Содержание
- 1 Что такое бинарный поиск
- 2 Принцип работы бинарного поиска
- 3 Как создать бинарный поиск в C++
- 4 Описание:
- 5 Алгоритм:
- 6 Бинарный поиск в упорядоченных массивах:
- 7 Бинарный поиск для монотонных функции:
- 8 Бинарный поиск по ответу:
- 9 Содержание
- 10 Принцип работы [ править ]
- 11 Правосторонний/левосторонний целочисленный двоичный поиск [ править ]
- 12 Алгоритм двоичного поиска [ править ]
- 13 Код [ править ]
- 14 Несколько слов об эвристиках [ править ]
- 15 Применение двоичного поиска на некоторых неотсортированных массивах [ править ]
- 16 Переполнение индекса середины [ править ]
Сегодня мы и изучим его. Также попытаемся ответить на такие вопросы: как бинарный поиск работает в программе, плюсы и минусы его использования у себя в коде и в каких структурах данных можно его применять, а в каких нет. Поехали!
Что такое бинарный поиск
Линейный поиск по сравнению с бинарным — дешевая подделка. Бинарный поиск — очень быстрый алгоритм с не сложной реализацией, который находит элемент с определенным значением в уже отсортированном массиве.
Очень важно помнить! Алгоритм будет работать правильно, только с отсортированным массивом. А если по случайности вы забыли отсортировать массив перед его использованием, то в большинстве случаев тот ответ, который подсчитал алгоритм, будет неверным.
Принцип работы бинарного поиска
Давайте рассмотрим задачку, чтобы понять как работает алгоритм.
Охранной службе морского флота поступило сообщение о том, что некто пытается пронести на корабль бомбу. Диверсант пока находится у причала. Допустим, что в нашем распоряжении имеется прибор, который может определить, есть ли бомба в комнате. Необходимо как можно быстрее определить, у кого находится бомба.
Самым легким и самым долгим по времени решением, будет поочередная проверка пассажиров в комнате с прибором (это линейный поиск). Но это слишком долго.
Давайте сделаем по-другому. Поделим пополам всех пассажиров и разведем их по двум комнатам. Так с помощью прибора мы сможем узнать, в какой из двух комнат находится бомба. В итоге такого маневра мы уменьшим число подозреваемых в два раза. С остальным числом подозреваемых сделаем также: разделим их на две группы и разместим в разных комнатах. Так продолжаем, пока не узнаем кто диверсант.
В задаче выше охранники использовали алгоритм двоичного поиска для нахождения диверсанта. В обычной программе принцип работы бинарного поиска такой же, как и в примере, выше.
Как создать бинарный поиск в C++
Давайте посмотрим как работает бинарный поиск на примере.В примере ниже в строке 9 мы создали массив arr на 10 элементов и в строке 12 предложили пользователю с клавиатуры заполнить его ячейки.
В строке 20 мы предлагаем пользователю ввести ключ (который нужно будет найти в массиве), а дальше мы с бинарным поиском проверим массив на наличие введенного ключа пользователем. Если мы найдем ключ в массиве, то выведем индекс ячейки, в которой находится ключ.
Инструменты пользователя
Инструменты сайта
Содержание
Данный алгоритм является основным алгоритмом поиска.
Описание:
Давайте рассмотрим данный алгоритм на примере задачи: ваш друг загадывает число из заданного заранее интервала [left, right], а вам требуется написать программу, которая будет отгадывать его (то есть ваш друг будет отвечать: «меньше», «больше» или «равно» на каждое предположение вашей программы). Заметим, что если заданный интервал достаточно большой, то обычный перебор всех возможных чисел будет работать очень долго (например если число может быть до 10 18 ).
Алгоритм:
Давай те каждый раз брать середину интервала mid и если загаданное число меньше, то переходить к интервалу [l,mid], а иначе к [mid + 1, r]. Действительно, если элемент меньше mid, то и меньше всех элементов, которые находятся правее (то есть элементов больших чем mid). Так будем переходить от одного интервала к другому, пока left не совпадет с right, потому что в этот момент мы с уверенностью сможем сказать, что угадали число.
Бинарный поиск в упорядоченных массивах:
Действовать будем абсолютно аналогично, только теперь left, right и mid – это индексы заданного массива.
Пусть нам нужно найти номер элемента равного key или вывести -1, если его нет в массиве:
Бинарный поиск для монотонных функции:
Так же как и для массива мы можем исключать половину интервала возможных значении на каждом шаге. Если функция не монотонна, то скорее всего найдутся не все ответы.
Приведем пример для решения задачи о нахождении корня из N (>= 1) с точностью до 6 знаков:
Бинарный поиск по ответу:
Пусть нам дана какая то задача, где нужно максимизировать (минимизировать) ответ, но операция получения ответа достаточно трудоемка и мы не можем просто перебрать все возможные варианты.
Воспользуемся бинарным поиском, за left примем минимально возможный ответ по условиям задачи, а за right – максимально возможный. Теперь будем пробовать получить ответ равный m >
Задачи, в которых можно использовать данный алгоритм:
Целочисленный двоичный поиск (бинарный поиск) (англ. binary search) — алгоритм поиска объекта по заданному признаку в множестве объектов, упорядоченных по тому же самому признаку, работающий за логарифмическое время.
| Задача: |
| Пусть нам дан упорядоченный массив, состоящий только из целочисленных элементов. Требуется найти позицию, на которой находится заданный элемент. |
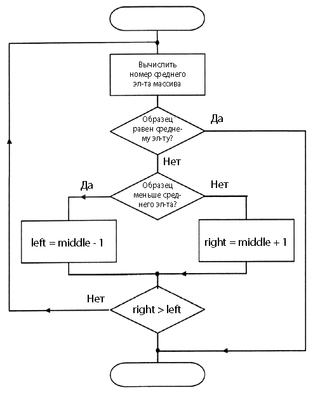
Содержание
Принцип работы [ править ]
Двоичный поиск заключается в том, что на каждом шаге множество объектов делится на две части и в работе остаётся та часть множества, где находится искомый объект. Или же, в зависимости от постановки задачи, мы можем остановить процесс, когда мы получим первый или же последний индекс вхождения элемента. Последнее условие — это левосторонний/правосторонний двоичный поиск.
Правосторонний/левосторонний целочисленный двоичный поиск [ править ]
Для простоты дальнейших определений будем считать, что [math]a[-1] = -infty[/math] и что [math]a[n] = +infty[/math] (массив нумеруется с [math]0[/math] ).
| Определение: |
| Правосторонний бинарный поиск (англ. rights >[math] maxlimits_ [/math] , где [math]a[/math] — массив, а [math]x[/math] — искомый ключ |
| Определение: |
| Левосторонний бинарный поиск (англ. lefts >[math] minlimits_ [/math] , где [math]a[/math] — массив, а [math]x[/math] — искомый ключ |
Использовав эти два вида двоичного поиска, мы можем найти отрезок позиций [math][l,r][/math] таких, что [math]forall i in [l,r] : a[i] = x[/math] и [math] forall i
otin [l,r] : a[i]
eq x [/math]
Пример: [ править ]
Задан отсортированный массив [math][1, 2, 2, 2, 2, 3, 5, 8, 9, 11], x = 2[/math] .
Правосторонний поиск двойки выдаст в результате [math]4[/math] , в то время как левосторонний выдаст [math]1[/math] (нумерация с нуля).
Отсюда следует, что количество подряд идущих двоек равно длине отрезка [math][1;4][/math] , то есть [math]4[/math] .
Если искомого элемента в массиве нет, то правосторонний поиск выдаст минимальный элемент, больший искомого, а левосторонний наоборот, максимальный элемент, меньший искомого.
Алгоритм двоичного поиска [ править ]
Идея поиска заключается в том, чтобы брать элемент посередине, между границами, и сравнивать его с искомым. Если искомое больше(в случае правостороннего — не меньше), чем элемент сравнения, то сужаем область поиска так, чтобы новая левая граница была равна индексу середины предыдущей области. В противном случае присваиваем это значение правой границе. Проделываем эту процедуру до тех пор, пока правая граница больше левой более чем на [math]1[/math] .
Код [ править ]
В случае правостороннего поиска изменится знак сравнения при сужении границ на [math]a[m] leqslant k[/math] .
Инвариант цикла: пусть левый индекс не больше искомого элемента, а правый — строго больше, тогда если [math]l = r – 1[/math] , то понятно, что [math]l[/math] — самое правое вхождение (так как следующее уже больше).
Несколько слов об эвристиках [ править ]
Эвристика с завершением поиска, при досрочном нахождении искомого элемента
Заметим, что если нам необходимо просто проверить наличие элемента в упорядоченном множестве, то можно использовать любой из правостороннего и левостороннего поиска. При этом будем на каждой итерации проверять "не попали ли мы в элемент, равный искомому", и в случае попадания заканчивать поиск.
Эвристика с запоминанием ответа на предыдущий запрос
Пусть дан отсортированный массив чисел, упорядоченных по неубыванию. Также пусть запросы приходят в таком порядке, что каждый следующий не меньше, чем предыдущий. Для ответа на запрос будем использовать левосторонний двоичный поиск. При этом после того как обработался первый запрос, запомним чему равно [math]l[/math] , запишем его в переменную [math]startL[/math] . Когда будем обрабатывать следующий запрос, то проинициализируем левую границу как [math]startL[/math] . Заметим, что все элементы, которые лежат не правее [math]startL[/math] , строго меньше текущего искомого элемента, так как они меньше предыдущего запроса, а значит и меньше текущего. Значит инвариант цикла выполнен.
Применение двоичного поиска на некоторых неотсортированных массивах [ править ]
| Задача: |
| Пусть отсортированный по возрастанию массив из [math]n[/math] элементов [math]a[0 ldots n – 1][/math] , все элементы которого различны, был циклически сдвинут, требуется максимально быстро найти элемент в таком массиве. |
Если массив, отсортированный по возрастанию, был циклически сдвинут, тогда полученный массив состоит из двух отсортированных частей. Используем двоичный поиск, чтобы найти индекс последнего элемента левой части массива. Для этого в реализации двоичного поиска заменим условие в if на [math]a[m] gt a[n-1][/math] , тогда в [math]l[/math] будет содержаться искомый индекс:
Затем воспользуемся двоичным поиском искомого элемента [math]key[/math] , запустив его на той части массива, в которой он находится: на [math][0, x][/math] или на [math][x + 1, n – 1][/math] . Для определения нужной части массива сравним [math]key[/math] с первым и с последним элементами массива:
Время выполнения данного алгоритма — [math]O(2log n)=O(log n)[/math] .
| Задача: |
| Массив образован путем приписывания в конец массива, отсортированного по возрастанию, массива, отсортированного по убыванию. Требуется максимально быстро найти элемент в таком массиве. |
Найдем индекс последнего элемента массива, отсортированного по возрастанию, воспользовавшись троичным поиском, затем запустим левосторонний двоичный поиск для каждого массива отдельно: для элементов [math][0 ldots x][/math] и для элементов [math][x+1 ldots n][/math] , где в качестве [math]x[/math] мы возьмем индекс максимума, найденный троичным поиском. Для массива, отсортированного по убыванию используем двоичный поиск, изменив условие в if на [math]a[m] gt key[/math] .
Время выполнения алгоритма — [math] O(log n)[/math] (так как и бинарный поиск, и тернарный поиск работают за логарифмическое время с точностью до константы).
| Задача: |
| Два отсортированных по возрастанию массива записаны один в конец другого. Требуется максимально быстро найти элемент в таком массиве. |
Мы имеем массив, образованный из двух отсортированных подмассивов, записанных один в конец другого. Запустить сразу бинарный или тернарный поиски на таком массиве нельзя, так как массив не будет обязательно отсортированным и он не будет иметь [math]1[/math] точку экстремума. Поэтому попробуем найти индекс последнего элемента левого массива, чтобы потом запустить бинарный поиск два раза на отсортированных массивах.
Докажем, что найти этот индекс невозможно быстрее, чем за [math]Omega (n)[/math] . Возьмем возрастающий массив целых чисел, начиная с [math]1[/math] . Он удовлетворяет условию задачи. Вставим в него [math]0[/math] на любую позицию. Такой массив по-прежнему будет удовлетворять условию задачи. Следовательно, из-за того, что [math]0[/math] может находиться на любой позиции, мы можем его найти лишь за [math]Omega (n)[/math] .
| Задача: |
| Массив образован путем циклического сдвига массива, образованного приписыванием отсортированного по убыванию массива в конец отсортированного по возрастанию. Требуется максимально быстро найти элемент в таком массиве. |
После циклического сдвига мы получим массив [math]a[0 ldots n-1][/math] , образованный из трех частей: отсортированных по возрастанию-убыванию-возрастанию ( [math]
earrow searrow
earrow [/math] ) или по убыванию-возрастанию-убыванию ( [math] searrow
earrow searrow [/math] ). С помощью двоичного поиска найдем индексы максимального и минимального элементов массива, заменив условие в if на [math]a[m] gt a[m – 1][/math] (ответ будет записан в [math]l[/math] ) или на [math]a[m] gt a[m + 1][/math] (ответ будет записан в [math]r[/math] ) соответственно.
Фактически, при поиске индексов минимума и максимума мы проверяем, возрастает или убывает массив на промежутке [math] [ m – 1 ; m ] [/math] , а затем, в зависимости от того, что мы ищем, мы либо поднимаемся, либо опускаемся по этому промежутку возрастания (убывания). Однако при таком решении могут быть неправильно найдены значения минимума или максимума. Рассмотрим случаи, когда они будут неправильно найдены. Определить, какого вида наш массив возможно, сравнив первые два элемента массива.
Рассмотрим отдельно ситуацию, если наш массив вида возрастание-убывание-возрастание ( [math]
earrow searrow
earrow [/math] ). В таком случае может быть неправильно найдено значение максимума, если последний промежуток возрастания занимает больше половины массива (мы будем подниматься по последнему промежутку возрастания вплоть до конца массива и за максимум будет принят последний элемент массива, что не всегда верно). Тогда, если последний элемент массива меньше первого, нужно еще раз запустить поиск максимума, но уже на промежутке от [math]0[/math] до [math]min[/math] , потому что истинный максимум будет находиться в первой точке экстремума, которую мы таким образом и найдем.
В случае же убывание-возрастание-убывание ( [math] searrow
earrow searrow [/math] ) может быть, что будет неправильно найден минимум. Найдем правильный минимум аналогично поиску максимума в предыдущем абзаце.
Затем, в зависимости от типа нашего массива, запустим бинарный поиск три раза на каждом промежутке.
Время выполнения данного алгоритма — [math]O(6log n)=O(log n)[/math] .
Переполнение индекса середины [ править ]
В некоторых языках программирования присвоение m = (l + r) / 2 приводит к переполнению. Вместо этого рекомендуется использовать m = l + (r – l) / 2; или эквивалентные выражения. [1]