P | 96 ` | 112 p |
| 33 ! | 49 1 | 65 A | 81 Q | 97 a | 113 q |
| 34 “ | 50 2 | 66 B | 82 R | 98 b | 114 r |
| 35 # | 51 3 | 67 C | 83 S | 99 c | 115 s |
| 36 $ | 52 4 | 68 D | 84 T | 100 d | 116 t |
| 37 % | 53 5 | 69 E | 85 U | 101 e | 117 u |
| 38 & | 54 6 | 70 F | 86 V | 102 f | 118 v |
| 39 ‘ | 55 7 | 71 G | 87 W | 103 g | 119 w |
| 40 ( | 56 8 | 72 H | 88 X | 104 h | 120 x |
| 41 ) | 57 9 | 73 I | 89 Y | 105 i | 121 y |
| 42 * | 58 : | 74 J | 90 Z | 106 j | 122 z |
| 43 + | 59 ; | 75 K | 91 [ | 107 k | 123 < |
| 44 , | 60 | 78 N | 94 ^ | 110 n | 126 |
Символы с номерами от 128 до 255 представляют собой таблицу расширения и варьируются в зависимости от набора скриптов, представленных кодировкой символов. Набор символов таблицы расширения различается в зависимости от выбранной кодовой страницы:
1251 – кодовая страница Windows
| 128 Ђ | 144 Ђ | 160 | 176 ° | 192 А | 208 Р | 224 а | 240 р |
| 129 Ѓ | 145 ‘ | 161 Ў | 177 ± | 193 Б | 209 С | 225 б | 241 с |
| 130 ‚ | 146 ’ | 162 ў | 178 I | 194 В | 210 Т | 226 в | 242 т |
| 131 ѓ | 147 “ | 163 J | 179 i | 195 Г | 211 У | 227 г | 243 у |
| 132 „ | 148 ” | 164 ¤ | 180 ґ | 196 Д | 212 Ф | 228 д | 244 ф |
| 133 … | 149 • | 165 Ґ | 181 μ | 197 Е | 213 Х | 229 е | 245 х |
| 134 † | 150 – | 166 ¦ | 182 ¶ | 198 Ж | 214 Ц | 230 ж | 246 ц |
| 135 ‡ | 151 — | 167 § | 183 · | 199 З | 215 Ч | 231 з | 247 ч |
| 136 € | 152 □ | 168 Ё | 184 ё | 200 И | 216 Ш | 232 и | 248 ш |
| 137 ‰ | 153 ™ | 169 © | 185 № | 201 Й | 217 Щ | 233 й | 249 щ |
| 138 Љ | 154 љ | 170 Є | 186 є | 202 К | 218 Ъ | 234 к | 250 ъ |
| 139 | 171 « | 187 » | 203 Л | 219 Ы | 235 л | 251 ы | |
| 140 Њ | 156 њ | 172 ¬ | 188 j | 204 М | 220 Ь | 236 м | 252 ь |
| 141 Ќ | 157 ќ | 173 | 189 S | 205 Н | 221 Э | 237 н | 253 э |
| 142 Ћ | 158 ћ | 174 ® | 190 s | 206 О | 222 Ю | 238 о | 254 ю |
| 143 Џ | 159 џ | 175 Ï | 191 ї | 207 П | 223 Я | 239 п | 255 я |
866 – кодовая страница DOS
| 128 А | 144 Р | 160 а | 176 ░ | 192 └ | 208 ╨ | 224 р | 240 ≡Ё |
| 129 Б | 145 С | 161 б | 177 ▒ | 193 ┴ | 209 ╤ | 225 с | 241 ±ё |
| 130 В | 146 Т | 162 в | 178 ▓ | 194 ┬ | 210 ╥ | 226 т | 242 ≥ |
| 131 Г | 147 У | 163 г | 179 │ | 195 ├ | 211 ╙ | 227 у | 243 ≤ |
| 132 Д | 148 Ф | 164 д | 180 ┤ | 196 ─ | 212 ╘ | 228 ф | 244 ⌠ |
| 133 Е | 149 Х | 165 е | 181 ╡ | 197 ┼ | 213 ╒ | 229 х | 245 ⌡ |
| 134 Ж | 150 Ц | 166 ж | 182 ╢ | 198 ╞ | 214 ╓ | 230 ц | 246 ¸ |
| 135 З | 151 Ч | 167 з | 183 ╖ | 199 ╟ | 215 ╫ | 231 ч | 247 » |
| 136 И | 152 Ш | 168 и | 184 ╕ | 200 ╚ | 216 ╪ | 232 ш | 248 ° |
| 137 Й | 153 Щ | 169 й | 185 ╣ | 201 ╔ | 217 ┘ | 233 щ | 249 · |
| 138 К | 154 Ъ | 170 к | 186 ║ | 202 ╩ | 218 ┌ | 234 ъ | 250 ∙ |
| 139 Л | 155 Ы | 171 л | 187 ╗ | 203 ╦ | 219 █ | 235 ы | 251 √ |
| 140 М | 156 Ь | 172 м | 188 ╝ | 204 ╠ | 220 ▄ | 236 ь | 252 ⁿ |
| 141 Н | 157 Э | 173 н | 189 ╜ | 205 ═ | 221 ▌ | 237 э | 253 ² |
| 142 О | 158 Ю | 174 о | 190 ╛ | 206 ╬ | 222 ▐ | 238 ю | 254 ■ |
| 143 П | 159 Я | 175 п | 191 ┐ | 207 ╧ | 223 ▀ | 239 я | 255 |
Русские названия основных спецсимволов:
| Символ | Название |
| ` | гравис, кавычка, обратный машинописный апостроф |
| ` | гравис, кавычка, обратный машинописный апостроф |
| тильда | |
| ! | восклицательный знак |
| @ | эт, коммерческое эт, «собака» |
| # | октоторп, решетка, диез |
| $ | знак доллара |
| % | процент |
| ^ | циркумфлекс, знак вставки |
| & | амперсанд |
| * | астериск, звездочка, знак умножения |
| ( | левая открывающая круглая скобка |
| ) | правая закрывающая круглая скобка |
| — | минус, дефис |
| _ | знак подчеркивания |
| = | знак равенства |
| + | плюс |
| [ | левая открывающая квадратная скобка |
| ] | правая закрывающая квадратная скобка |
| < | левая открывающая фигурная скобка |
| > | правая закрывающая фигурная скобка |
| ; | точка с запятой |
| : | двоеточие |
| ‘ | машинописный апостроф, одинарная кавычка |
| " | двойная кавычка |
| , | запятая |
| . | точка |
| / | слэш, косая черта, знак дроби |
| правая закрытая угловая скобка, знак больше | |
| обратный слэш, обратная косая черта | |
| | | вертикальная черта |
Кодировка UNICODE
Юникод (Unicode) — стандарт кодирования символов, позволяющий представить знаки практически всех письменных языков. Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода».
В Unicode используются 16-битовые (2-байтовые) коды, что позволяет представить 65536 символов.
Применение стандарта Unicode позволяет закодировать очень большое число символов из разных письменностей: в документах Unicode могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы, при этом становится ненужным переключение кодовых страниц.
Для представления символьных данных в кодировке Unicode используется символьный тип wchar_t .
| ASCII | UNICODE |
| char | wchar_t |
| 1 байт | 2 байта |
Тип кодировки задается в свойствах проекта Microsoft Visual Studio: 

Многобайтовая кодировка предполагает использование кодировки ASCII.
При этом при построении проекта используется директива условной компиляции, переопределяющая тип TCHAR :
Для перекодирования строки в формат Unicode без изменения кодировки файла используется макроопределение
_T("строка")
Прототип макроса содержится в файле tchar.h .
Для кодирования символьной или текстовой информации применяются различные системы: при вводе информации с клавиатуры кодирование происходит при нажатии клавиши, на которой изображен требуемый символ, при этом в клавиатуре вырабатывается так называемый scan-код, представляющий собой двоичное число, равное порядковому номеру клавиши.
3.1 Кодировка ASCII
Всего существует множество кодировочных таблиц. Рассмотрим сначала кодировочную таблицу ASCII (ASCII – American Standard Code for Information Interchange – Американский стандартный код для обмена информацией). Эта кодировка является наиболее известной. На практике обычно не бывает проблем с кодированием англоязычных текстов, поскольку первая половина кодировки стандартизована, но, к сожалению, для кодировки русских букв существует несколько кодировочных таблиц, что иногда создает проблемы при работе с текстами.
Для кодировки одного символа из таблицы отводится 8 бит. При обработке текстовой информации один байт может содержать код некоторого символа – буквы, цифры, знака пунктуации, знака действия и т.д. Каждому символу соответствует свой код в виде целого числа. Один байт как набор восьми битов позволяет закодировать 256 символов, что вполне достаточно для работы сразу с двумя обычными языками, например английским и русским. При этом все коды собираются в специальные таблицы, называемые кодировочными. С их помощью производится преобразование кода символа в его видимое представление на экране монитора. В результате любой текст в памяти компьютера представляется как последовательность байтов с кодами символов.
Таблица кодировки текстовой информации ASCII.

Первая половина таблицы ASCII стандартизована. Она содержит управляющие коды (от 0 до 31. Эти коды из таблицы изъяты, так как они не относятся к текстовым элементам. Вторая половина таблицы содержит национальные шрифты, символы псевдографики, из которых могут быть построены таблицы, специальные математические знаки. Нижнюю часть таблицы кодировок можно заменять, используя соответствующие драйверы – управляющие вспомогательные программы. Этот прием позволяет применять несколько шрифтов и их гарнитур. Невозможно использовать символы различных наборов кодировок в одном и том же документе. Так как каждый текстовый документ использует свой собственный набор кодировок, то возникают большие трудности с автоматическим распознаванием текста. Появляются новые символы (например:Евро), вследствие чего ISO разрабатывает новый стандарт ISO-8859-15, который весьма схож со стандартом ISO-8859-1. Разница состоит в следующем: из таблицы кодировки старого стандарта ISO-8859-1 были убраны символы обозначения старых валют, которые не используются в настоящее время, для того, чтобы освободить место под вновь появившиеся символы (такие, как Евро). В результате у пользователей на дисках могут лежать одни и те же документы, но в разных кодировках. Решением этих проблем является принятие единого международного набора кодировок, который называется универсальным кодированием или Unicode.
Данная кодировка решает пользовательские проблемы (см. выше), но создает новые, технические проблемы: как пересылать символы в формате Unicode, используя 8-битные байты? 8-битные единицы являются наименьшими передаваемыми единицами в большинстве компьютеров, а также являющимися минимальными единицами, используемыми при сетевых соединениях на основе протокола TCP/IP. Использование 1-го байта для представления 1-го символа стало эпизодом истории (факт появления такой кодировки обусловлен тем, что компьютеры зародились в Европе и США, где долгое время обходились 96 символами).
Существует 4 основных способа кодировки байтами в формате Unicode:
UTF-8: 128 символов кодируются одним байтом (формат ASCII), 1920 символов кодируются 2-мя байтами ((Roman, Greek, Cyrillic, Coptic, Armenian, Hebrew, Arabic символы), 63488 символов кодируются 3-мя байтами (Китайский, японский и др.) Оставшиеся 2 147 418 112 символы (еще не использованы) могут быть закодированы 4, 5 или 6-ю байтами.
UCS-2: Каждый символ представлен 2-мя байтами. Данная кодировка включает лишь первые 65 535 символов из формата Unicode.
UTF-16:Является расширением UCS-2, включает 1 114 112 символов формата Unicode. Первые 65 535 символов представлены 2-мя байтами, остальные – 4-мя байтами.
USC-4: Каждый символ кодируется 4-мя байтами.
Получается, что 8 бит используются для кодирования европейских языков, а для китайского, японского и корейского языков много больше. Это может повлиять на объем занимаемого дискового пространства и на скорость передачи по сети. Для основных кодировок картина следующая (K(%) – увеличение дискового пространства и снижение скорости передачи по сети):
UTF-8: никаких изменений для американской ASCII, незначительное ухудшение (К = несколько %) для ISO-8859-1, К=50% для китайского, японского, корейского и К=100% для греческого и кириллицы.
UCS-2 и UTF-16: никаких изменений для китайского, японского, корейского; К=100% для американской ASCII, ISO-8859-1, греческого и кириллицы.
UCS-4: К=100% для китайского, японского, корейского; К=300% для американской ASCII, ISO-8859-1, греческого и кириллицы.
В итоге получается, что UTF-8 кодировка занимает меньше дискового пространства и позволяется передавать данные по сети с большей скоростью [10].Unicode 3.0
Стандарт Unicode был разработан с целью создания единой кодировки символов всех современных и многих древних письменных языков. Каждый символ в этом стандарте кодируется 16 битами, что позволяет ему охватить несравненно большее количество символов, чем принятые ранее 7- и 8-битовые кодировки. Еще одним важным отличием Unicode от других систем кодировки является то, что он не только приписывает каждому символу уникальный код, но и определяет различные характеристики этого символа, например:
тип символа (прописная буква, строчная буква, цифра, знак препинания и т.д.);
атрибуты символа (отображение слева направо или справа налево, пробел, разрыв строки и т.д.);
соответствующая прописная или строчная буква (для строчных и прописных букв соответственно);
соответствующее числовое значение (для цифровых символов).
Весь диапазон кодов от 0 до FFFF разбит на несколько стандартных подмножеств, каждое из которых соответствует либо алфавиту какого-то языка, либо группе специальных символов, сходных по своим функциям. На приведенной ниже схеме содержится общий перечень подмножеств Unicode 3.0
. 
Формат UTF-8: Стандарт Unicode является основой для хранения и текста во многих современных компьютерных системах. Однако, он не совместим с большинством Интернет-протоколов, поскольку его коды могут содержать любые байтовые значения, а протоколы обычно используют байты 00 – 1F и FE – FF в качестве служебных. Для достижения совместимости были разработаны несколько форматов преобразования Unicode (UTFs, Unicode Transformation Formats), из которых на сегодня наиболее распространенным является UTF-8. Этот формат определяет следующие правила преобразования каждого кода Unicode в набор байтов (от одного до трех), пригодных для транспортировки Интернет-протоколами.Таблица 2. Формат UTF-8.
Диапазон Unicode Двоичный код символа Байты UTF-8 (двоичные)
0000 – 007F 00000000 0zzzzzzz 0zzzzzzzz
0080 – 07FF 00000yyy yyzzzzzz 110yyyyy 10zzzzzz
0800 – FFFF xxxxyyyy yyzzzzzz 1110xxxx 10yyyyyy 10zzzzzz
Здесь x,y,z обозначают биты исходного кода, которые должны извлекаться, начиная с младшего, и заноситься в байты результата справа налево, пока не будут заполнены все указанные позиции.Формат UTF-16: Дальнейшее развитие стандарта Unicode связано с добавлением новых языковых плоскостей, т.е. символов в диапазонах 10000 – 1FFFF, 20000 – 2FFFF и т.д., куда предполагается включать кодировку для письменностей мертвых языков, не попавших в таблицу, приведенную выше. Для кодирования этих дополнительных символов был разработан новый формат UTF-16. Для базовой языковой плоскости, т.е. для символов с кодами от 0000 до FFFF, он совпадает с Unicode. Поэтому, если вы не собираетесь писать Веб-страницы на языке шумеров или майя, можете смело отождествлять два эти формата.
Файл. Форматы файлов
Файл – наименьшая единица хранения информации, содержащая последовательность байтов и имеющая уникальное имя.
Основное назначение файлов – хранить информацию. Они предназначены также для передачи данных от программы к программе и от системы к системе. Другими словами, файл – это хранилище стабильных и мобильных данных. Но, файл – это нечто большее, чем просто хранилище данных. Обычно файл имеет имя, атрибуты, время модификации и время создания.
Файловая структура представляет собой систему хранения файлов на запоминающем устройстве, например, на диске. Файлы организованы в каталоги (иногда называемые директориями или папками). Любой каталог может содержать произвольное число подкаталогов, в каждом из которых могут храниться файлы и другие каталоги.
Способ, которым данные организованы в байты, называется форматом файла.
Для того чтобы прочесть файл, например, электронной таблицы, нужно знать, каким образом байты представляют числа (формулы, текст) в каждой ячейке; чтобы прочесть файл текстового редактора, надо знать, какие байты представляют символы, а какие шрифты или поля, а также другую информацию. Все файлы условно можно разделить на две части – текстовые и двоичные. Текстовые файлы – наиболее распространенный тип данных в компьютерном мире. Для хранения каждого символа чаще всего отводится один байт, а кодирование текстовых файлов выполняется с помощью специальных таблиц, в которых каждому символу соответствует определенное число, не превышающее 255. Файл, для кодировки которого используется только 127 первых чисел, называется ASCII-файлом (сокращение от American Standard Code for Information Intercange – американский стандартный код для обмена информацией), но в таком файле не могут быть представлены буквы, отличные от латиницы (в том числе и русские). Большинство национальных алфавитов можно закодировать с помощью восьмибитной таблицы. Для русского языка наиболее популярны на данный момент три кодировки: Koi8-R, Windows-1251 и, так называемая, альтернативная (alt) кодировка.
Такие языки, как китайский, содержат значительно больше 256 символов, поэтому для кодирования каждого из них используют несколько байтов.Но чисто текстовые файлы встречаются все реже. Документы часто содержат рисунки и диаграммы, используются различные шрифты. В результате появляются форматы, представляющие собой различные комбинации текстовых, графических и других форм данных.
Двоичные файлы, в отличие от текстовых, не так просто просмотреть, и в них, обычно, нет знакомых слов – лишь множество непонятных символов. Эти файлы не предназначены непосредственно для чтения человеком. Примерами двоичных файлов являются исполняемые программы и файлы с графическими изображениями.
Не нашли то, что искали? Воспользуйтесь поиском:
Лучшие изречения: Увлечёшься девушкой-вырастут хвосты, займёшься учебой-вырастут рога 9815 –  | 7682 –
| 7682 –  или читать все.
или читать все.
78.85.5.224 © studopedia.ru Не является автором материалов, которые размещены. Но предоставляет возможность бесплатного использования. Есть нарушение авторского права? Напишите нам | Обратная связь.
Отключите adBlock!
и обновите страницу (F5)
очень нужно