Содержание

Схема базы данных включает в себя описания содержания, структуры и ограничений целостности, используемые для создания и поддержки базы данных [1] .
Постоянные данные в среде базы данных включают в себя схему и базу данных. Система управления базами данных (СУБД) использует определения данных в схеме для обеспечения доступа и управления доступом к данным в базе данных [1] .
Содержание
Схема как структура данных [ править | править код ]

Схема данных (от англ. Database schema) — её структура, описанная на формальном языке, поддерживаемом СУБД. В реляционных базах данных схема определяет таблицы, поля в каждой таблице (обычно с указанием их названия, типа, обязательности), и ограничения целостности (первичный, потенциальные и внешние ключи и другие ограничения).
Схемы в общем случае хранятся в словаре данных. Хотя схема определена на языке базы данных в виде текста, термин часто используется для обозначения графического представления структуры базы данных [2] .
Основными объектами графического представления схемы являются таблицы и связи, определяемые внешними ключами.
Схема как объект данных [ править | править код ]
Есть и другое понятие схемы в теории баз данных.
Схема (SCHEMA) [3] является одним из основных объектов базы данных Oracle Database. Близкое понятие (RIS Schema) существует в RIS-интерфейсе доступа к базам данных. SCHEMA также появилась и в Microsoft SQL Server 2005 и формально определяется как набор объектов в базе данных [4] .
В Oracle схема привязывается только к одному пользователю (USER) и является логическим набором объектов базы данных. Схема создаётся при создании пользователем первого объекта, и все последующие объекты, созданные этим пользователем, становятся частью этой схемы.
Схема может включать другие объекты, принадлежащие этому пользователю:
- таблицы,
- последовательности,
- хранимые программы,
- кластеры,
- связи баз данных,
- триггеры,
- библиотеки внешних процедур,
- индексы,
- пакеты,
- хранимые функции и процедуры,
- синонимы,
- представления,
- снимки,
- объектные таблицы,
- объектные типы,
- объектные представления.
Существуют и подобъекты схемы, такие как:
- столбцы: таблиц и представлений,
- секции таблиц,
- ограничения целостности,
- триггеры,
- пакетные процедуры и функции и другие элементы, хранимые в пакетах (курсоры, типы и т. п).
Существуют объекты, независимые от схемы:
- каталоги,
- профили,
- роли,
- сегменты,
- табличные области,
- пользователи.
Способы создания базы данных
Как уже упоминалось, разработку базы данных лучше всего начать с составления блок-схемы, чтобы зафиксировать на бумаге все связи между таблицами. Это поможет избавиться от многих недостатков на самом начальном этапе
Блок-схема базы данных состоит из диаграмм связей между объектами, или Entity Relationship Diagram (ERD). ERD точно отображает структуру базы данных, связи между таблицами, правила и триггеры, которые поддерживают целостность данных базы данных. Большим преимуществом ERD является то, что вы можете обсудить с заказчиком структуру базы данных и убедиться в том, что она соответствует его потребностям.
Иногда вам может понадобиться реализовать немного модифицированный или не так часто используемый тип ERD. В таких случаях лучше всего выяснить возможности программного обеспечения, продумать структуру базы данных, обратиться к ресурсам, имеющимся в Internet, и другим источникам информации, которые помогут вам правильно построить ERD.
ERD: блок-схемы для баз данных
Схемы ERD включают в себя несколько различных элементов, таких как объекты, атрибуты и связи. Существует несколько способов описания различных элементов системы. На рис. 7 показано, как выглядит схема базы данных системы продаж, обсуждаемой выше.
Как видите, в обсуждаемую в предыдущих разделах базу данных добавлена таблица заказчиков, с помощью которой можно проследить, что заказывали конкретные покупатели. Но во всем остальном структура базы данных (т.е. таблицы и связи между ними) полностью соответствует описанной выше системе продаж. А теперь давайте рассмотрим, как используются в этой простой модели объекты, атрибуты и связи.

Рис. 7. Схема базы данных системы продаж
Объекты и связи между ними
На рис. 8 вы видите четыре прямоугольника. Каждый из них представляет таблицу, или объект. Эти объекты являются таблицами базы данных. В свою очередь, в каждом прямоугольнике содержатся элементы, которые представляют собой заголовки столбцов таблицы. Причем элементы в прямоугольниках делятся на две группы: расположенные над раздели» тельной линией и под ней.
Присваивайте объектам уникальные имена. Тогда в разрабатываемой вами системе каждый объект будет встречаться только один раз, и вы сможете избежать путаницы.
Элементы, находящиеся над разделительной линией, представляют собой идентификаторы. Помните, в нормализованной базе данных 3NF нам нужно было присвоить каждой строке таблицы уникальный идентификатор. Когда идентификаторы находятся над разделительной линией, сразу видно, с помощью каких элементов будет (в большинстве случаев) осуществляться выборка записи из базы данных.
Как видно из рис. 8, записи из таблицы Customer, вероятнее всего, будут извлекаться из базы данных с помощью идентификатора CustomerID.
Для выборки записи из базы данных чаще всего используется идентификатор, но это не единственный способ. Например, вам может понадобиться осуществить поиск некоторых имен в таблице customer. В этом случае в поиске не будет использован идентификатор CustomerID, но после того как вы найдете имя нужного заказчика, скорее всего, извлечете значение CustomerID, а затем и всю запись (т.е. всю строку информации) для данного заказчика.

Рис. 8. Объект представлен в виде прямоугольника, в котором обычно содержится две группы элементов
Атрибуты и связи между ними
Таблица, или объект, состоит из столбцов. Таким образом, атрибуты — это столбцы в таблице базы данных. Атрибутами таблицы Customer являются: CustomerID, Name, Company и т.д. Атрибуты могут быть ключевыми (key) и неключевыми (non-key). (Ключевые атрибуты мы иногда будем называть просто ключами).
Ключевые атрибуты — это элементы, благодаря которым осуществляется связь между Объектами (таблицами). А неключевые атрибуты — это элементы, которые не связаны с другими объектами (таблицами) базы данных.
Ключевые атрибуты могут быть двух различных типов: основные и неосновные. Основные ключевые атрибуты всегда находятся над разделительной линией; они являются определяющими атрибутами (идентификаторами) данного объекта. Если атрибут является ключевым, но не относится к идентификаторам, то он находится под разделительной линией. Такой ключевой атрибут называется неосновным.
Если элемент связан с ключевым атрибутом из другой таблицы, то он называется внешним ключом. Как видите, в нашей модели (рис. 4.9) в таблице Customer нет внешних ключей, а в таблице Order есть (этот элемент помечен буквами "FK"). Внешний ключ из таблицы Order не является идентификатором, но помогает определить, какой заказчик сделал заказ. А теперь перейдем от таблицы Order к таблице Line Item. Как видите, элементы ItemCode, OrderNumber и OrderItemID являются идентификаторами таблицы Line Item. Это означает, что для нахождения некоторого заказанного товара нужно знать элементы – OrderItemID, ItemCode и OrderNumber. В данной модели таблица Line является связующим звеном между таблицами Inventory и Order.

Рис. 9 На этой схеме данных показаны основные (идентификаторы) и неосновные внешние ключи
Чтобы оценить, насколько правильно разработана структура базыданных,нужно проверить связи, установленные между различными объектами. А для этого лучше всего воспользоваться схемой ERD. Как видите, на рис. 9 между объектами стоят глаголы. Они описывают связи между двумя объектами; признаком связи служит также линия связи, соединяющая объекты.
Заказчик делает (makes) заказ в таблице Order, а заказ включает (includes) товары таблицы Line Item, которые ссылаются (reference) на описания из таблицы Inventory. Эту диаграмму можно прочитать также в обратном направлении. Например, можно сказать, что на описания из таблицы Inventory ссылаются товары из таблицы Line Item. В любом случае, вы должны точно показать путь, по которому следует информация для достижения окончательного результата.
В приведенных примерах мы используем программу ERwin компании Logic Works. Этот инструмент позволяет определить различные объекты, а затем соответствующим образом разместить связи между этими объектами. На рис. 10 анализируется связь между таблицами Customer и Order. Как видите, эта связь не является идентифицирующей и относится типу Zero, One or More (Нуль, один или несколько).
Как видите, ключом в таблице Order, который используется для выборки информации о заказчике, является элемент CustomerlD (это внешний ключ). Он автоматически добавлен к группе неключевых элементов таблицы Order. Если же сделать элемент CustomerlD идентификатором (т.е. определить с его помощью идентифицирующую связь), то он переместится в верхнюю группу ключевых элементов таблицы Order.

Рис. 10. Инструмент ERwin позволяет легко определить связи между таблицами Customer и Order
Все остальные связи определяются аналогично. Можете тщательно изучить структуру базы данных, чтобы точно определить, как взаимодействуют между собой различные объекты. В следующих разделах вы ознакомитесь с методологией процесса разработки базы данных совместно с заказчиком.
Определение архитектуры системы
Чтобы точно определить структуру базы данных, нужно пройти несколько этапов. Прежде все-то вы должны хорошо понять, чего хочет заказчик. Как показывает практика, если бы заказчик с ! самого начала был в курсе работы над проектом, очень многих проблем удалось бы избежать.
Разумеется, ему вовсе не обязательно разбираться в терминологии, методологии и различных подходах. Основная цель сотрудничества с заказчиком состоит в том, чтобы убедиться, что структура базы данных полностью соответствует его потребностям. Здесь вы должны руководствоваться принципом: "Сначала определи, что должно быть на выходе, а за этим последует и ; то, что должно быть на входе". Согласитесь, что при тестировании любой системы нужно проверять, какие результаты она дает на выходе. Если вы создадите самую лучшую систему из всех, которые когда-либо были придуманы для ввода информации, и не сможете найти способ получения вразумительной информации на выходе, то можете считать, что зря потратили время.
Первое, что вы должны сделать, — это решить, что предоставите заказчику. Можно с уверенностью сказать, что генерация отчетов и выходных данных — это почти всегда самая нелюбимая разработчиком часть системы. Обычно первым делом заказчику предлагают следующее: "Мы дадим вам инструменты, с помощью которых вы будете сами создавать отчеты. А сейчас давайте выясним, что должна делать программа". Этот путь всегда ведет к возникновению проблем.
Если вы не знаете, что заказчику нужно иметь отчет от бухгалтерской подсистемы общей системы продаж, то будете ли вы автоматически сохранять даты выпуска счетов-фактур?
Вы можете возразить, что участие заказчика только замедлит процесс разработки, но практика показывает, что это не так. Время, потраченное на старте, с лихвой окупится на финише. Если вы четко уясните задачу с самого начала, то вам не придется ничего переделывать впоследствии.
Вы можете быть уверены, что программируете не впустую только в том случае, если способны обеспечить выдачу системой нужных выходных данных.
Перечислим правила, которыми вы должны руководствоваться при разработке базы данных:
§ Назначьте встречу с заказчиками и выясните, что они хотят получить от системы. Обсудите это как можно более подробно. Постарайтесь получить от них копии текущих форм, отчетов, образы экранов, которыми они пользуются сейчас, и т.д.
§ Создайте функциональное описание системы. Одним из компонентов описания должна стать блок-схема. Это поможет заказчикам получить представление о системе и проверить, правильно ли вы поняли, что происходит на разных этапах работы.
§ Покажите описание заказчикам. Подробно обсудите все компоненты системы, чтобы быть уверенным в ее правильности.
§ С помощью хорошего инструмента построения ERD создайте набор таблиц. Пока не обращайте внимание на внешние ключи и тому подобное. На данный момент важнее убедиться в том, что вы получили от заказчиков всю необходимую информацию.
§ Покажите таблицы базы данных заказчикам, но не заставляйте их разбираться в том, каким образом вы разместили таблицы и почему. Пусть заказчики зададут вам вопросы о том, где будут храниться те или иные данные. Ваша цель — проверить, сможете ли вы ответить на все вопросы. Но, конечно, для этого вы должны проделать большую подготовительную работу. Готовясь к встрече с заказчиками, просмотрите отчеты, другие образцы полученной от них документации и в соответствии с этим постройте структуру базы данных.
§ Затем установите связи между таблицами. Убедитесь в том, что вы проложили все логические пути информации, которые могут понадобиться заказчику. (О связях тип "многие ко многим" читайте в следующем разделе).
§ Покажите заказчикам новую схему. Попросите их сформулировать информационный запрос к системе. Можете ли вы его удовлетворить? Какие связи для этого будут использованы — идентификационные или нет? Это тест для структуры базы данных. Вы должны добиться того, чтобы структура полностью отвечала целям и задачам, поставленным заказчиками.
Системы имеют свойство очень быстро усложняться. Поэтому важность встреч с заказчиками трудно переоценить. Эти обсуждения помогут вам избежать недоразумений и необходимости переписывать целые фрагменты кода. Может оказаться, что, несмотря на полученную информацию о специфике работы заказчика, таблицы баз данных не обеспечивают нужных информационных связей. И чем раньше вы это поймете, тем меньше времени и сил будет потрачено впустую.
Как спроектировать схему базы данных
Время от времени я заглядываю на Toster.ru и иногда даже отвечаю там на вопросы. Чаще всего люди спрашивают две вещи — как стать программистом и как правильно спроектировать схему базы данных. Мне лично кажется очень странным, что так много людей задают последний вопрос. Мне почему-то всегда казалось, что это такая простая вещь, которую умеют вообще все. Но, раз так много людей интересуются, здесь я постараюсь дать достаточно развернутый и в то же время краткий ответ.
Я предполагаю, что SQL вы знаете. То есть, объяснять, что такое таблицы, строки, индексы, первичные ключи и ссылочная целостность, не требуется. Если это не так, боюсь, я вынужден отправить вас к соответствующей литературе. Благо, ее сейчас очень много.
Рисуем диаграмму
Допустим, требуется спроектировать схему базы данных, в которой хранится информация о музыкальных исполнителях, альбомах и песнях. На начальном этапе, когда у нас еще совсем ничего нет, удобно начать с рисования диаграммы будущей схемы. Можно начать с наброска ручкой на листе бумаги, можно сразу взять специализированный редактор. Их сейчас очень много, все они устроены довольно похожим образом. При подготовке этой заметки я воспользовался DbSchema. Это платная программа, но мне кажется, что она стоит своих денег. К тому же, в нормальных компаниях обычно оплачивают стоимость софта, необходимого для работы. Триал у DbSchema, если что, составляет две недели.
Нарисовать следюущую диаграмму заняло у меня порядко десяти минут:
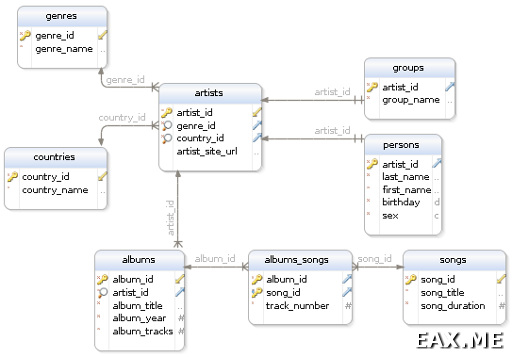
Если раньше вам не доводилось работать с такими диаграммами, не пугайтесь, тут все просто. Прямоугольнички — это таблицы, строки в прямоугольничках — имена столбцов, стрелочками обозначаются внешние ключи, а ключиками — первичные ключи. При желании тут можно разглядеть даже индексы, типы столбцов и обязательность их заполнения (null / not null), но для нас сейчас это не так важно.
Дополнение: Аналогичную диаграмму можно построить при помощи открытого инструмента PlantUML.
Генерируем SQL и скармливаем его СУБД
Нетрудно заметить, что данная диаграмма легко отображается в код для создания схемы базы данных на языке SQL. В DbSchema сгенерировать SQL можно, сказав Schema → Generate Schema and Data Script. Затем полученный скрипт можно скормить используемой вами СУБД:
Я использовал PostgreSQL. Информацию о том, как установить эту СУБД, вы найдете в этой заметке.
Итак, чем же я руководствовался при проектировании схемы?
Нормальные формы
Процесс устранения избыточности и ликвидации противоречивости базы данных называется нормализацией. Выделяют так называемые нормальные формы, из которых на практике редко кто помнит больше первых трех.
Грубо говоря, таблица находится в первой нормальной форме (1НФ), если на пересечении любой строки и любого столбца в таблице находится ровно одно значение. В современных РСУБД это условие всегда выполняется. Даже если СУБД поддерживает множества или массивы, на пересечении строки и столбца хранится ровно одно значение типа множество или массив. Но в таблице (user varchar(100), phone integer) не может быть строки alex – 1234, 5678 . В 1НФ может быть только две сроки — alex – 1234 и alex – 5678 .
Вторая нормальная форма (2НФ) означает, что таблица находится в первой нормальной форме, и каждый неключевой атрибут неприводимо зависит от значения первичного ключа. Неприводимость означает следующее. Если первичный ключ состоит из одного атрибута, то любая функциональная зависимость от него неприводима. Если первичный ключ является составным, то в таблице не может быть атрибута, значение которого однозначно определяется значением подмножества атрибутов первичного ключа.
Таблица находится в третьей нормальной форме, если она находится в 2НФ и ни один неключевой атрибут не находится в транзитивной функциональной зависимости от первичного ключа. Например, рассмотрим таблицу (employee varchar(100) primary key, department varchar(100), department_phone integer) . Очевидно, что она находится в 2НФ. Но телефон отдела находится в транзитивной функциональной зависимости от имени сотрудника, так как сотрудник однозначно задает отдел, а отдел однозначно задает телефон отдела. Для приведения таблицы в 3НФ нужно разбить ее на две таблицы — employee – department и departmnet – phone .
Легко видеть, что нормализация уменьшает избыточность базы данных и препятствует внесению случайных ошибок. Например, если оставить таблицу из последнего примера в 2НФ, то можно по ошибке прописать одному и тому же отделу разные телефоны. Или рассмотрим компанию с пятью отделами и 1000 сотрудниками. Если у отдела поменялся номер телефона, то для его обновления в базе данных в случае 2НФ потребуется просканировать 1000 строк, а в случае с 3НФ только пять.
Как я уже отмечал, есть и более строгие нормальные формы, но на практике обычно используются только первые три.
Отношение один ко многим
На приведенной диаграмме можно заметить, что каждый исполнитель относится к какой-то стране, и каждый альбом принадлежит какому-то исполнителю. Это и есть отношение один ко многим. Например, к одной стране относится множество исполнителей, и каждый исполнитель может иметь множество альбомов. Но приведенная схема, например, запрещает одному альбому принадлежать множеству исполнителей. Хотя в реальной жизни, конечно, это возможно, например, в случае со сборниками.
Для моделирования такого типа отношения в каждом альбоме указывается id исполнителя, и в каждом исполнителе указывается id страны. Понятное дело, мы не просто пишем туда какую-то циферку, а возлагаем ответственность по контролю ссылочной целостности на нашу СУБД:
Это часто оказывается большим сюрпризом для тех, кто всю жизнь работал с MySQL и его бэкендом MyISAM, который так не умеет. Я не вижу причин не проверять ссылочную целостность, если только вы не пишите супер-пупер высоконагруженный проект, у которого исполнители хранятся на одном сервере, а альбомы — на другом. В противном случае вас ждет много часов увлекательной отладки вашего приложения в ночь с субботы на воскресенье, потому что как-то так получилось, что кто-то создал альбом с несуществующим исполнителем.
Жанры и страны в приведенной схеме иногда еще называют «словарями». Это сравнительно небольшие таблицы, состоящие из двух столбцов — id и названия. Если, например, мы захотим переименовать страну Russia в Russian Federation, нам придется поменять всего лишь одну строчку в таблице countries, а не править кучу строк в таблице artists, что может привести к очень большому количеству дисковых операций. Кроме того, если требуется отобразить в диалоге создания нового исполнителя выпадающий список с выбором страны, нам не придется делать дорогих группировок по таблице artists, достаточно сделать простую выборку из countries.
Отношение многие ко многим
Один альбом, как правило, содержит множество песен. Кроме того, нет веских причин, почему одна песня не может находится сразу в нескольких альбомах. Здесь мы имеем место с типичным отношением многие ко многим.
Оно моделируется путем введения дополнительной таблицы. В нашем примере эта таблица называется albums_songs. Первичный ключ в этой таблицы состоит из двух внешних ключей — album_id и song_id. Теперь нетрудно с помощью пары join’ов получить все песни, входящие в данный альбом или все альбомы, в которые входит заданная песня. Кроме того, ничто не мешает завести в связующей таблице дополнительные столбцы. Например, столбец, хранящий номер трека, под которым песня входит в заданный альбом.
На практике связаны могут быть не две, а три и более таблиц. Например, некий пользователь сделал некий заказ, выбрав указанный способ оплаты, адрес и способ доставки — пожалуйста, пять таблиц как с куста.
Отношение родитель-потомок (или общее-частное)
Исполнители могут быть разных типов. Это может быть отдельно взятый(ая) певец/певица, или же группа. У всех исполнителей, независимо от конкретного типа, есть что-то общее. Например, страна, адрес официального сайта и так далее. Но кроме того, есть некоторые свойства, характерные только для данного типа. У певицы явно нет никакого названия группы, а у группы нет имени, фамилии и пола. Аналогичная ситуация возникает, скажем, если у вас есть сотрудники, занимающие различные должности и свойства сотрудников зависят от занимаемых должностей.
Один из способов моделирования такой ситуации заключается в введении по отдельной таблице на каждый из возможных подтипов. В приведенном примере это таблицы groups и persons. В качестве первичного ключа в каждой из этих таблиц используется artist_id, первичный ключ родительской таблицы artists. Кто-то при использовании такой схемы предпочитает добавить в родительскую таблицу столбец type, но, строго говоря, он является избыточным. Недостаток этого метода заключается в том, что можно создать исполнителя, являющегося как группой, так и человеком одновременно.
Есть и другие подходы. В PostgreSQL, например, есть наследование таблиц, предназначенное для решения как раз такой вот проблемы. Если вы работаете с PostgreSQL, нет причин не использовать этот механизм. Кто-то предпочитает ввести одну таблицу для всех типов с дополнительным столбцом type. Если некий столбец не имеет смысла для заданного типа, в него пишется null. Но это, как вы можете подозревать, не очень-то удобно, если у вас 10 типов, каждый из которых имеет по дюжине столбцов, характерных только для этого типа, а также парочку собственных подтипов. Кроме того, можно опрометчиво реализовать смену типа, как простое обновление столбца type, и получить массу интереснейших эффектов.
Что еще нужно принять во внимание
Принцип при моделировании других отношений тот же. Например, один человек имеет двух родителей и при этом один человек может иметь сколько угодно детей. Казалось бы, связь 2:N, этого мы не проходили. На самом деле, это просто две связи 1:N. Вводим столбцы mother_id, father_id и вперед. Да, связь в рамках одной таблицы, ну и что?
Иногда на практике можно столкнутся с древовидными структурами. На самом деле, это то же самое отношение один ко многим, один родитель имеет много потомков. В общем, вводится столбец parent_id, куда пишется «внешний» первичный ключ из этой же таблицы. В корневом элементе устанавливается parent_id равный null. Главное при работе с этим хозяйством — не наплодить случайно циклов.
В общем, все, что нужно, это немного здравого смысла.
Также при проектировании схемы базы данных нужно уделять внимание индексам. Тут все сильно зависит от конкретной СУБД, поддерживает ли она составные индексы, частичные индексы, функциональные индексы, bitmap scans и так далее. Кое-что по этой теме я писал здесь, а вообще — курите мануалы по вашей СУБД. Также за кадром остались вьюхи, тригеры и многое другое.
В высоконагруженных проектах в целях оптимизации иногда прибегают к денормализации, то есть, процессу, обратному нормализации. Действительно, в некоторых случаях намного эффективнее держать все в одной таблице, чем делать несколько десятков джоинов. Иногда данные распределяют между несколькими серверами. Понятно, что в этом случае ссылочная целостность никем не проверяется и может быть случайно нарушена. Сплошь и рядом базы данных содержат в себе некоторую избыточность. Например, стоимость заказа можно однозначно определить, сложив стоимость товаров в корзине. Но иногда эффективнее хранить уже посчитанную стоимость, особенно если речь идет не об одной корзине, а о месячном отчете по всей системе. Иногда избыточность добавляется, чтобы данные можно было починить в случае программных ошибок. Например, все критичные операции сопровождаются записью в таблицу-лог.
Ну и нельзя не отметить, что приведенный здесь пример с исполнителями и альбомами довольно игрушечный. В реальных условиях база данных может запросто содержать сотню таблиц, каждая из которых имеет многие десятки столбцов и миллионы строк. Или, например, одну таблицу, имеющую пару сотен столбцов. Примите также во внимание, что схема базы данных имеет свойство довольно часто меняться, что, разумеется, приводит к необходимости мигрировать данные, и вы получите более-менее правдоподобную картину того, с чем на самом деле вам предстоит столкнутся.
Заключение
Все приходит с опытом. Самостоятельно спроектируйте две-три схемы, и картинка сама сложится у вас в голове. В качестве ДЗ можете спроектировать базу данных блога, интернет-магазина или базу с сотрудниками компании, их должностями и контактами. Отталкивайтесь от задачи. Учитывайте, кто и какие действия будет совершать с базой данных. Например, с базой интернет-магазина работают не только клиенты, но и, например, отдел доставки.
Проект для DbSchema, а также сгенерированный из него SQL, вы можете скачать здесь. Как всегда, если у вас есть вопросы или дополнения, не стесняйтесь писать их в комментариях.