Содержание
- 1 Практическая работа №3 «Редактируем и форматируем текст. Создаем надписи» (задание 1)
- 2 Содержание
- 3 Функции памяти [ править | править код ]
- 4 Физические основы функционирования [ править | править код ]
- 5 Классификация типов памяти [ править | править код ]
- 5.1 Доступные операции с данными [ править | править код ]
- 5.2 Метод доступа [ править | править код ]
- 5.3 Организация хранения данных и алгоритмы доступа к ним [ править | править код ]
- 5.4 Назначение [ править | править код ]
- 5.5 Организация адресного пространства [ править | править код ]
- 5.6 Удалённость и доступность для процессора [ править | править код ]
- 5.7 Конспект урока "Представление текста в компьютере"
 |
 |

Тексты в памяти компьютера
Компьютер работает с четырьмя видами информации: текстовой, графической, числовой, звуковой.
Создание текстовых документов и хранение их на магнитных носителях в виде файлов является одним из самых массовых применений ЭВМ.
Преимущества работы с текстом на компьютере:
1)экономия бумаги;
2)компактное размещение;
3)возможность многократного использования магнитного носителя для хранения разных документов;
4)возможность быстрого копирования на другие носители;
5)возможность передачи текста по линиям компьютерной связи.
Преимущества компьютерного документа по сравнению с бумажным
А теперь от обсуждения вопроса о том, что представляет собой компьютер, перейдем к ответу на вопрос, что умеет делать компьютер. Начиная с этой главы, мы будем знакомиться с применением ЭВМ.
Первая область применения, которую мы рассмотрим, — работа с текстами. При ручной записи часто неприятную проблему составляет необходимость исправлять ошибки или вносить какие-то изменения в текст. При этом приходится зачеркивать, стирать, заклеивать, что портит вид текста. Необходимость переписывать текст ведет к потере времени и лишнему расходу бумаги.
Имея компьютер, можно создавать тексты, не тратя на это лишнее время и бумагу. Носителем текста становится память ЭВМ. Конечно, для длительного его сохранения это должна быть внешняя память — магнитные или оптические диски.
Текст на внешних носителях сохраняется в виде файла.
Есть ряд преимуществ сохранения текстов в файловой форме на компьютерных носителях по сравнению с бумагой.
Во-первых, это компактное размещение. Например, текст толстой книги в 500 страниц помещается на маленькую дискету диаметром 9 см. А если использовать специальные методы сжатия, то размер текста, помещающегося на дискете, можно увеличить в несколько раз.
Во-вторых, если данный текст становится ненужным, то дискету, как бумагу, не надо выбрасывать или сдавать в макулатуру. С нее с помощью компьютера легко стереть этот текст и на его место записать новый.
В-третьих, с помощью компьютера легко скопировать файлы в любом количестве на другие носители.
В-четвертых, файл с текстом можно быстро переслать другому человеку по электронной почте. Для этого ваш компьютер и компьютер адресата должны иметь связь через компьютерную сеть.
Главное неудобство хранения текстов в файлах состоит в том, что прочитать их можно только с помощью компьютера. Человек может просмотреть текст на экране дисплея или напечатать на бумаге, используя принтер.
Уже сейчас имеются некоторые издания, которые не печатаются на бумаге, а хранятся и распространяются в форме файлов. Когда компьютеры станут такими же обычными предметами в каждом доме, как сейчас радио и телевизор, то безбумажных изданий станет еще больше. Представьте себе, что вся ваша личная библиотека разместится в коробке с дисками. Причем по объему информации она будет не меньше, чем сотни книг, собранных родителями. А экономя бумагу, мы сохраняем леса на нашей планете.
Как представляются тексты в памяти компьютера
А теперь «заглянем» в память компьютера и разберемся, как же представлена в нем текстовая информация.
Текстовая информация состоит из символов: букв, цифр, знаков препинания, скобок и других. Мы уже говорили, что множество всех символов, с помощью которых записывается текст, называется алфавитом, а число символов в алфавите — его мощностью.
Для представления текстовой информации в компьютере используется алфавит мощностью 256 символов. Мы знаем, что один символ такого алфавита несет 8 битов информации: 28 = 256. 8 битов = 1 байт, следовательно:
Двоичный код каждого символа в компьютерном тексте занимает 1 байт памяти.
Теперь возникает вопрос, какой именно восьмиразрядный двоичный код поставить в соответствие каждому символу.
Понятно, что это дело условное, можно придумать множество способов кодирования.
Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот код — просто порядковый номер символа в двоичной системе счисления.
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки.
Для разных типов ЭВМ используются различные таблицы кодировки. С распространением персональных компьютеров типа IВМ РС международным стандартом стала таблица кодировки под названием АSCII (American Standart Code for Information Interchange — американский стандартный код для информационного обмена).
Точнее говоря, стандартной в этой таблице является только первая половина, т. е. символы с номерами от нуля (двоичный код 00000000) до 127 (01111111). Сюда входят буквы латинского алфавита, цифры, знаки препинания, скобки и некоторые другие символы. Остальные 128 кодов, начиная с 10000000 и кончая 11111111, используются в разных вариантах. В русских национальных кодировках в этой части таблицы размещаются символы русского алфавита.
В таблице 1 приведена стандартная часть кода АSCII (коды от 0 до 31 имеют особое назначение, не отражаются какими-либо знаками и в данную таблицу не включены). Здесь приведены десятичные номера символов, символы, двоичные коды.
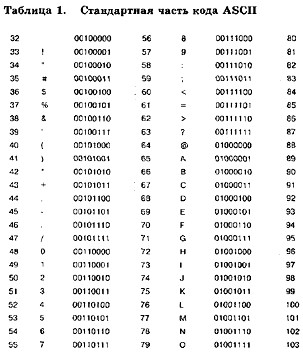
Обратите внимание на то, что в этой таблице латинские буквы (прописные и строчные) располагаются в алфавитном порядке. Расположение цифр также упорядочено по возрастанию значений. Это правило соблюдается и в других таблицах кодировки и называется принципом последовательного кодирования алфавитов. Благодаря этому понятие «алфавитный порядок» сохраняется и в машинном представлении символьной информации. Для русского алфавита принцип последовательного кодирования соблюдается не всегда.
Запишем, например, внутреннее представление слова «file». В памяти компьютера оно займет 4 байта со следующим содержанием:
01100110 01101001 01101100 01100101.
А теперь попробуйте решить обратную задачу. Какое слово записано следующим двоичным кодом:
01100100 01101001 01110011 01101011?
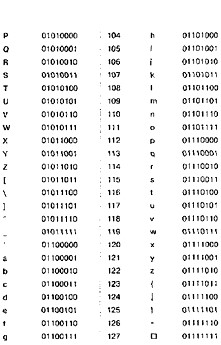
В таблице 2 приведен один из вариантов второй половины кодовой таблицы АSСII, который называется альтернативной кодировкой. Видно, что в ней для букв русского алфавита соблюдается принцип последовательного кодирования.
Тексты вводятся в память компьютера с помощью клавиатуры. На клавишах написаны привычные нам буквы, цифры, знаки препинания и другие символы. В оперативную память они попадают в форме двоичного кода.
Из памяти компьютера текст может быть выведен на экран или на печать в символьной форме. Но для долговременного хранения его следует записать на внешний носитель в виде файла.
Коротко о главном
С помощью компьютера можно создавать текстовые документы и хранить их на носителях внешней памяти в виде файлов.
Преимущества файлового хранения текстов: возможность редактирования, быстрого копирования на другие носители; возможность передачи текста по линиям компьютерной связи.
Каждый символ текста кодируется восьмиразрядным двоичным кодом. Для представления текстов в компьютере используется алфавит мощностью 256 символов.
В таблице кодировки каждому символу алфавита поставлен в соответствие порядковый номер и восьмиразрядный двоичный код. Международным стандартом является код АSСII — американский стандартный код для информационного обмена.
Практическая работа №3
«Редактируем и форматируем текст. Создаем надписи» (задание 1)
Задание 1
1. Откройте текстовый процессор MS Word.
2. С помощью меню Вид установите панель Рисование.
3. На панели Рисование найдите кнопку Вставить объект WordArt и с ее помощью вызовите коллекцию WordArt, содержащую различные варианты надписей.
4. Щелкните мышью на понравившейся вам надписи, затем — на кнопке ОК.
5. Рассмотрите раскрывшееся диалоговое окно Изменение текста WordArt. В нем можно выбирать шрифт, его размер и начертание. Нажав клавишу , очистите рабочее поле.
6. Введите текст надписи «ШКОЛА» и щелкните на кнопке ОК. На экране появится созданная вами красочная надпись.

7. Самостоятельно создайте еще три варианта надписей.
8. Созданные надписи можно перемещать, удалять, изменять. Для этого надпись нужно выделить. Выделите одну из надписей — поместите на нее указатель мыши и выполните щелчок левой кнопкой мыши. Надпись выделена, если вокруг нее появилась рамочка с квадратиками. Чтобы снять выделение, можно щелкнуть в любом месте вне надписи.
9. Измените расположение надписей на экране. Для этого:
1) выделите произвольную надпись;
2) удерживая нажатой левую кнопку мыши, перетащите надпись в другое место.
10. Оставьте на экране самую удачную надпись, а все другие удалите. Для этого:
1) выделяйте надписи;
2) нажимайте клавишу .
11. Выделите надпись. Обратите внимание на появившуюся панель WordArt. С ее помощью можно полностью изменить исходную надпись. Попытайтесь это сделать самостоятельно.

12. Сохраните файл в собственной папке под именем Школа и закройте программу.



Компью́терная па́мять (устройство хранения информации, запоминающее устройство) — часть вычислительной машины, физическое устройство или среда для хранения данных, используемая в вычислениях в течение определённого времени. Память, как и центральный процессор, является неизменной частью компьютера с 1940-х годов. Память в вычислительных устройствах имеет иерархическую структуру и обычно предполагает использование нескольких запоминающих устройств, имеющих различные характеристики.
В персональных компьютерах «памятью» часто называют один из её видов — динамическая память с произвольным доступом (DRAM), — которая используется в качестве ОЗУ персонального компьютера.
Задачей компьютерной памяти является хранение в своих ячейках состояния внешнего воздействия, запись информации. Эти ячейки могут фиксировать самые разнообразные физические воздействия. Они функционально аналогичны обычному электромеханическому переключателю и информация в них записывается в виде двух чётко различимых состояний — 0 и 1 («выключено»/«включено»). Специальные механизмы обеспечивают доступ (считывание, произвольное или последовательное) к состоянию этих ячеек.
Процесс доступа к памяти разбит на разделённые во времени процессы — операцию записи (сленг. прошивка, в случае записи ПЗУ) и операцию чтения, во многих случаях эти операции происходят под управлением отдельного специализированного устройства — контроллера памяти.
Также различают операцию стирания памяти — занесение (запись) в ячейки памяти одинаковых значений, обычно 0016 или FF16.
Наиболее известные запоминающие устройства, используемые в персональных компьютерах: модули оперативной памяти (ОЗУ), жёсткие диски (винчестеры), дискеты (гибкие магнитные диски), CD- или DVD-диски, а также устройства флеш-памяти.
Содержание
Функции памяти [ править | править код ]
Компьютерная память обеспечивает поддержку одной из функций современного компьютера, — способность длительного хранения информации. Вместе с центральным процессором запоминающее устройство являются ключевыми звеньями так называемой архитектуры фон Неймана, — принципа, заложенного в основу большинства современных компьютеров общего назначения.
Первые компьютеры использовали запоминающие устройства исключительно для хранения обрабатываемых данных. Их программы реализовывались на аппаратном уровне в виде жёстко заданных выполняемых последовательностей. Любое перепрограммирование требовало огромного объёма ручной работы по подготовке новой документации, перекоммутации, перестройки блоков и устройств и т. д. Использование архитектуры фон Неймана, предусматривающей хранение компьютерных программ и данных в общей памяти, коренным образом переменило ситуацию.
Любая информация может быть измерена в битах и потому, независимо от того, на каких физических принципах и в какой системе счисления функционирует цифровой компьютер (двоичной, троичной, десятичной и т. п.), числа, текстовая информация, изображения, звук, видео и другие виды данных можно представить последовательностями битовых строк или двоичными числами. Это позволяет компьютеру манипулировать данными при условии достаточной ёмкости системы хранения (например, для хранения текста романа среднего размера необходимо около одного мегабайта).
К настоящему времени создано множество устройств, предназначенных для хранения данных, основанных на использовании самых разных физических эффектов. Универсального решения не существует, у каждого имеются свои достоинства и свои недостатки, поэтому компьютерные системы обычно оснащаются несколькими видами систем хранения, основные свойства которых обуславливают их использование и назначение.
Физические основы функционирования [ править | править код ]
В основе работы запоминающего устройства может лежать любой физический эффект, обеспечивающий приведение системы к двум или более устойчивым состояниям. В современной компьютерной технике часто используются физические свойства полупроводников, когда прохождение тока через полупроводник или его отсутствие трактуются как наличие логических сигналов 0 или 1. Устойчивые состояния, определяемые направлением намагниченности, позволяют использовать для хранения данных разнообразные магнитные материалы. Наличие или отсутствие заряда в конденсаторе также может быть положено в основу системы хранения. Отражение или рассеяние света от поверхности CD, DVD или Blu-ray-диска также позволяет хранить информацию.
Классификация типов памяти [ править | править код ]
Следует различать классификацию памяти и классификацию запоминающих устройств (ЗУ). Первая классифицирует память по функциональности, вторая же — по технической реализации. Здесь рассматривается первая — таким образом, в неё попадают как аппаратные виды памяти (реализуемые на ЗУ), так и структуры данных, реализуемые в большинстве случаев программно.
Доступные операции с данными [ править | править код ]
- Память только для чтения (read-only memory, ROM)
- Память для чтения/записи
Память на программируемых и перепрограммируемых ПЗУ (ППЗУ и ПППЗУ) не имеет общепринятого места в этой классификации. Её относят либо к подвиду памяти «только для чтения» [1] , либо выделяют в отдельный вид.
Также предлагается относить память к тому или иному виду по характерной частоте её перезаписи на практике: к RAM относить виды, в которых информация часто меняется в процессе работы, а к ROM — предназначенные для хранения относительно неизменных данных [1] .
Метод доступа [ править | править код ]
- Последовательный доступ (англ. sequential access memory, SAM ) — ячейки памяти выбираются (считываются) последовательно, одна за другой, в очерёдности их расположения. Вариант такой памяти — стековая память.
- Произвольный доступ (англ. random access memory, RAM ) — вычислительное устройство может обратиться к произвольной ячейке памяти по любому адресу.
Организация хранения данных и алгоритмы доступа к ним [ править | править код ]
- Адресуемая память — адресация осуществляется по местоположению данных.
- Ассоциативная память (англ. associative memory, content-addressable memory, CAM ) — адресация осуществляется по содержанию данных, а не по их местоположению (память проверяет наличие ячейки с заданным содержимым, и если таковая(ые) присутствует(ют) возвращает её(их) адрес(а) или другие данные с ней(ними) ассоциированные).
- Магазинная (стековая) память (англ. pushdown storage ) — реализация стека.
- Матричная память (англ. matrix storage ) — ячейки памяти расположены так, что доступ к ним осуществляется по двум или более координатам.
- Объектная память (англ. object storage ) — память, система управления которой ориентирована на хранение объектов. При этом каждый объект характеризуется типом и размером записи.
- Семантическая память (англ. semantic storage ) — данные размещаются и списываются в соответствии с некоторой структурой понятийных признаков.
Назначение [ править | править код ]
- Буферная память (англ. buffer storage ) — память, предназначенная для временного хранения данных при обмене ими между различными устройствами или программами.
- Временная (промежуточная) память (англ. temporary (intermediate) storage ) — память для хранения промежуточных результатов обработки.
- Кеш-память (англ. cache memory ) — часть архитектуры устройства или программного обеспечения, осуществляющая хранение часто используемых данных для предоставления их в более быстрый доступ, нежели кэшируемая память.
- Корректирующая память (англ. patch memory ) — часть памяти ЭВМ, предназначенная для хранения адресов неисправных ячеек основной памяти. Также используются термины relocation table и remap table.
- Управляющая память (англ. control storage ) — память, содержащая управляющие программы или микропрограммы. Обычно реализуется в виде ПЗУ.
- Разделяемая память или память коллективного доступа (англ. shared memory, shared access memory ) — память, доступная одновременно нескольким пользователям, процессам или процессорам.
Организация адресного пространства [ править | править код ]
- Реальная или физическая память (англ. real (physical) memory ) — память, способ адресации которой соответствует физическому расположению её данных;
- Виртуальная память (англ. virtual memory ) — память, способ адресации которой не отражает физического расположения её данных;
- Оверлейная память (англ. overlayable storage ) — память, в которой присутствует несколько областей с одинаковыми адресами, из которых в каждый момент доступна только одна.
Удалённость и доступность для процессора [ править | править код ]
- Первичная память (сверхоперативная, СОЗУ) — доступна процессору без какого-либо обращения к внешним устройствам.
- регистры процессора (процессорная или регистровая память) — регистры, расположенные непосредственно в АЛУ;
- кэш процессора — кэш, используемый процессором для уменьшения среднего времени доступа к компьютерной памяти. Разделяется на несколько уровней, различающихся скоростью и объёмом (например, L1, L2, L3).
Положение структур данных, расположенных в основной памяти, в этой классификации неоднозначно. Как правило, их вообще в неё не включают, выполняя классификацию с привязкой к традиционно используемым видам ЗУ [2] .
Урок 28. Информатика 10 класс (ФГОС)
Конспект урока "Представление текста в компьютере"
· использование таблицы кодировок;
· информационный объём текста.
Компьютер может работать с пятью видами информации:

Одним из самых массовых приложений ЭВМ является работа с текстами.
Имея компьютер, можно создавать тексты, не тратя на это много времени и бумагу. Носителем текста становится память компьютера. Текст на внешних носителях сохраняется в виде файла.
Как вы уже знаете, вся информация, независимо от того, какая она графическая, видео или звуковая, представляется в компьютере с помощью чисел, это всего два символа двоичного кода, 0 и 1, которые легко перевести в сигналы.
Прежде всего, вспомним о байтовом принципе организации памяти компьютера.
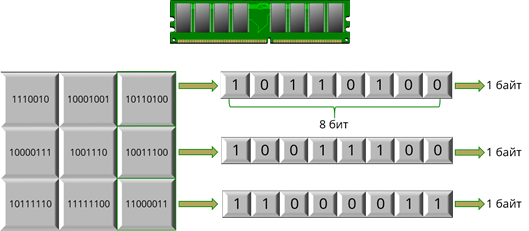
Как вы помните, каждая клетка обозначает бит памяти. Восемь подряд идущих битов образуют байт памяти. Байты пронумерованы. Порядковый номер байта определяет его адрес в памяти компьютера. По этим адресам процессор обращается к данным, считывает их или записывает в память.
Схема представления текста в памяти компьютера очень проста. Каждая буква алфавита, цифра, знак препинания или любой другой символ необходимый для записи текста обозначается определённым двоичным кодом, длина которого фиксирована.

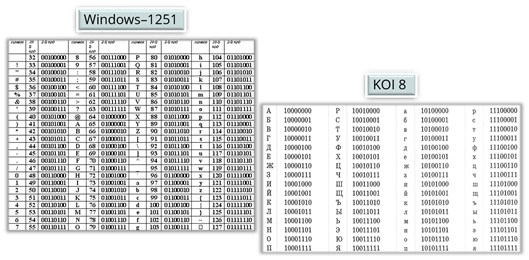
Например, в системах кодировки Windows – 1251 и KОИ-8 каждый символ заменяется на восьмиразрядное целое положительное двоичное число, оно хранится в одном байте памяти. Это число является порядковым номером символа в кодовой таблице.
Мы уже говорили о том, что разрядность ячейки памяти i и количество различных целых положительных чисел, которые можно записать в эту ячейку n связаны соотношением:
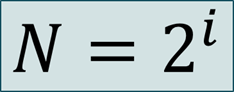
Восьмиразрядный двоичный код позволяет получить 256 различных кодовых комбинаций, то есть 2 8 = 256.
С помощью 256 кодовых комбинаций можно закодировать все символы двух алфавитов (английского и русского) и все остальные дополнительные символы, расположенные на клавиатуре компьютера — цифры и знаки арифметических операций, знаки препинания и скобки и так далее, а также ряд управляющих символов, без которых невозможно создание текстового документа (удаление предыдущего символа, переход на новую строку, пробел и другие).
Мощность алфавита равна 256 символов. Сколько Килобайт памяти потребуется для сохранения 160 страниц текста, содержащего в среднем 192 символа на каждой странице?

В современном мире около 6700 живых языков и около 25 алфавитов.
8-разрядной кодировки хватает, для того чтобы можно было одновременно пользоваться не более чем двумя языками. Для того чтобы на компьютере можно было устанавливать больше языков был разработан новый стандарт кодирования символов, получивший название Юникод.
Юнико́д или Унико́д (англ. Unicode) — стандарт кодирования символов, позволяющий представить знаки практически всех письменных языков.
Он является результатом сотрудничества Международной организации по стандартизации (ISO) с ведущими производителями компьютеров и программного обеспечения.
Этот стандарт был предложен в 1991 году некоммерческой организацией «Консорциум Юникода». С помощью этого стандарта можно закодировать очень большое число символов из разных письменностей: в документах Unicode могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы, при этом становится ненужным переключение кодовых страниц.
В Юникод каждый символ кодируется 16-битовым двоичным кодом, то есть два байта на символ. В данном случае можно закодировать 2 16 = 65536 различных символов.
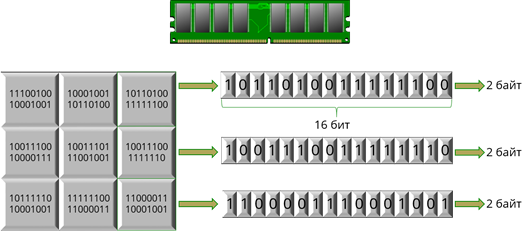
Однако в последнее время объединение Unicode приступило к кодированию письменности мёртвых языков и в этом случае 16-битового кодирования уже недостаточно. Поэтому Unicode приступил к освоению новых кодов.
Иногда, работая с электронной почтой, программа может запросить нас воспользоваться кодировкой Unicode для пересылаемых сообщений. В таком случае можно избавиться от проблемы несоответствия кодировок, по которой иногда не удаётся прочесть русский текст.
Текстовый документ, который хранится в памяти компьютера, состоит из кодов символьного алфавита, кодов управления форматами текста. Также текстовые процессоры, например, Microsoft Word позволяют включать и редактировать такие объекты как таблицы, оглавления, ссылки и гиперссылки, историю вносимых изменений и так далее. Все это также представляется в виде последовательности байтовых кодов.
Вам известно, что информационный объём сообщения I равен произведению количества символов К в сообщении умноженному на информационный вес символа алфавита i:
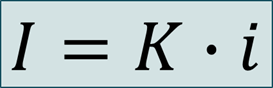
В зависимости от разрядности используемой кодировки информационный вес символа текста, создаваемого на компьютере, может быть равен:
• 8 бит или 1 байт — если используется восьмиразрядная кодировка;
• 16 бит или 2 байта — если используется шестнадцатиразрядная кодировка.
Информационным объёмом фрагмента текста будем называть количество битов, байтов или производных единиц (килобайтов, мегабайтов и так далее), необходимых для записи этого фрагмента заранее оговорённым способом двоичного кодирования.
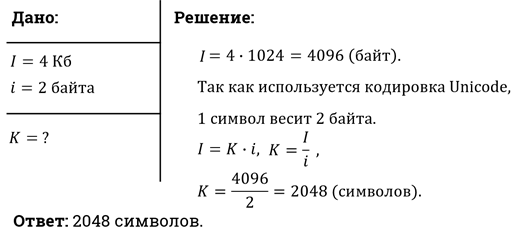
Информационный объем текста, набранного на компьютере с использованием кодировки UNICODE равен 4 Килобайта. Определить количество символов в тексте.
Как мы уже говорили бывают случаи, когда, работая с текстом, программа может запросить воспользоваться другой кодировкой, например, текст в восьмибитном коде Windows перекодировать в кодировку Unicode. Давайте выясним, что произойдёт с информационным объёмом текста.
Итак, рассмотрим такой пример.
Информационное сообщение на русском языке, первоначально записанное в 8-битной кодировке Windows, было перекодировано в 16-битную кодировку Unicode. В результате информационный объём сообщения стал равен 2 Мегабайта. Нужно найти количество символов в сообщении.

Соответствие между изображениями и кодами символов устанавливается с помощью кодовых таблиц.
Существуют 8-разрядные таблицы кодировки – это ASCII, КОИ-8 и другие. А также 16-разрядная кодовая таблица Юникод.
В зависимости от разрядности используемой кодировки информационный вес символа текста, создаваемого на компьютере, может быть равен:
• 8 бит (1 байт) — если используется 8-разрядная кодировка;
• 16 бит (2 байта) — если используется 16-разрядная кодировка.
Информационный объём фрагмента текста — это количество битов, байтов и производных единиц, необходимых для записи фрагмента оговорённым способом кодирования.