Содержание
Вводные слова
Кое-что о человеческой психологии
В прошлом году Нил Янг* и Стив Джобс обсуждали создание сервиса для скачивания аудио в «бескомпромиссном студийном качестве», а спустя некоторое время Нил Янг представил плеер Pono, который должен будет использоваться для воспроизведения этого аудио. В общем, эта идея нравится инвесторам, и они совсем недавно выделили $500,000 на популяризацию этого формата. По-сути, на что выделены эти деньги? На одурачивающий маркетинг. Почему этот маркетинг работает? Ну, он работает из-за существования парочки факторов.
Во-первых, при восприятии таких новостей люди зачастую основываются на догадках о том, как работает цифровое аудио, а не на том, как на самом деле оно работает: они предполагают, что увеличение частоты дискретизации аналогично увеличению количества кадров в секунду в видео. На самом деле такое увеличение аналогично добавлению инфракрасных и ультрафиолетовых цветов, которые мы никогда не увидим и видеть не можем в принципе. (Об этом повествует центральная часть статьи, но она будет чуть-чуть дальше.)
Во-вторых, люди могут считать, что слышат разницу в звуке, когда её на самом деле нет. Допускать такие ошибки мышления — это нормально для человека. Ошибки эти называются когнитивными искажениями. Подтверждение предубеждения, стадный инстинкт, эффект плацебо, доверие авторитету — это лишь некоторые когнитивные искажения, могущие заставить человека поверить в то, что он слышит разницу. Подтверждение предубеждения: «В 24/192 больше информации, значит я её должен слышать; о, слышу!» Стадный инстинкт вообще каким-то магическим образом заставляет людей верить в то, чего нет и быть не может. Доверие авторитету либо заставляет совершенно не критично относиться к информации, либо при сравнении со своим честным мнением отдавать предпочтение чужому мнению. В советском научно-популярном фильме «Я и другие» наглядно показываются некоторые социальные когнитивные искажения. Например, в фильме показывается следующий эксперимент: группе студентов показывают несколько портретов людей, и они должны сказать, на каких из двух портретов изображён один и тот же человек. Все студенты, кроме одного, — подставные и указывают на два портрета совершенно непохожих людей, а испытуемый, хоть изначально и не думал о таком варианте, зачастую соглашается с мнением большинства. Вы скажете: «Нет, ну я-то не такой». Вообще, вряд ли. Все мы люди, просто отличаемся тем, что в разной степени в чём-либо осведомлены. В любом случае, если бы люди не были подвластны таким когнитивным искажениям, то уже давно не работал бы маркетинг. Посмотрите кругом: люди покупают необоснованно дорогие товары и радуются этому.
Итак, 24/192 обычно не улучшает качество и это звучит как плохая новость. Хорошая новость заключается в том, что качество звучания улучшить несложно — достаточно просто купить хорошие наушники**. В конце концов улучшение качества звучания от них заметно сразу, оно не иллюзорно и радует. По крайней мере взяв наушники хотя бы в ценовом диапазоне от $100 до $200, вы будете радоваться и скажете мне спасибо за мой совет купить хорошие наушники, если, конечно, вы не купите красивые и дорогие имиджевые наушники, предназначенные совсем не для качественного воспроизведения аудио. А теперь давайте перейдём к самому интересному.
* Да, я тоже понятия не имел, кто такой Нил Янг. Оказывается, это известный канадский музыкант. уже 50 лет как известный.
** Это моё личное мнение, я не являюсь представителем каких-либо магазинов и не преследую никакой коммерческой цели.
Теорема Найквиста-Шеннона
Для того, чтобы не оказаться в ловушке мышления, попробуем с самых азов понять, из-за чего работает цифровое аудио.
Сначала чётко уясним термины (будем формулировать их так, будто они применяются только при анализе звуков).
Сигнал — функция, зависящая от времени. Например, как сигнал можно выразить электрическое напряжение в проводах аудиоаппаратуры или, скажем, давление звука на барабанную перепонку (в зависимости от момента времени).
Спектр — представление сигнала в зависимости от частоты, а не времени. Это означает, что функция выражается не как «громкость», записанная во времени, а как набор громкостей бесконечного количества гармоник (косинусоид), включенных в один и тот же момент времени. То есть изначальный сигнал может быть представлен как набор гармонических сигналов разных частот и амплитуд («громкостей»). Да, физические величины зачастую (на деле почти всегда) можно представлять таким «странным» образом (проведя преобразование Фурье над изначальной функцией). (Отображение значения спектра в произвольный момент времени — это один из самых наглядных способов изобразить визуально музыку в аудиоплеере. Замечу, что тот спектр, о котором я говорю, содержит информацию о всем промежутке времени, а не о каком-то мгновенном значении, т.к. по набору гармоник (спектру) можно воссоздать весь звуковой отрывок.)
Теорема Найквиста-Шеннона утверждает, что если сигнал имеет ограниченный спектр, то он может быть восстановлен по своим отсчётам, взятым с частотой, строго большей удвоенной верхней частоты fc: f > 2 fc. Если мы будем увеличивать частоту отсчётов, то это повлияет лишь на то, что формат цифрового аудио начнёт позволять записывать более высокие частоты — те, которые мы никак не воспринимаем. Кстати, в этой теореме говорится о сигнале, состоящем не из конечного набора частот, а из бесконечного, как в реальном звуке. Если говорить простым языком, то смысл теоремы заключается в том, что если мы возьмём какой-нибудь звуковой сигнал, содержащий только частоты, меньшие fc, и запишем (в файл) его значения через каждые 1/f секунды, то мы сможем потом воссоздать изначальный звуковой сигнал по этим значениям. Да-да, воссоздать полностью, без потери какого-либо качества вообще. Но формулировка не объясняет, как воссоздать этот звук. Вообще, это теорема из работы Найквиста «Certain topics in telegraph transmission theory» за 1928 год, в этой работе ничего не сказано про то, как воссоздать звук. А вот теорема Котельникова, предложенная и доказанная В.А. Котельниковым в 1933 году, объясняет это довольно чётко.
Теорема Котельникова


Вычитание k/(2f1) из t означает сдвиг шляпы в нужное место (в то самое место, где был записан отсчёт), а умножение на Dk означает растягивание этой шляпы по вертикали так, чтобы её макушка совпадала с точкой отсчёта. То есть теорема утверждает, что для воссоздания звука достаточно собрать шляпы в точках, соответствующих отсчётам, причём таким образом, чтобы вершины шляп совпадали с измерениями в отсчётах. Теорему оставим без доказательства — его можно найти в почти любой литературе по обработке сигналов. Однако обращу внимание на то, что воссоздание функции по теореме Котельникова не является просто сглаживанием. Да, шляпа не влияет на значения в соседних отсчётах, но влияет на значения между ними. И когда мы имеет низкочастотный сигнал, это может выглядеть как сглаживание, но если мы имеем, скажем высокочастотный косинус, то при его изображении в виде ступенек, мы даже не поймём, что это косинус — он будет казаться просто хаотичным набором отсчётов, однако, при восстановлении получится самый настоящий и идеально гладенький косинус.

Ну что же, математически понятно, что восстановить звук возможно. Чисто теоретически. И это не значит, что устройства воспроизведения цифрового звука воссоздают звук неотличимым от оригинального, это лишь значит, что аудиоформат позволяет такое сделать. А вот как правильно подкидывать мексиканские шляпы на выход цифро-аналогового преобразователя и как донести полученный звук до уха с минимальными искажениями — это уже совсем другая магия, не имеющая отношения к данной статье. К счастью для нас, добрые инженеры уже тысячу раз подумали над тем, как им решить для нас эту задачу.
Что дают 24 бита
При обсуждении применения теоремы Котельникова к цифровому аудио мы для простоты забыли, что при квантовании (оцифровке) числа Dk — это числа, записанные на компьютере, а, значит, это числа не любой точности, а какой-то определённой — той, что мы выберем для нашего аудиоформата. Это означает, что значения изначального сигнала записываются не точно, и это приводит к, вообще говоря, невозможности воссоздать оригинальный сигнал. Но как в реальности это влияет на воспринимаемый человеком звук при честном сравнении 16 и 24 битных сигналов? Проводились исследования, что лучше, 24/44 или 16/88 (да-да, именно так!), удвоение частоты качества не прибавило, а вот увеличение разрядности испытуемые определяли без проблем. В сторону 32 и 64 бит пока никто не смотрит, нет в природе устройств, которые бы могли реализовать потенциал 64-битного звука. А вот при внутренней обработке звука в музыкальных редакторах используют высокую разрядность под 64 бит и выше.
Давайте поговорим о громкости звука. Громкость звука — это субъективная величина, возрастающая очень медленно при увеличении звукового давления и зависит от него, амплитуды и частоты звука. Уровень громкости звука — это относительная величина, которая выражается в фонах и численно равна уровню звукового давления, создаваемого синусоидальным тоном частотой 1 кГц такой же громкости, как и измеряемый звук. Уровень звукового давления (sound pressure level, SPL) измеряется в дБ относительно порога слышимости синусоидальной волны в 1 кГц для человеческого уха, а при возрастании звукового давления в 2 раза, уровень звукового давления увеличивается на 6 дБ. Приведу несколько значений звукового давления:
- 20-30 дБ SPL – очень тихая комната (да-да, комната, в которой ничего не происходит).
- 40-50 дБ SPL – обычный разговор.
- 75 дБ SPL – крик, смех на расстоянии 1 метр.
- 85 дБ SPL – опасная для слуха громкость — повреждение при длительном воздействии 8 часов в день, для некоторых людей эта величина может быть меньше [Hearing damage]. Примерно такая громкость на автостраде в час пик [Sound pressure levels]. Не знаю как вы, но я на такой громкости никогда не слушаю музыку — это становится понятно, когда иду в закрытых накладных/охватывающих наушниках мимо шоссе и пытаюсь слушать музыку.
- 91 дБ SPL – повреждение слуха при воздействии 2 часа в день.
- 100 дБ SPL – это максимальное допустимое звуковое давление для наушников по нормам Евросоюза.
- 120 дБ SPL – почти невыносимо — болевой порог.
- 140 дБ SPL и выше — разрыв барабанной перепонки, баротравма или даже смерть.
Эта сводная таблица уровней громкости рассчитана на воспроизведение с акустических систем, где негативное влияние оказывает высокое звуковое давление на все тело.
В наушниках без особых проблем многие слушают под 130-140 дБ и никакого разрыва перепонки не случается. Слух попортить безусловно можно. Основные данные по болевым порогам получены от колонок, где наибольший вред наносят низкие частоты, которые действуют не столько на ухо, сколько на все тело, вводя в резонанс внутренние органы и разрушая их. Повредить грудную клетку от низких частот из наушников просто не реально. А вот в автомобиле от сабвуфера – в самый раз. Но более важно то, что таблица создавалась изначально под производственный шум на заводах. Ухо от наушников повредить можно на высокой громкости только в области верхних средних частот, где у уха есть собственный резонанс.
Эффективный же динамический диапазон 16-битного аудио — 96 дБ. Сравнивая 130 и 96 дБ становится понятно, что разницу в звуке мы услышать можем. Но чисто теоретически. Во-первых, 96 дБ — это величина отношения сигнал/шум в типичных источниках звука. Во-вторых, для популяризации форматов высокого разрешения на студиях часто сводят звук для CD и DVD-Audio с несколько разным усердием и в итоге покупатель может слышать посредственно сведённый материал в первом случае и хорошо сведенный во втором.
Последнее время стало модным выпускать ремастеры различных альбомов исполнителей. Но при этом большая часть таких ремастеров, сделанных на более новом оборудовании и в тяжеловесных форматах звучит существенно хуже, чем старые записи. Здесь возникает подозрение, что вместо качественного сведения талантливым звукорежиссером, все заменяется просто качественным оборудованием и уверенности, что это даст лучший результат, а если нет, то и так все раскупят.
Получается, что с позиции технических параметров 24 бит всегда будут лучше, чем 16, но услышать это можно на качественно сделанных записях, если сделать запись с радио, то там различить 16 и 24 бита будет очень сложно. Таким образом стоит гнаться не за высокими форматами, а за качественно записанными и сведенными записями и стремится к повышению качества аппаратуры.
Гонка к тяжеловесным форматам сопоставима с гонкой за мегапикселями фотоаппаратов, где любой профессионал знает, что итоговое качество от этого зависит довольно слабо.
В дорогих системах порой используют отдельную обработку в виде SRC как в Colorfly C4 Pro, что при переводе 44.1/16>192/24 позволяет перевести ЦАП в другой режим работы и заменить его блок цифровой фильтрации сигнала (от альязинга) более совершенным внешним SRC конвертером. Так же отдельно сконвертированные файлы из 44.1/16 в 192/24 порой могут звучать лучше, но именно из-за особенностей используемого ЦАП и это дает повод задуматься над апгрейдом системы в целом.
Надо отметить, что проверка различных DVD-Audio дисков порой выдавала удручающий результат, т.к. изначальный исходник для тяжеловесного формата был взят из стандартного CD-Audio.
Дополнительно
Ну что же, если наша цель заключается в том, чтобы наслаждаться звучанием, то осталось понять, что новость про бессмысленность 24/192 даже и не плохая вовсе — она, на самом деле говорит о том, что качество звука улучшить можно, но для этого не надо гнаться за тяжеловесными форматами.
Но раз существует как минимум два мнения по поводу «16/44.1 против 24/192», то, может быть есть и ещё какие-то иные и интересные мнения? Да, есть. Как минимум есть ещё две интересные статьи с неожиданными выводами: «Coding High Quality Digital Audio» от J. Robert Stuart (статья на английском) и «24/192 Music Downloads. and why they make no sense» от Monty, разработчика формата OGG (эта статья тоже на английском, она утверждает, что 24 бита тоже бессмысленны).
Сохранить и прочитать потом —
Прим. перев.: Это перевод второй (из четырех) частей развернутой статьи Кристофера «Монти» Монтгомери (создателя Ogg Free Software и Vorbis) о том, что, по его мнению, является одним из наиболее распространенных и глубоко укоренившихся заблуждений в мире меломанов.
Частота 192 кГц считается вредной
Музыкальные цифровые файлы с частотой 192 кГц не приносят никакой выгоды, но всё же оказывают кое-какое влияние. На практике оказывается, что их качество воспроизведения немного хуже, а во время воспроизведения возникают ультразвуковые волны.
И аудиопреобразователи, и усилители мощности подвержены влиянию искажений, а искажения, как правило, быстро нарастают на высоких и низких частотах. Если один и тот же динамик воспроизводит ультразвук наряду с частотами из слышимого диапазона, то любая нелинейная характеристика будет сдвигать часть ультразвукового диапазона в слышимый спектр в виде неупорядоченных неконтролируемых нелинейных искажений, охватывающих весь слышимый звуковой диапазон. Нелинейность в усилителе мощности приведет к такому же эффекту. Эти эффекты трудно заметить, но тесты подтвердили, что оба вида искажений можно расслышать.
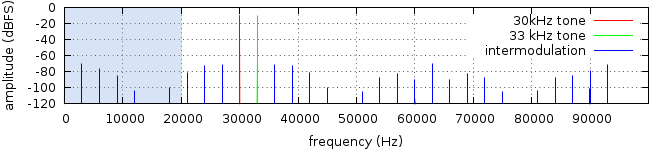
График выше показывает искажения, полученные в результате интермодуляции звука частотой 30 кГц и 33 кГц в теоретическом усилителе с неизменным коэффициентом нелинейных искажений (КНИ) около 0.09%. Искажения видны на протяжении всего спектра, даже на меньших частотах.
Неслышимые ультразвуковые волны способствуют интермодуляционным искажениям в слышимом диапазоне (светло-синяя зона). Системы, не предназначенные для воспроизведения ультразвука, обычно имеют более высокие уровни искажений, около 20 кГц, дополнительно внося вклад в интермодуляцию. Расширение диапазона частот для включения в него ультразвука требует компромиссов, которые уменьшат шум и активность искажений в пределах слышимого спектра, но в любом случае ненужное воспроизведение ультразвуковой составляющей ухудшит качество воспроизведения.
Есть несколько способов избежать дополнительных искажений:
- Динамик, предназначенный только для воспроизведения ультразвука, усилитель и разделитель спектра сигнала, чтобы разделить и независимо воспроизводить ультразвук, который вы не можете слышать, чтобы он не влиял на другие звуки.
- Усилители и преобразователи, спроектированные для воспроизведения более широкого спектра частот так, чтобы ультразвук не вызывал слышимых нелинейных искажений. Из-за дополнительных затрат и сложности исполнения, дополнительный частотный диапазон будет уменьшать качество воспроизведения в слышимой части спектра.
- Качественно спроектированные динамики и усилители, которые совсем не воспроизводят ультразвук.
- Для начала можно не кодировать такой широкий диапазон частот. Вы не можете (и не должны) слышать ультразвуковые нелинейные искажения в слышимой полосе частот, если в ней нет ультразвуковой составляющей.
Все эти способы нацелены на решение одной проблемы, но только 4 способ имеет какой-то смысл.
Если вам интересны возможности вашей собственной системы, то нижеследующие сэмплы содержат: звук частотой 30 кГц и 33 кГц в формате 24/96 WAV, более длинную версию в формате FLAC, несколько мелодий и нарезку обычных песен с частотой, приведенной к 24 кГц так, что они полностью попадают в ультразвуковой диапазон от 24 кГц до 46 кГц.
Тесты для измерения нелинейных искажений:
- Звук 30 кГц + звук 33 кГц (24 бит / 96 кГц) [5-секундный WAV] [30-секундный FLAC]
- Мелодии 26 кГц – 48 кГц (24 бит / 96 кГц) [10-секундный WAV]
- Мелодии 26 кГц – 96 кГц (24 бит / 192 кГц) [10-секундный WAV]
- Нарезка из песен, приведенных к 24 кГц (24 бит / 96 кГц WAV) [10-секундный WAV] (оригинальная версия нарезки) (16 бит / 44.1 кГц WAV)
Предположим, что ваша система способна воспроизводить все форматы с частотами дискретизации 96 кГц [6]. При воспроизведении вышеуказанных файлов, вы не должны слышать ничего, ни шума, ни свиста, ни щелчков или каких других звуков. Если вы слышите что-то, то ваша система имеет нелинейную характеристику и вызывает слышимые нелинейные искажения ультразвука. Будьте осторожны при увеличении громкости, если вы попадете в зону цифрового или аналогового ограничения уровня сигнала, даже мягкого, то это может вызвать громкий интермодуляционный шум.
В целом, не факт, что нелинейные искажения от ультразвука будут слышимы на конкретной системе. Вносимые искажения могут быть как незначительны, так и довольно заметны. В любом случае, ультразвуковая составляющая никогда не является достоинством, и во множестве аудиосистем приведет к сильному снижению качества воспроизведения звука. В системах, которым она не вредит, возможность обработки ультразвука можно сохранить, а можно вместо этого пустить ресурс на улучшение качества звучания слышимого диапазона.
Недопонимание процесса дискретизации
Теория дискретизации часто непонятна без контекста обработки сигналов. И неудивительно, что большинство людей, даже гениальные доктора наук в других областях, обычно не понимают её. Также неудивительно, что множество людей даже не осознают, что понимают её неправильно.
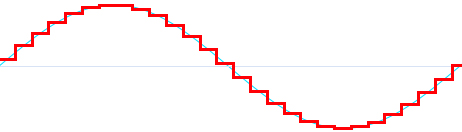
Дискретизированные сигналы часто изображают в виде неровной лесенки, как на рисунке выше (красным цветом), которая выглядит как грубое приближение к оригинальному сигналу. Однако такое представление является математически точным, и когда происходит преобразование в аналоговый сигнал, его график становится гладким (голубая линия на рисунке).
Наиболее распространенное заблуждение заключается в том, что, якобы, дискретизация – процесс грубый и приводит к потерям информации. Дискретный сигнал часто изображается как зубчатая, угловатая ступенчатая копия оригинальной идеально гладкой волны. Если вы так считаете, то можете считать, что чем больше частота дискретизации (и чем больше бит на отсчет), тем меньше будут ступеньки и тем точнее будет приближение. Цифровой сигнал будет все больше напоминать по форме аналоговый, пока не примет его форму при частоте дискретизации, стремящейся к бесконечности.
По аналогии, множество людей, не имеющих отношения к цифровой обработке сигналов, взглянув на изображение ниже, скажут: «Фу!» Может показаться, что дискретный сигнал плохо представляет высокие частоты аналоговой волны, или, другими словами, при увеличении частоты звука, качество дискретизации падает, и частотная характеристика ухудшается или становится чувствительной к фазе входного сигнала.
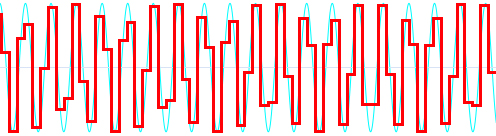
Это только так выглядит. Эти убеждения неверны!
Комментарий от 04.04.2013: В качестве ответа на всю почту, касательно цифровых сигналов и ступенек, которую я получил, покажу реальное поведение цифрового сигнала на реальном оборудовании в нашем видео Digital Show & Tell, поэтому можете не верить мне на слово.
Все сигналы частотой ниже частоты Найквиста (половина частоты дискретизации) в ходе дискретизации будут захвачены идеально и полностью, и бесконечно высокая частота дискретизации для этого не нужна. Дискретизация не влияет на частотную характеристику или фазу. Аналоговый сигнал может быть восстановлен без потерь – таким же гладким и синхронным как оригинальный.
С математикой не поспоришь, но в чем же сложности? Наиболее известной является требование ограничения полосы. Сигналы с частотами выше частоты Найквиста должны быть отфильтрованы перед дискретизацией, чтобы избежать искажения из-за наложения спектров. В роли этого фильтра выступает печально известный сглаживающий фильтр. Подавление помехи дискретизации, на практике, не может пройти идеально, но современные технологии позволяют подойти к идеальному результату очень близко. А мы подошли к избыточной дискретизации.
Частоты дискретизации свыше 48 кГц не имеют отношения к высокой точности воспроизведения аудио, но они необходимы для некоторых современных технологий. Избыточная дискретизация (передискретизация) – наиболее значимая из них [7].
Идея передискретизации проста и изящна. Вы можете помнить из моего видео «Цифровое мультимедиа. Пособие для начинающих гиков», что высокие частоты дискретизации обеспечивают гораздо больший разрыв между высшей частотой, которая нас волнует (20 кГц) и частотой Найквиста (половина частоты дискретизации). Это позволяет пользоваться более простыми и более надежными фильтрами сглаживания и увеличить точность воспроизведения. Это дополнительное пространство между 20 кГц и частотой Найквиста, по существу, просто амортизатор для аналогового фильтра.
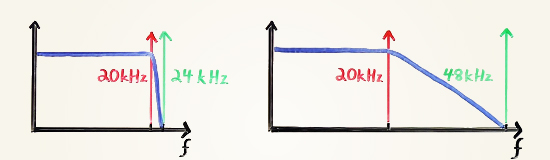
На рисунке выше представлены диаграммы из видео «Цифровое мультимедиа. Пособие для начинающих гиков», иллюстрирующие ширину переходной полосы для ЦАП или АЦП при частоте 48 кГц (слева) и 96 кГц (справа).
Это только половина дела, потому что цифровые фильтры имеют меньше практических ограничений в отличие от аналоговых, и мы можем завершить сглаживание с большей точностью и эффективностью. Высокочастотный необработанный сигнал проходит сквозь цифровой сглаживающий фильтр, который не испытывает проблем с размещением переходной полосы фильтра в ограниченном пространстве. После того, как сглаживание завершено, дополнительные дискретные отрезки в амортизирующем пространстве просто откидываются. Воспроизведение передискретизированного сигнала проходит в обратном порядке.
Это означает, что сигналы с низкой частотой дискретизации (44.1 кГц или 48 кГц) могут обладать такой же точностью воспроизведения, гладкостью АЧХ и низким уровнем наложений, как сигналы с частотой дискретизации 192 кГц или выше, но при этом не будет проявляться ни один из их недостатков (ультразвуковые волны, вызывающие интермодуляционные искажения, увеличенный размер файлов). Почти все современные ЦАП и АЦП производят избыточную дискретизацию на очень высоких скоростях, и мало кто об этом знает, потому что это происходит автоматически внутри устройства.
ЦАП и АЦП не всегда умели передискретизировать. Тридцать лет назад некоторые звукозаписывающие консоли использовали для звукозаписи высокие частоты дискретизации, используя только аналоговые фильтры. Этот высокочастотный сигнал потом использовался для создания мастер-дисков. Цифровое сглаживание и децимация (повторная дискретизация с более низкой частотой для CD и DAT) происходили на последнем этапе создания записи. Это могло стать одной из ранних причин, почему частоты дискретизации 96 кГц и 192 кГц стали ассоциироваться с производством профессиональных звукозаписей.
16 бит против 24 бит
Хорошо, теперь мы знаем, что сохранять музыку в формате 192 кГц не имеет смысла. Тема закрыта. Но что насчет 16-битного и 24-битного аудио? Что же лучше?
16-битное аудио с импульсно-кодовой модуляцией действительно не полностью покрывает теоретический динамический звуковой диапазон, который способен слышать человек в идеальных условиях. Также есть (и будут всегда) причины использовать больше 16 бит для записи аудио.
Ни одна из этих причин не имеет отношения к воспроизведению звука – в этой ситуации 24-битное аудио настолько же бесполезно, как и дискретизация на 192 кГц. Хорошей новостью является тот факт, что использование 24-битного квантования не вредит качеству звучания, а просто не делает его хуже и занимает лишнее место.
Примечания к Части 2
6. Многие из систем, которые неспособны воспроизводить сэмплы 96 кГц, не будут отказываться их воспроизводить, а будут незаметно субдискретизировать их до частоты 48 кГц. В этом случае звук не будет воспроизводиться совсем, и на записи ничего не будет, вне зависимости от степени нелинейности системы.
7. Передискретизация – не единственный способ работы с высокими частотами дискретизации в обработке сигналов. Есть несколько теоретических способов получить ограниченный по полосе звук с высокой частотой дискретизации и избежать децимации, даже если позже он будет субдискретизирован для записи на диски. Пока неясно, используются ли такие способы на практике, поскольку разработки большинства профессиональных установок держатся в секрете.
8. Неважно, исторически так сложилось или нет, но многие специалисты сегодня используют высокие разрешения, потому что ошибочно полагают, что звук с сохраненным содержимым за пределами 20 кГц звучит лучше. Прямо как потребители.


Лаборатория «ЧИП и ДИП» представляет новый модуль – AD1938 CODEC. Это высококачественный кодек, содержащий четыре аналого-цифровых преобразователя (АЦП) и восемь цифро-аналоговых преобразователей (ЦАП), который построен на чипе AD1938 производящим все преобразования на основе патентованной многоразрядной сигма-дельта (Σ-Δ) архитектуре компании Analog Devices. Модуль имеет SPI порт, с помощью которого внешний микроконтроллер может регулировать громкость и многие другие параметры. Также к этому порту, через USBi преобразователь, можно подключить фирменное программное обеспечение – SigmaStudio и в реальном времени оценить возможности всех встроенных АЦП и ЦАП.
Частота семплирования всех преобразователей настраивается и может быть 41.1кГц, 48кГц, 96кГц или 192кГц, а точность преобразования 24 бита. На входе АЦП стоят ОУ ADA4841 с низким уровнем шума и искажений. Они подключены как активные фильтры нижних частот и одновременно преобразователи несимметричного входного аудио сигнала в дифференциальные сигналы для аналоговых входов АЦП. Модуль тактируется от сигнала внешнего LR-генератора или встроенного кварцевого резонатора при помощи интегрированной схемы ФАПЧ.
Мы рекомендуем использовать этот модуль с процессорами ADAU1452, так как этот мощный чип предназначенный для беспрецедентной обработки звука не имеет собственных АЦП и ЦАП. Но не исключено, что в своих проектах вы будете подключать его к ADAU1701 или нашему USB I2S преобразователю Super Prime.
Проект, как всегда, открытый и вы можете изучить схему из производственных файлов в формата KiCad. Исходники ПО и прошивки на сайте.
Пять дней в одном письме – расскажем, что это было и как это работает. Подписаться на новости из Лаборатории CHIPDIP.