Содержание
Лекция 7
Тема: «Дискретное представление информации»
План
1. Кодирование и декодирование информации в компьютере
2. Аналоговый и дискретный способы кодирования
3. Кодирование изображений
3.1. Кодирование растровых изображений
3.2. Кодирование векторных изображений
3.3. Графические форматы файлов
4. Двоичное кодирование звука
5. Представление видеоинформации
Кодирование и декодирование информации в компьютере
Вся информация, которую обрабатывает компьютер, должна быть представлена двоичным кодом с помощью двух цифр 0 и 1. Эти два символа принято называть двоичными цифрами или битами. С помощью 0 и 1 можно закодировать любое сообщение. Это явилось причиной того, что в компьютере обязательно должно быть организованно два важных процесса: кодирование и декодирование.
Кодирование – преобразование входной информации в форму, воспринимаемую компьютером, т.е. двоичный код.
Декодирование – преобразование данных из двоичного кода в форму, понятную человеку.
С точки зрения технической реализации использование двоичной системы счисления для кодирования информации оказалось намного более простым, чем применение других способов. Действительно, удобно кодировать информацию в виде последовательности нулей и единиц, если представить эти значения как два возможных устойчивых состояния электронного элемента:
0 – отсутствие электрического сигнала;
1 – наличие электрического сигнала.
Эти состояния легко различать. Недостаток двоичного кодирования – длинные коды. Но в технике легче иметь дело с большим количеством простых элементов, чем с небольшим числом сложных.
Вам приходится постоянно сталкиваться с устройством, которое может находится только в двух устойчивых состояниях: включено/выключено. Конечно же, это хорошо знакомый всем выключатель. А вот придумать выключатель, который мог бы устойчиво и быстро переключаться в любое из 10 состояний, оказалось невозможным. В результате после ряда неудачных попыток разработчики пришли к выводу о невозможности построения компьютера на основе десятичной системы счисления. И в основу представления чисел в компьютере была положена именно двоичная система счисления.
Способы кодирования и декодирования информации в компьютере, в первую очередь, зависят от вида информации, а именно, что должно кодироваться: числа, текст, графические изображения или звук.
Аналоговый и дискретный способ кодирования
Человек способен воспринимать и хранить информацию в форме образов (зрительных, звуковых, осязательных, вкусовых и обонятельных). Зрительные образы могут быть сохранены в виде изображений (рисунков, фотографий и так далее), а звуковые — зафиксированы на пластинках, магнитных лентах, лазерных дисках и так далее.
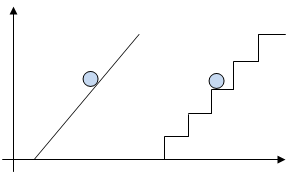 Информация, в том числе графическая и звуковая, может быть представлена в аналоговой или дискретной форме.
Информация, в том числе графическая и звуковая, может быть представлена в аналоговой или дискретной форме.
При аналоговом представлении физическая величина принимает бесконечное множество значений, причем ее значения изменяются непрерывно.
При дискретном представлении физическая величина принимает конечное множество значений, причем ее величина изменяется скачкообразно.
Приведем пример аналогового и дискретного представления информации. Положение тела на наклонной плоскости и на лестнице задается значениями координат X и У. При движении тела по наклонной плоскости его координаты могут принимать бесконечное множество непрерывно изменяющихся значений из определенного диапазона, а при движении по лестнице — только определенный набор значений, причем меняющихся скачкообразно.
Примером аналогового представления графической информации может служить, например, живописное полотно, цвет которого изменяется непрерывно, а дискретного — изображение, напечатанное с помощью струйного принтера и состоящее из отдельных точек разного цвета. Примером аналогового хранения звуковой информации является виниловая пластинка (звуковая дорожка изменяет свою форму непрерывно), а дискретного — аудиокомпакт-диск (звуковая дорожка которого содержит участки с различной отражающей способностью).
Преобразование графической и звуковой информации из аналоговой формы в дискретную производится путем дискретизации, то есть разбиения непрерывного графического изображения и непрерывного (аналогового) звукового сигнала на отдельные элементы. В процессе дискретизации производится кодирование, то есть присвоение каждому элементу конкретного значения в форме кода.
Дискретизация – это преобразование непрерывных изображений и звука в набор дискретных значений в форме кодов.
Не нашли то, что искали? Воспользуйтесь поиском:
Лучшие изречения: Сдача сессии и защита диплома – страшная бессонница, которая потом кажется страшным сном. 8800 –  | 7160 –
| 7160 –  или читать все.
или читать все.
78.85.5.224 © studopedia.ru Не является автором материалов, которые размещены. Но предоставляет возможность бесплатного использования. Есть нарушение авторского права? Напишите нам | Обратная связь.
Отключите adBlock!
и обновите страницу (F5)
очень нужно
Содержание урока
Дискретизация
Дискретизация
Ключевые слова:
В чём принципиальное различие между картиной, нарисованной красками, и мозаикой?
Давайте подумаем, что на самом деле происходит, когда мы записываем информацию с помощью какого-либо алфавита. При этом информация, существовавшая ранее у нас в сознании в виде мыслей, записывается в виде отдельных «кусочков», знаков. Так же и линия, нарисованная на бумаге, при сканировании представляется в памяти компьютера в виде отдельных элементов — пикселей. Такая процедура называется дискретизацией.
Дискретизацию мы используем и в жизни. Например, когда измеряют температуру воздуха, обычно округляют её до целых градусов, хотя температура изменяется непрерывно, а не скачками: она может быть равной и 18,25 o С, и 18,251 o С, и 18,2513 o С и т. д. Математики говорят, что множество дробных чисел непрерывно, потому что между двумя любыми дробными числами находится бесконечно много других дробных чисел. В то же время множество целых чисел дискретно, потому что между двумя целыми числами находится конечное число других целых чисел, и его легко подсчитать. Таким образом, при округлении мы выполняем дискретизацию данных.
 Дискретизация — это представление непрерывного объекта в виде множества отдельных элементов.
Дискретизация — это представление непрерывного объекта в виде множества отдельных элементов.
Картина художника — это непрерывный объект, а мозаика, сделанная на её основе, — дискретный. Переход от наскальных рисунков к алфавитному письму — это тоже переход от непрерывного способа представления информации к дискретному.
Все приборы, которые показывают результаты измерений в цифровом виде, выполняют дискретизацию. Например, стрелка в обычном спидометре автомобиля может принимать любое положение, это непрерывный (или, как говорят физики, аналоговый) прибор. А цифровой спидометр показывает дискретные данные — скорость с округлением до 1 км/ч (рис. 2.4).
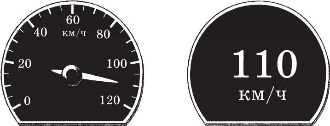
Может ли цифровой спидометр показать скорость 110,231 км/ч? Почему?
Обратите внимание, что в результате дискретизации мы теряем информацию. Заменив картину художника мозаикой, мы сделали её более грубой, потеряли тонкие детали. Но часто потеря информации допустима. Например, при округлении температуры вместо 18,2513 o С мы получили 18 o С, но нам этого достаточно для решения бытовых задач.
Как вы знаете, все виды информации в компьютере представлены в двоичном коде, как цепочки нулей и единиц. Это не случайно, потому что для хранения каждого бита в компьютере используется электронный блок с двумя состояниями. Поэтому компьютер — это дискретное устройство.
Для того чтобы ввести данные в компьютер, нужно выполнить их дискретизацию, например представить текст как набор букв, а рисунок — как набор пикселей. Затем каждому элементу (букве, пикселю) нужно присвоить двоичный код — битовую цепочку. Как это делается и какие бывают коды, вы узнаете далее.
Следующая страница  Равномерные коды
Равномерные коды
Cкачать материалы урока
Представление всей информации, которую обрабатывает компьютер с помощью двоичного кода, цифр 0 и 1. Важные процессы в компьютере: кодирование, декодирование. Аналоговый и дискретный способ кодирования, кодирование изображений. Графические форматы файлов.
| Рубрика | Программирование, компьютеры и кибернетика |
| Вид | реферат |
| Язык | русский |
| Дата добавления | 17.12.2017 |
| Размер файла | 151,1 K |

Отправить свою хорошую работу в базу знаний просто. Используйте форму, расположенную ниже
Студенты, аспиранты, молодые ученые, использующие базу знаний в своей учебе и работе, будут вам очень благодарны.
Министерство образования Пензенской области «Пензенский колледж информационных и промышленных технологий (ИТ- колледж)»
Отделение информационных технологий
но тему «Дискретное представление информации. Представление текстовой информации»
Выполнила студентка 2 курса
Преподаватель Антонова Е.Ю.
Вся информация, которую обрабатывает компьютер должна быть представлена двоичным кодом с помощью двух цифр 0 и 1. Эти два символа принято называть двоичными цифрами или битами. С помощью двух цифр 0 и 1 можно закодировать любое сообщение. Это явилось причиной того, что в компьютере обязательно должно быть организованно два важных процесса: кодирование и декодирование.
Кодирование – преобразование входной информации в форму, воспринимаемую компьютером, т.е. двоичный код.
Декодирование – преобразование данных из двоичного кода в форму, понятную человеку.
С точки зрения технической реализации использование двоичной системы счисления для кодирования информации оказалось намного более простым, чем применение других способов. Действительно, удобно кодировать информацию в виде последовательности нулей и единиц, если представить эти значения как два возможных устойчивых состояния электронного элемента:
0 – отсутствие электрического сигнала;
1 – наличие электрического сигнала.
Эти состояния легко различать. Недостаток двоичного кодирования – длинные коды. Но в технике легче иметь дело с большим количеством простых элементов, чем с небольшим числом сложных.
Вам приходится постоянно сталкиваться с устройством, которое может находится только в двух устойчивых состояниях: включено/выключено. Конечно же, это хорошо знакомый всем выключатель. А вот придумать выключатель, который мог бы устойчиво и быстро переключаться в любое из 10 состояний, оказалось невозможным. В результате после ряда неудачных попыток разработчики пришли к выводу о невозможности построения компьютера на основе десятичной системы счисления. И в основу представления чисел в компьютере была положена именно двоичная система счисления.
Способы кодирования и декодирования информации в компьютере, в первую очередь, зависит от вида информации, а именно, что должно кодироваться: числа, текст, графические изображения или звук.
Аналоговый и дискретный способ кодирования
Человек способен воспринимать и хранить информацию в форме образов (зрительных, звуковых, осязательных, вкусовых и обонятельных). Зрительные образы могут быть сохранены в виде изображений (рисунков, фотографий и так далее), а звуковые — зафиксированы на пластинках, магнитных лентах, лазерных дисках и так далее.
информация кодирование аналоговый дискретный
Информация, в том числе графическая и звуковая, может быть представлена в аналоговой или дискретной форме. При аналоговом представлении физическая величина принимает бесконечное множество значений, причем ее значения изменяются непрерывно. При дискретном представлении физическая величина принимает конечное множество значений, причем ее величина изменяется скачкообразно.
Приведем пример аналогового и дискретного представления информации. Положение тела на наклонной плоскости и на лестнице задается значениями координат X и У. При движении тела по наклонной плоскости его координаты могут принимать бесконечное множество непрерывно изменяющихся значений из определенного диапазона, а при движении по лестнице — только определенный набор значений, причем меняющихся скачкообразно.
Примером аналогового представления графической информации может служить, например, живописное полотно, цвет которого изменяется непрерывно, а дискретного — изображение, напечатанное с помощью струйного принтера и состоящее из отдельных точек разного цвета. Примером аналогового хранения звуковой информации является виниловая пластинка (звуковая дорожка изменяет свою форму непрерывно), а дискретного — аудиокомпакт-диск (звуковая дорожка которого содержит участки с различной отражающей способностью).
Преобразование графической и звуковой информации из аналоговой формы в дискретную производится путем дискретизации, то есть разбиения непрерывного графического изображения и непрерывного (аналогового) звукового сигнала на отдельные элементы. В процессе дискретизации производится кодирование, то есть присвоение каждому элементу конкретного значения в форме кода.
Дискретизация – это преобразование непрерывных изображений и звука в набор дискретных значений в форме кодов.
Создавать и хранить графические объекты в компьютере можно двумя способами – как растровое или как векторное изображение. Для каждого типа изображений используется свой способ кодирования.
Кодирование растровых изображений
Растровое изображение представляет собой совокупность точек (пикселей) разных цветов. Пиксель – минимальный участок изображения, цвет которого можно задать независимым образом.
В процессе кодирования изображения производится его пространственная дискретизация. Пространственную дискретизацию изображения можно сравнить с построением изображения из мозаики (большого количества маленьких разноцветных стекол). Изображение разбивается на отдельные маленькие фрагменты (точки), причем каждому фрагменту присваивается значение его цвета, то есть код цвета (красный, зеленый, синий и так далее).
Для черно-белого изображения информационный объем одной точки равен одному биту (либо черная, либо белая – либо 1, либо 0).
Для четырех цветного – 2 бита.
Для 8 цветов необходимо – 3 бита.
Для 16 цветов – 4 бита.
Для 256 цветов – 8 бит (1 байт).
Качество изображения зависит от количества точек (чем меньше размер точки и, соответственно, больше их количество, тем лучше качество) и количества используемых цветов (чем больше цветов, тем качественнее кодируется изображение).
Для представления цвета в виде числового кода используются две обратных друг другу цветовые модели: RGB или CMYK. Модель RGB используется в телевизорах, мониторах, проекторах, сканерах, цифровых фотоаппаратах… Основные цвета в этой модели: красный (Red), зеленый (Green), синий (Blue). Цветовая модель CMYK используется в полиграфии при формировании изображений, предназначенных для печати на бумаге.
Цветные изображения могут иметь различную глубину цвета, которая задается количеством битов, используемых для кодирования цвета точки.
Если кодировать цвет одной точки изображения тремя битами (по одному биту на каждый цвет RGB), то мы получим все восемь различных цветов.
На практике же, для сохранения информации о цвете каждой точки цветного изображения в модели RGB обычно отводится 3 байта (т.е. 24 бита) – по 1 байту (т.е. по 8 бит) под значение цвета каждой составляющей. Таким образом, каждая RGB-составляющая может принимать значение в диапазоне от 0 до 255 (всего 28=256 значений), а каждая точка изображения, при такой системе кодирования может быть окрашена в один из 16 777 216 цветов. Такой набор цветов принято называть True Color (правдивые цвета), потому что человеческий глаз все равно не в состоянии различить большего разнообразия.
Растровые изображения очень чувствительны к масштабированию (увеличению или уменьшению). При уменьшении растрового изображения несколько соседних точек преобразуются в одну, поэтому теряется различимость мелких деталей изображения. При увеличении изображения увеличивается размер каждой точки и появляется ступенчатый эффект, который можно увидеть невооруженным глазом.
Векторное изображение представляет собой совокупность графических примитивов (точка, отрезок, эллипс…). Каждый примитив описывается математическими формулами. Кодирование зависит от прикладной среды.
Достоинством векторной графики является то, что файлы, хранящие векторные графические изображения, имеют сравнительно небольшой объем.
Важно также, что векторные графические изображения могут быть увеличены или уменьшены без потери качества.
Графические форматы файлов
Форматы графических файлов определяют способ хранения информации в файле (растровый или векторный), а также форму хранения информации (используемый алгоритм сжатия).
Наиболее популярные растровые форматы:
Приведём примеры нормализации чисел:
– 0=0,0?100 (возможная нормализации нуля);
– 3,1415926=0,31415926?101 (количество значащих цифр не изменилось);
– 1000=0,1?104 (количество значащих цифр уменьшилось с четырёх до одной);
– 0,123456789=0,123456789?100 (запятую передвигать не нужно);
– 0,00001078=0,1078?8-4 (количество значащих цифр уменьшилось с семи до трёх);
– 1000,00012=0,100000012?24 (количество значащих цифр уменьшить невозможно).
При записи нормализованного числа в компьютере для записи мантиссы и порядка отводится заранее фиксированное количество разрядов. В компьютерном представлении вещественных чисел максимально допустимое количество цифр в мантиссе определяет точность, с которой может быть представлено число. Модуль разности между значением числа х и компьютерным его представлением х* называется абсолютной погрешностью представления х. Несмотря на то, что в абсолютном исчислении погрешность может быть значительно больше 1, относительно величины самого числа её порядок остаётся неизменным. Относительная погрешность представления х – величина х ? хх * .
Представление текстовой информации
Всякий текст состоит из символов – букв, цифр, знаков препинания и т.д., которые человек различает по начертанию. Однако для компьютерного представления текстовой информации такой метод неудобен, а для компьютерной обработки текстов и вовсе неприемлем. Поскольку текст изначально дискретен – он состоит из отдельных символов, – для компьютерного представления текстовой информации используется другой способ: все символы кодируются числами, и текст представляется в виде набора чисел – кодов символов, его составляющих. При выводе текста на экран монитора или принтер необходимо восстановит изображения всех символов, составляющих данный текст. Для этого используются кодовые таблицы символов, в которых каждому коду символа ставится в сообщение изображение символа. Все кодовые таблицы, используемые в любых компьютерах и любых операционных системах, подчиняются международным стандартам кодирования символов. На заре компьютерной эры, когда США были абсолютным лидером в этой области, стандарты разрабатывались Американским национальным институтом стандартизации (ANSI); впоследствии для разработки и принятия компьютерных стандартов была создана Международная организация стандартизации (ISO). В программировании наиболее часто используются однобайтовые кодировки: в них код каждого символа занимает ровно 1 байт, или 8 бит. При этом общее количество различаемых символов составляет 28 =256, а коды символов имеют значения от 0 до 255. Информационный объём блока информации называется количеством бит, байт или производных единиц (килобайт, мегабайт), необходимых для записи этого блока путём заранее оговоренного способа двоичного кодирования. Пример 6. Оценить в байтах объём текстовой информации в Словаре из 740 страниц, если на одной странице размещается в среднем 60 строк по 80 символов (включая пробелы). Будем считать, что при записи используется кодировка «один символ – один байт». Количество символов во всём словаре равно 80?60?740=3552000. следовательно, объём в байтах равен 3552000 байт = 3468,75 Кбайт?3,39 Мбайт. Основой для компьютерных стандартов кодирования послужил ASCII – американский стандартный код для обмена информацией, разработанный в 1960-х годах и применяемый в США для любых видов передачи информации, в том числе и некомпьютерных (телеграф, факсимильная связь и т.д.). В нём используется 7-битовое кодирование: общее количество символов составляет 27=128, из них первые 32 символа – управляющие, а остальные – «изображаемые», т.е. имеющие графическое изображение. Управляющие символы должны восприниматься устройством вывода текста как команды, например: К изображаемым символам в ASCII относятся буквы английского алфавита (прописные и строчные), цифры, знаки препинания и арифметических операций, скобки и некоторые специальные символы. Хотя в ASCII символы кодируются 7 битами, в памяти компьютера под каждый символ отводится ровно 1 байт, при этом код символа помещается в младшие биты, а старший бит не используется. Главный недостаток стандарта ASCII заключается в том, что он рассчитан на передачу только английского текста. Со временем возникла необходимость кодирования и неанглийских букв. Во многих странах для этого стали разрабатывать расширения ASCII- кодировки, в которых применялись однобайтовые коды символов; при этом первые 128 символов кодовой таблицы совпадали с кодировкой ASCII, а остальные (со 128-го по 255-й) использовались для кодирования букв национального алфавита, символов национальной валюты и т.п. Из-за несогласованности этих разработок для многих языков было создано по нескольку вариантов кодовых таблиц (например, для русского языка их около десятка!). КОИ8-Р является стандартом de facto для всех служб Интернета, кроме WWW. В частности, все службы электронной почты и новостей Рунета работают в этой кодировке. Что касается Веба, то здесь ситуация сложнее. Дело в том, что более 90% клиентских компьютеров Сети работает под управлением Windows разных версий. Windows использует собственную кодировку русских букв, которую принято назвать по номеру кодовой страницы Windows-1251 или CP1251. Поскольку текстовые редакторы и средства разработки HTML-страниц в Windows работают в этой кодировке, абсолютное большинство Веб-документов Рунета хранится в кодировке Windows-1251.
Если учесть, что в двоичном представлении для кодирования каждого символа используется 8-ми разрядный код, то получится двоичный код длиной в 64 символа.
Впоследствии использование кодовых таблиц было несколько упорядочено: каждой кодовой таблице было присвоено особое название и номер. Указав кодовую таблицу, автоматически выбирают и язык, которым можно пользоваться в дополнение к английскому; точнее, выбирается то, как будут интерпретироваться символы с кодами более 127. Для русского языка наиболее распространёнными являются однобайтовые кодовые таблицы CP-866 (Code Page), Windows-1251 и КОИ-8. В них первые 128 символов совпадают с ASCII-кодировкой, а русские буквы размещены во второй части таблицы, однако коды русских букв в этих кодировках различны! Сравните, например, кодировки КОИ-8 (Код Обмена Информацией 8-битовый, международное название koi-8r) и Windows-1251, вторые половины которых приведены в Табл.2 и 3 соответственно. Несовпадение кодовых таблиц приводит к ряду неприятных эффектов, например, т.к. один и тот же текст имеет различное компьютерное представление в разных кодировках, то текст, набранный в одной кодировке, будет нечитабельным в другой! Пример 8. Вот так будет выглядеть десятичный код слова «Диск» в разных кодировках: Однобайтовые кодировки обладают одним серьёзным ограничением: качество различных кодов символов в этих кодировках недостаточно велико, чтобы можно было пользоваться одновременно несколькими языками. Для устранения этого ограничения в 1993 году был разработан новый стандарт кодирования символов, получивший название Unicode, который, по замыслу его разработчиков, позволил бы использовать в текстах любые символы любых языков мира.
Интересно, что каждый символ текста имеет свой числовой код, но не каждому коду соответствует отображаемый на экране символ. Речь идет об управляющих символах, величина которых меньше шестнадцатиричного числа 20 (т.е. 32 в десятичной системе счисления). При получении этих кодов внешние устройства не изображают какого-либо символа, а выполняют те или иные управляющие действия. Так, код 07 вызывает подачу стандартного звукового сигнала, а код 0C – очистку экрана. Особую роль играют коды 0A (перевод строки, обозначаемый часто LF) и 0D (возврат каретки – CR). Первый вызывает перемещение в следующую строку без изменения позиции, а второй – на начало текущей строки. Таким образом, для перехода на начало новой строки требуются оба кода и в любом тексте эта «неразлучная пара» кодов хранится после каждой строки.
С точки зрения компьютера текст состоит из отдельных символов. К числу символов принадлежат не только буквы (заглавные или строчные, латинские или русские), но и цифры, знаки препинания, спецсимволы типа "=", "(", "&" и т.п. и даже пробелы между словами: пустое место в тексте тоже должно иметь свое обозначение. При нажатии клавиши клавиатуры сигнал посылается в компьютер в виде двоичного числа, которое хранится в кодовой таблице. Кодовая таблица – это внутреннее представление символов в компьютере. Например, буква S имеет код 01010011; при нажатии ее на клавиатуре происходит декодирование двоичного кода и по нему строится изображение символа на экране монитора. Каждый символ хранится в виде двоичного кода, который является номером символа. Можно сказать, что компьютер имеет собственный алфавит, где весь набор символов строго упорядочен. Количество символов в алфавите также тесно связано с двоичным представлением и у всех ЭВМ равняется 256. Иными словами, каждый символ всегда кодируется 8 битами, т.е. занимает ровно один байт. В компьютере хранится не начертание буквы, а её номер. Именно по этому номеру воспроизводится вид символа на экране дисплея или на бумаге. Поскольку алфавиты в различных типах ЭВМ не полностью совпадают, при переносе с одной модели на другую может произойти превращение разумного текста в «абракадабру». Такой эффект иногда получается даже на одной машине в различных программных средах: например, русский текст, набранный в MS DOS, нельзя без специального преобразования прочитать в Windows. Остается утешать себя тем, что задача перекодировки текста из одной кодовой таблицы в другую довольно проста и при наличии программ машина сама великолепно с ней справляется.