Содержание

Среди различных методов прогнозирования нельзя не выделить аппроксимацию. С её помощью можно производить приблизительные подсчеты и вычислять планируемые показатели, путем замены исходных объектов на более простые. В Экселе тоже существует возможность использования данного метода для прогнозирования и анализа. Давайте рассмотрим, как этот метод можно применить в указанной программе встроенными инструментами.
Выполнение аппроксимации
Наименование данного метода происходит от латинского слова proxima – «ближайшая» Именно приближение путем упрощения и сглаживания известных показателей, выстраивание их в тенденцию и является его основой. Но данный метод можно использовать не только для прогнозирования, но и для исследования уже имеющихся результатов. Ведь аппроксимация является, по сути, упрощением исходных данных, а упрощенный вариант исследовать легче.
Главный инструмент, с помощью которого проводится сглаживания в Excel – это построение линии тренда. Суть состоит в том, что на основе уже имеющихся показателей достраивается график функции на будущие периоды. Основное предназначение линии тренда, как не трудно догадаться, это составление прогнозов или выявление общей тенденции.
Но она может быть построена с применением одного из пяти видов аппроксимации:
- Линейной;
- Экспоненциальной;
- Логарифмической;
- Полиномиальной;
- Степенной.
Рассмотрим каждый из вариантов более подробно в отдельности.
Способ 1: линейное сглаживание
Прежде всего, давайте рассмотрим самый простой вариант аппроксимации, а именно с помощью линейной функции. На нем мы остановимся подробнее всего, так как изложим общие моменты характерные и для других способов, а именно построение графика и некоторые другие нюансы, на которых при рассмотрении последующих вариантов уже останавливаться не будем.
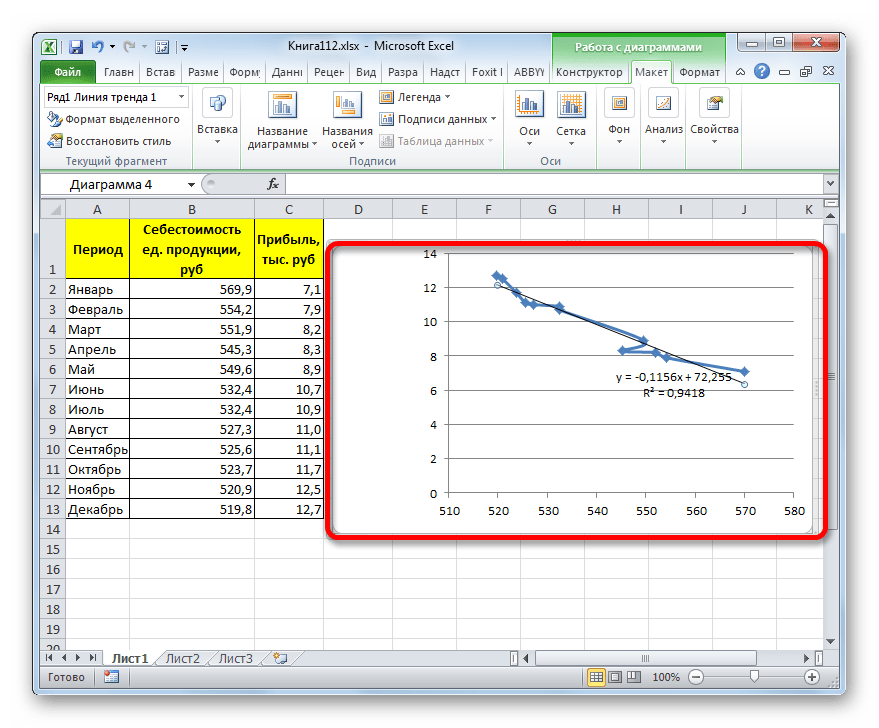
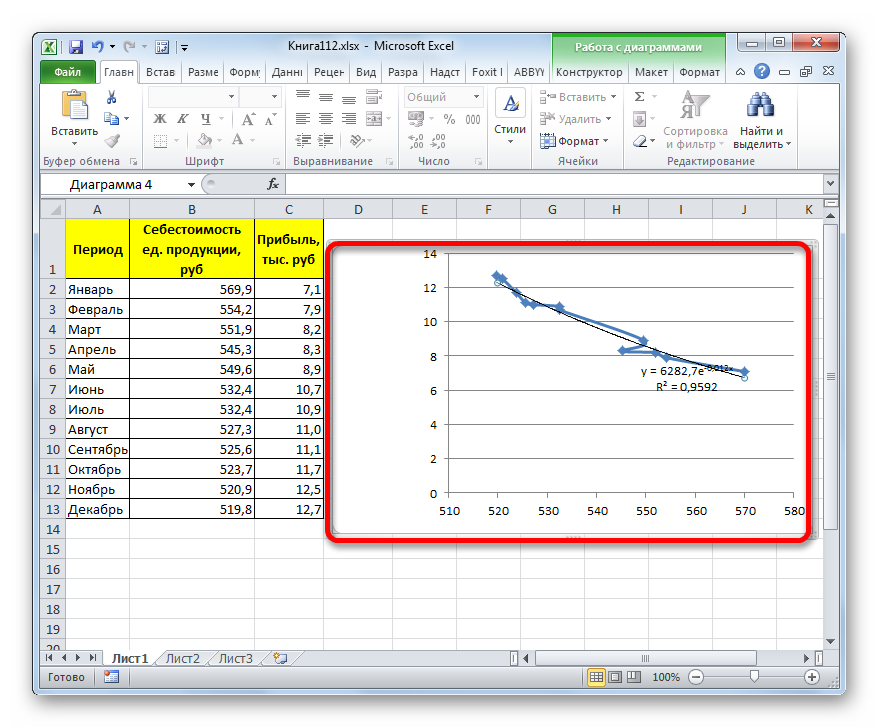
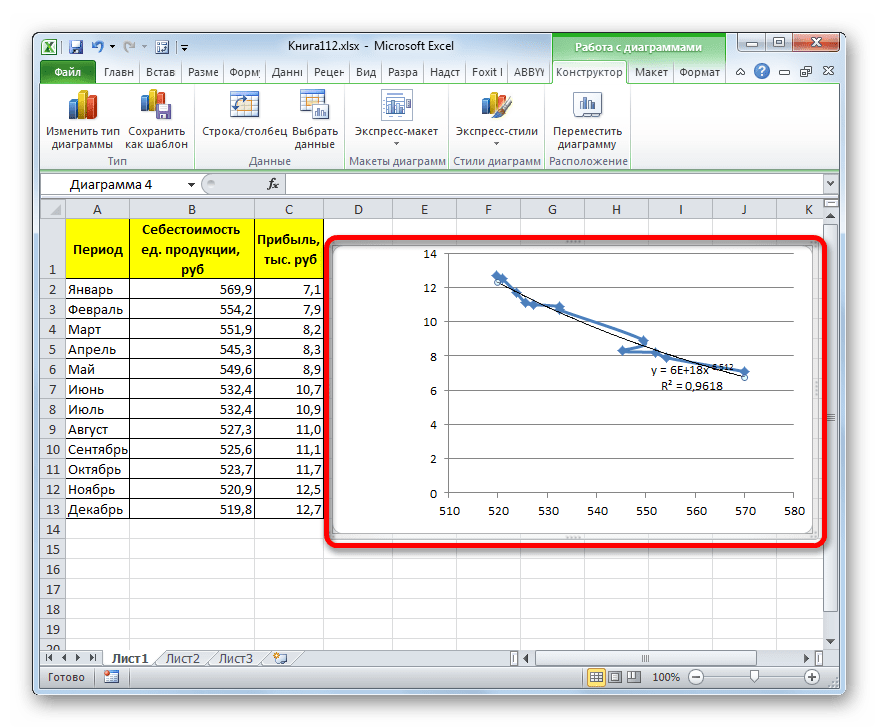
Прежде всего, построим график, на основании которого будем проводить процедуру сглаживания. Для построения графика возьмем таблицу, в которой помесячно указана себестоимость единицы продукции, производимой предприятием, и соответствующая прибыль в данном периоде. Графическая функция, которую мы построим, будет отображать зависимость увеличения прибыли от уменьшения себестоимости продукции.
-
Для построения графика, прежде всего, выделяем столбцы «Себестоимость единицы продукции» и «Прибыль». После этого перемещаемся во вкладку «Вставка». Далее на ленте в блоке инструментов «Диаграммы» щелкаем по кнопке «Точечная». В открывшемся списке выбираем наименование «Точечная с гладкими кривыми и маркерами». Именно данный вид диаграмм наиболее подходит для работы с линией тренда, а значит, и для применения метода аппроксимации в Excel.
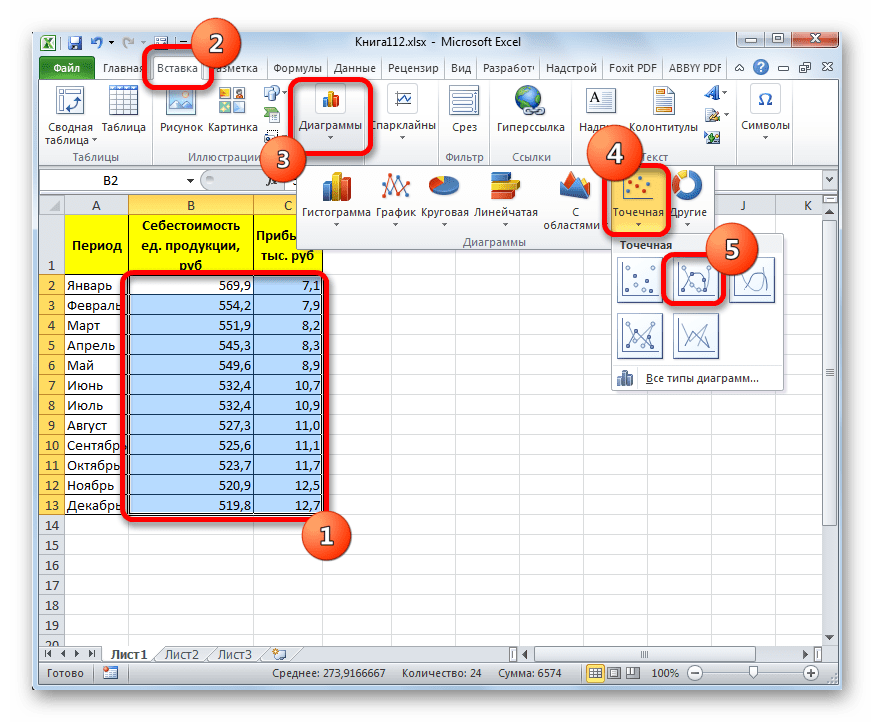
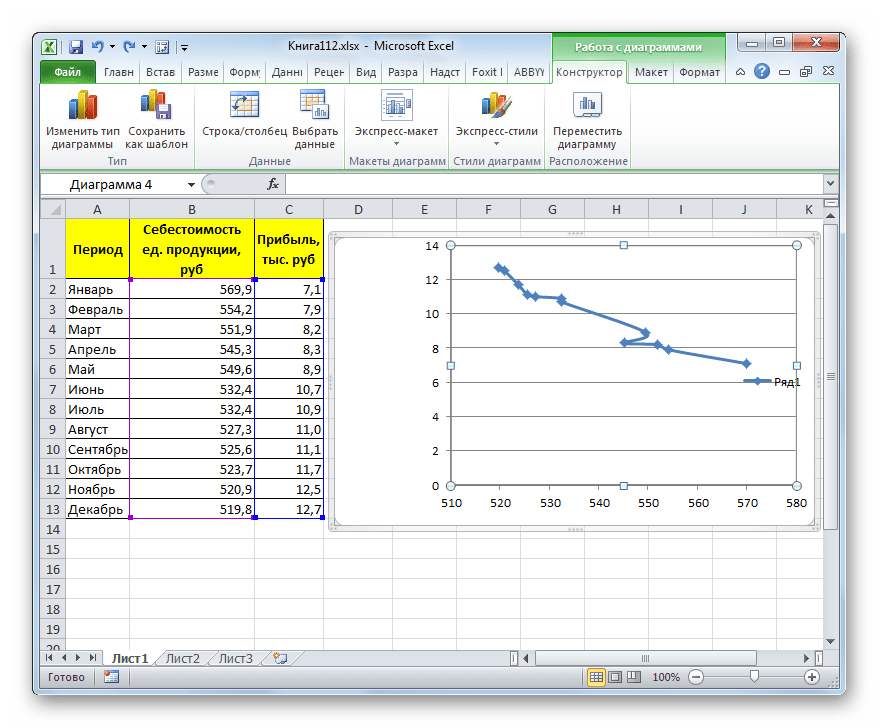
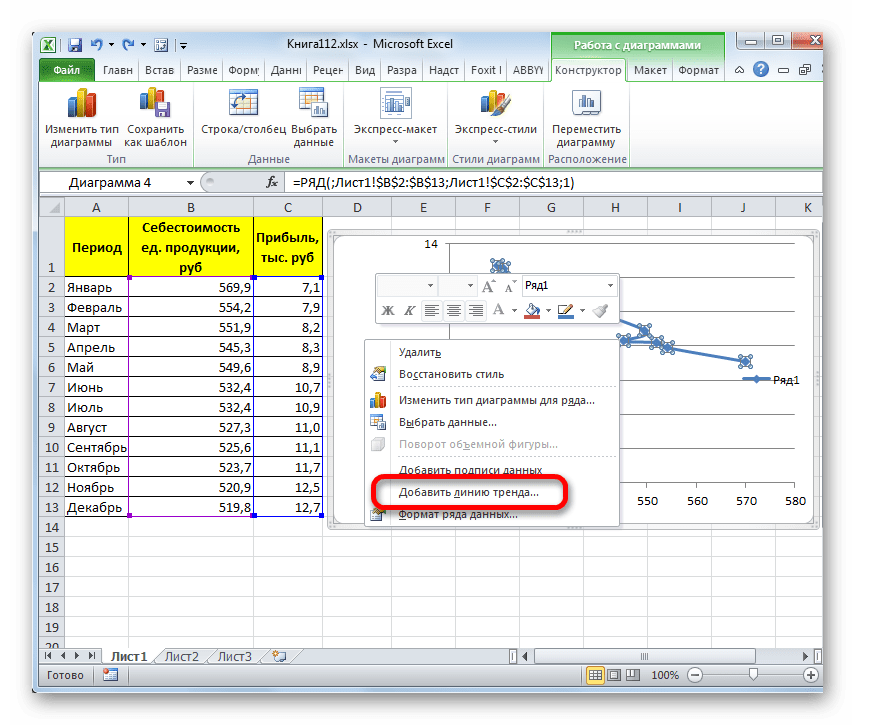
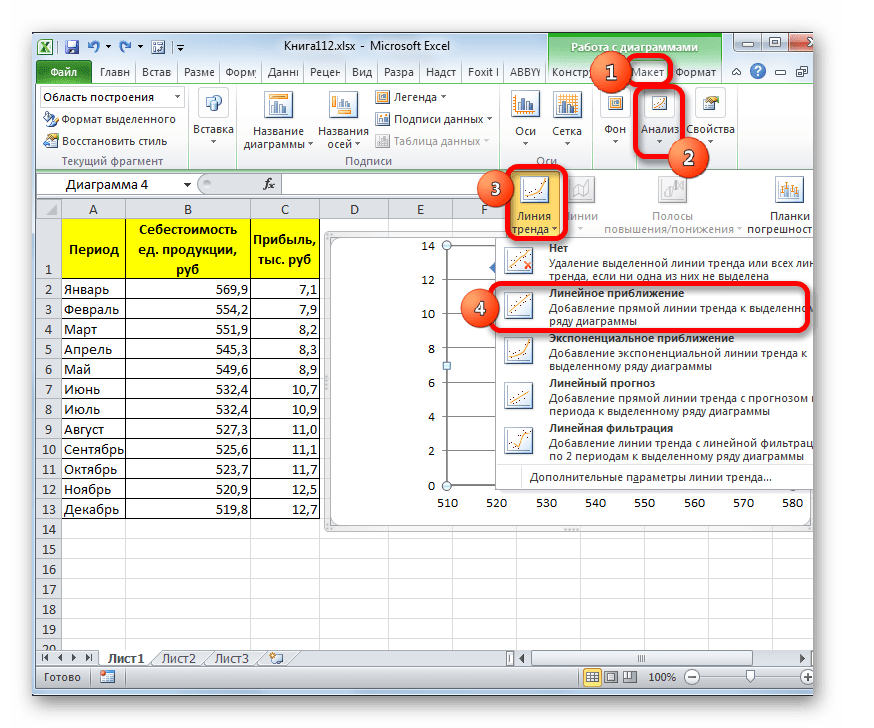
Существует ещё один вариант её добавления. В дополнительной группе вкладок на ленте «Работа с диаграммами» перемещаемся во вкладку «Макет». Далее в блоке инструментов «Анализ» щелкаем по кнопке «Линия тренда». Открывается список. Так как нам нужно применить линейную аппроксимацию, то из представленных позиций выбираем «Линейное приближение».
Если же вы выбрали все-таки первый вариант действий с добавлением через контекстное меню, то откроется окно формата.
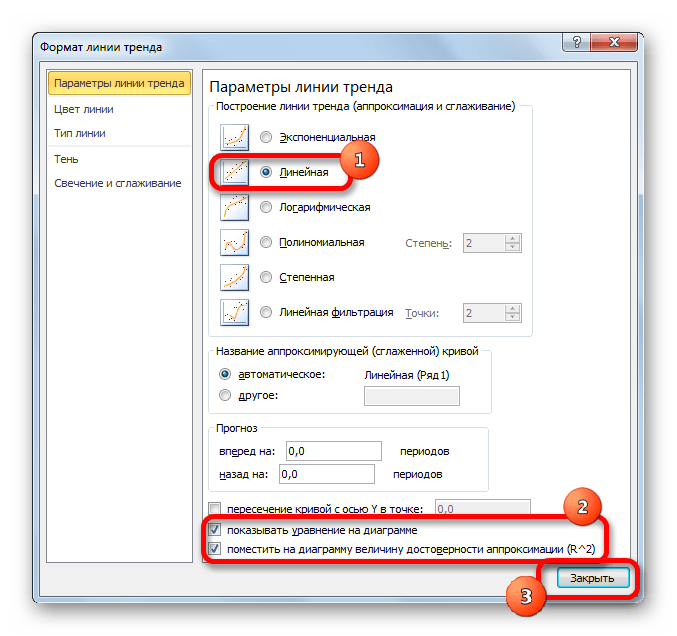
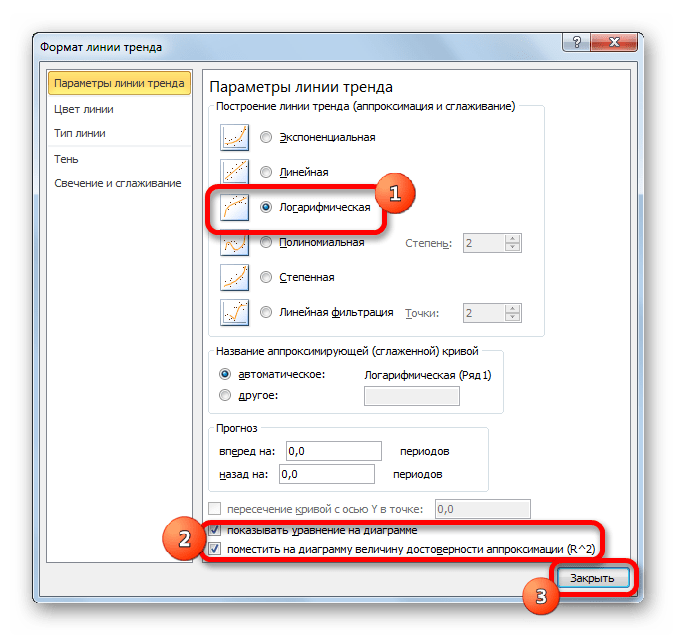
В блоке параметров «Построение линии тренда (аппроксимация и сглаживание)» устанавливаем переключатель в позицию «Линейная».
При желании можно установить галочку около позиции «Показывать уравнение на диаграмме». После этого на диаграмме будет отображаться уравнение сглаживающей функции.
Также в нашем случае для сравнения различных вариантов аппроксимации важно установить галочку около пункта «Поместить на диаграмму величину достоверной аппроксимации (R^2)». Данный показатель может варьироваться от до 1. Чем он выше, тем аппроксимация качественнее (достовернее). Считается, что при величине данного показателя 0,85 и выше сглаживание можно считать достоверным, а если показатель ниже, то – нет.
После того, как провели все вышеуказанные настройки. Жмем на кнопку «Закрыть», размещенную в нижней части окна.
Сглаживание, которое используется в данном случае, описывается следующей формулой:
В конкретно нашем случае формула принимает такой вид:
Величина достоверности аппроксимации у нас равна 0,9418, что является довольно приемлемым итогом, характеризующим сглаживание, как достоверное.
Способ 2: экспоненциальная аппроксимация
Теперь давайте рассмотрим экспоненциальный тип аппроксимации в Эксель.
-
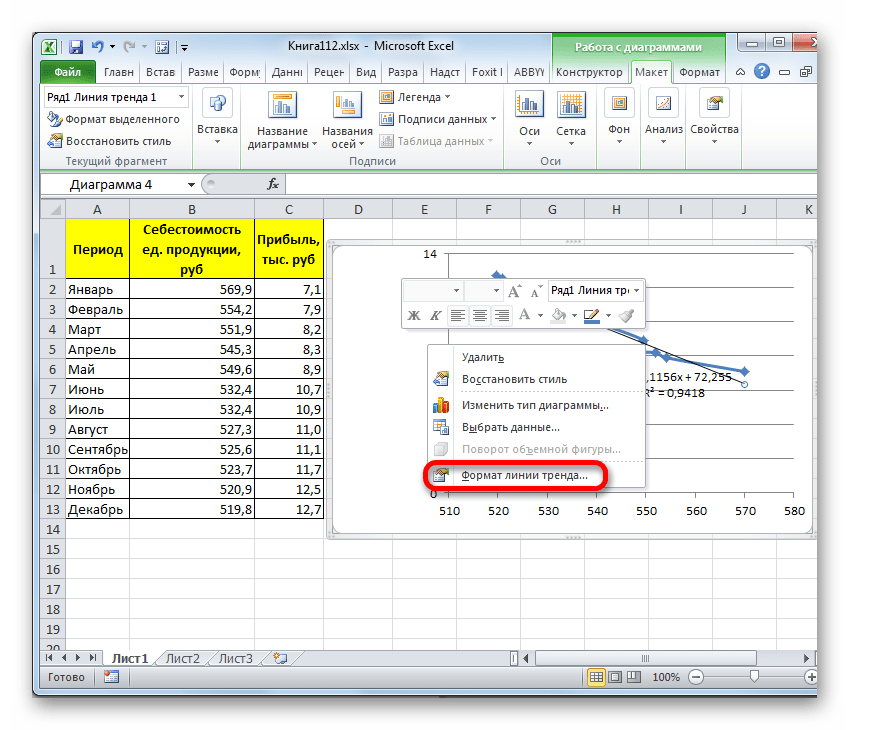
Для того, чтобы изменить тип линии тренда, выделяем её кликом правой кнопки мыши и в раскрывшемся меню выбираем пункт «Формат линии тренда…».
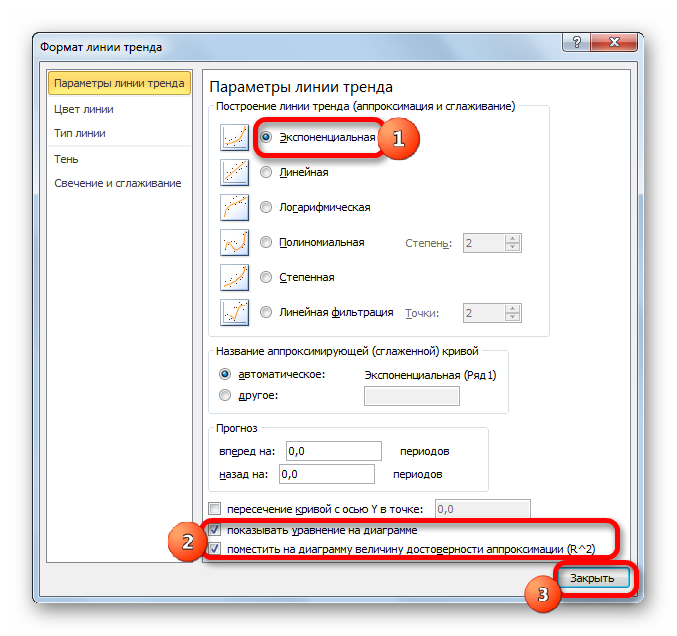
После этого запускается уже знакомое нам окно формата. В блоке выбора типа аппроксимации устанавливаем переключатель в положение «Экспоненциальная». Остальные настройки оставим такими же, как и в первом случае. Щелкаем по кнопке «Закрыть».
Общий вид функции сглаживания при этом такой:
где e – это основание натурального логарифма.
В конкретно нашем случае формула приняла следующую форму:
Способ 3: логарифмическое сглаживание
Теперь настала очередь рассмотреть метод логарифмической аппроксимации.
-
Тем же способом, что и в предыдущий раз через контекстное меню запускаем окно формата линии тренда. Устанавливаем переключатель в позицию «Логарифмическая» и жмем на кнопку «Закрыть».
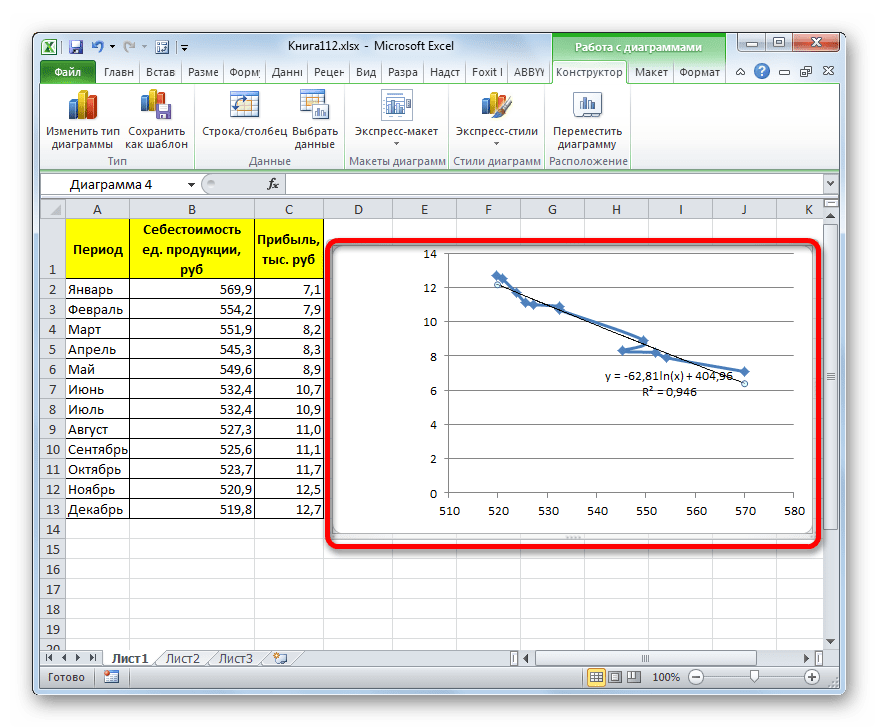
В общем виде формула сглаживания выглядит так:
где ln – это величина натурального логарифма. Отсюда и наименование метода.
В нашем случае формула принимает следующий вид:
Способ 4: полиномиальное сглаживание
Настал черед рассмотреть метод полиномиального сглаживания.
-
Переходим в окно формата линии тренда, как уже делали не раз. В блоке «Построение линии тренда» устанавливаем переключатель в позицию «Полиномиальная». Справа от данного пункта расположено поле «Степень». При выборе значения «Полиномиальная» оно становится активным. Здесь можно указать любое степенное значение от 2 (установлено по умолчанию) до 6. Данный показатель определяет число максимумов и минимумов функции. При установке полинома второй степени описывается только один максимум, а при установке полинома шестой степени может быть описано до пяти максимумов. Для начала оставим настройки по умолчанию, то есть, укажем вторую степень. Остальные настройки оставляем такими же, какими мы выставляли их в предыдущих способах. Жмем на кнопку «Закрыть».
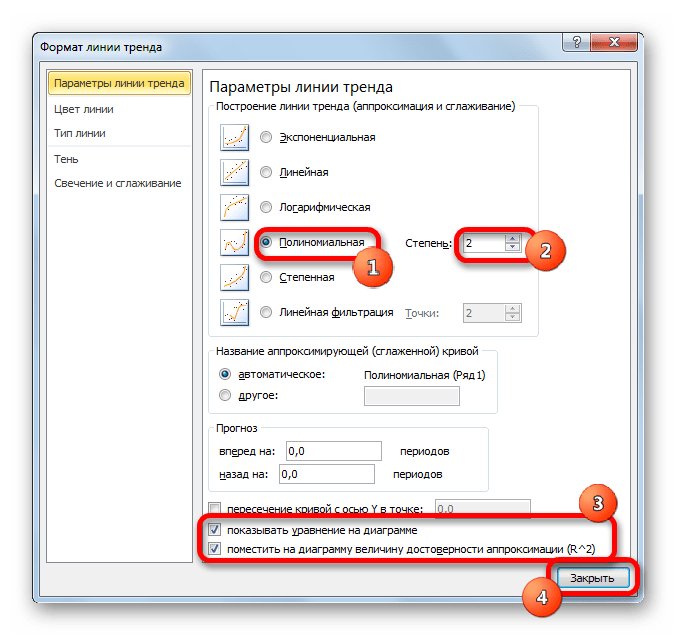
Линия тренда с использованием данного метода построена. Как видим, она ещё более изогнута, чем при использовании экспоненциальной аппроксимации. Уровень достоверности выше, чем при любом из использованных ранее способов, и составляет 0,9724.
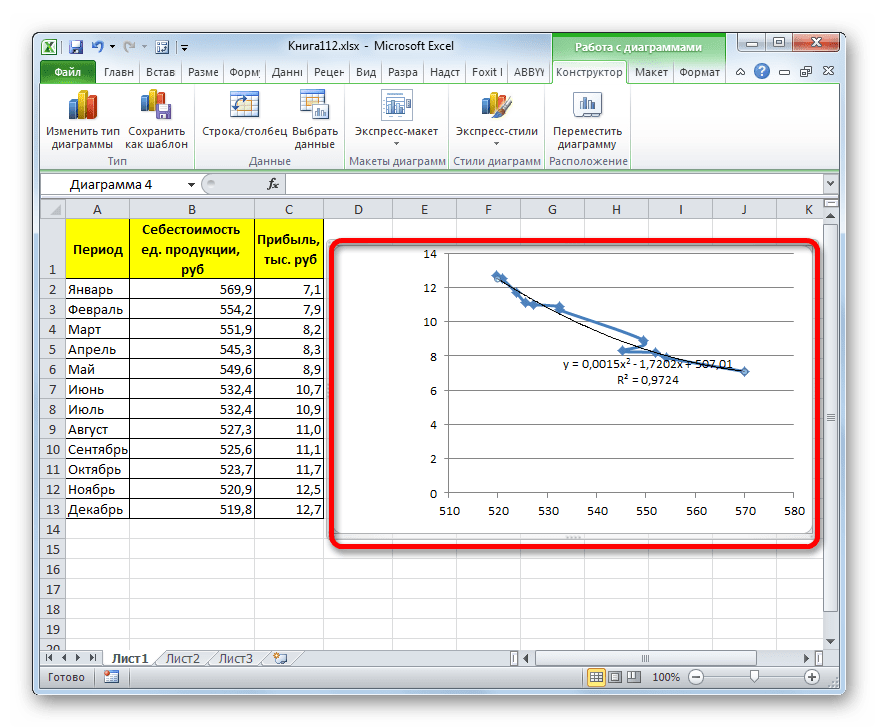
Данный метод наиболее успешно можно применять в том случае, если данные носят постоянно изменчивый характер. Функция, описывающая данный вид сглаживания, выглядит таким образом:
В нашем случае формула приняла такой вид:
y=0,0015*x^2-1,7202*x+507,01
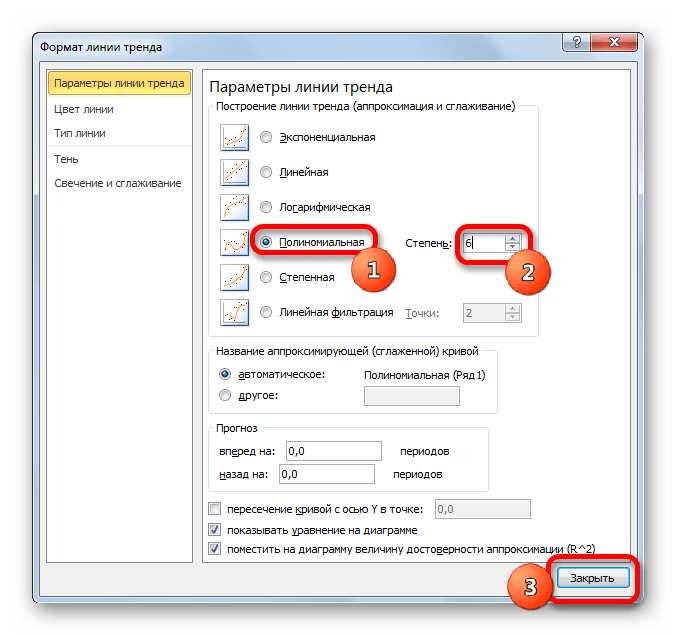
Теперь давайте изменим степень полиномов, чтобы увидеть, будет ли отличаться результат. Возвращаемся в окно формата. Тип аппроксимации оставляем полиномиальным, но напротив него в окне степени устанавливаем максимально возможное значение – 6.
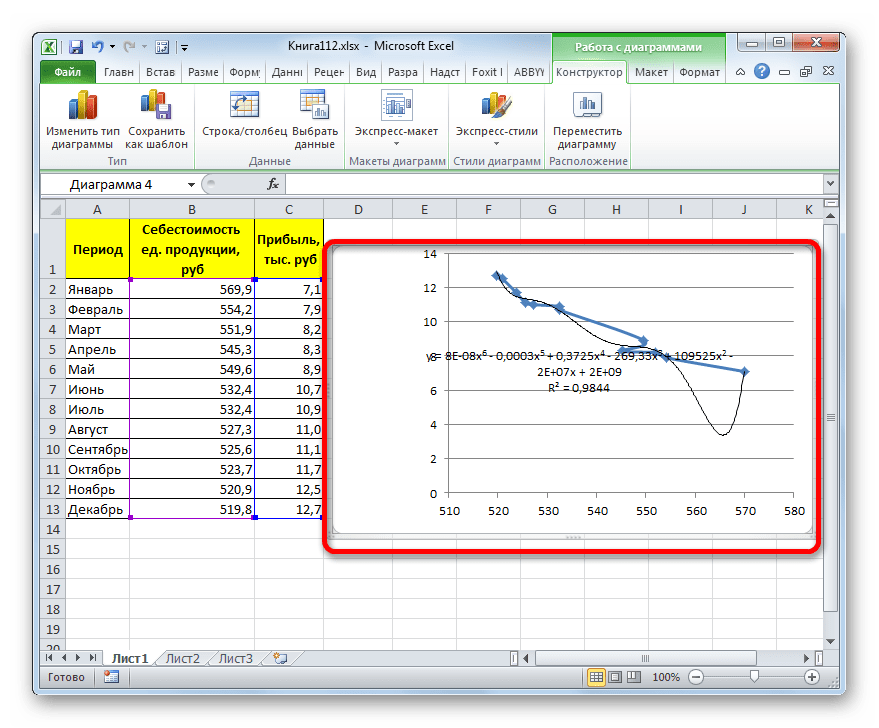
Формула, которая описывает данный тип сглаживания, приняла следующий вид:
Способ 5: степенное сглаживание
В завершении рассмотрим метод степенной аппроксимации в Excel.
-
Перемещаемся в окно «Формат линии тренда». Устанавливаем переключатель вида сглаживания в позицию «Степенная». Показ уравнения и уровня достоверности, как всегда, оставляем включенными. Жмем на кнопку «Закрыть».
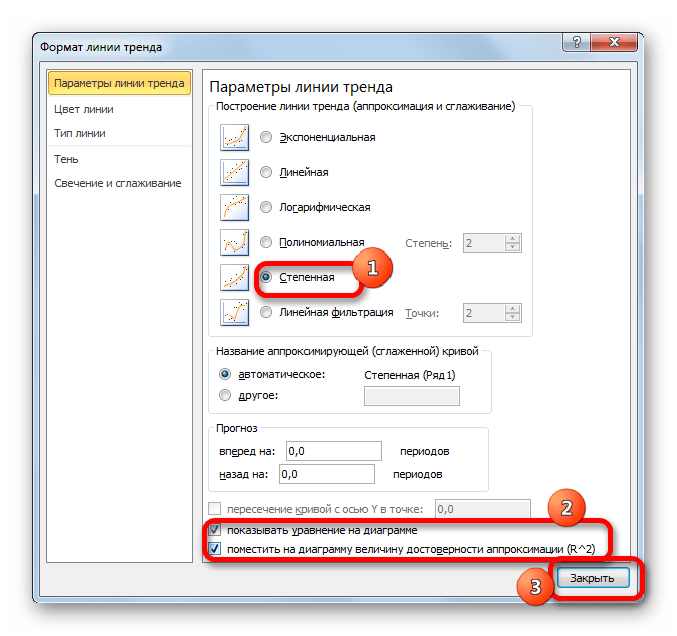
Данный способ эффективно используется в случаях интенсивного изменения данных функции. Важно учесть, что этот вариант применим только при условии, что функция и аргумент не принимают отрицательных или нулевых значений.
Общая формула, описывающая данный метод имеет такой вид:
В конкретно нашем случае она выглядит так:
Как видим, при использовании конкретных данных, которые мы применяли для примера, наибольший уровень достоверности показал метод полиномиальной аппроксимации с полиномом в шестой степени (0,9844), наименьший уровень достоверности у линейного метода (0,9418). Но это совсем не значит, что такая же тенденция будет при использовании других примеров. Нет, уровень эффективности у приведенных выше методов может значительно отличаться, в зависимости от конкретного вида функции, для которой будет строиться линия тренда. Поэтому, если для этой функции выбранный метод наиболее эффективен, то это совсем не означает, что он также будет оптимальным и в другой ситуации.
Если вы пока не можете сразу определить, основываясь на вышеприведенных рекомендациях, какой вид аппроксимации подойдет конкретно в вашем случае, то есть смысл попробовать все методы. После построения линии тренда и просмотра её уровня достоверности можно будет выбрать оптимальный вариант.
Отблагодарите автора, поделитесь статьей в социальных сетях.
Коэффициент достоверности аппроксимации это значение которое характеризует точность аппроксимации, т. е. показывает на сколько точно теоретическое распределение описывает реальное распределение.
Коэффициент достоверности аппроксимации R 2 показывает степень соответствия трендовой модели исходным данным. Его значение может лежать в диапазоне от 0 до 1. Чем ближе R 2 к 1, тем точнее модель описывает имеющиеся данные.
Критерий Фишера используется для оценки значимости модели в целом.
Для оценки используется уравнение следующего вида:
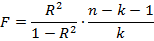
где 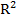 – коэффициент детерминации, n – количество наблюдений, k – число объясняющих переменных.
– коэффициент детерминации, n – количество наблюдений, k – число объясняющих переменных.
Вычисленное по этой формуле значение сравнивается с критическим значением критерия Фишера из таблиц распределения Фишера:
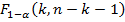
где 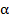 – уровень значимости,
– уровень значимости,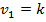 и
и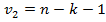 – степени свободы.
– степени свободы.
Если в результате сравнения оказывается, что 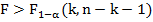 , то при заданном уровне значимости
, то при заданном уровне значимости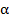 принимается гипотеза о надежности модели в целом. Если в результате сравнения оказывается, что
принимается гипотеза о надежности модели в целом. Если в результате сравнения оказывается, что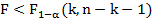 , то при заданном уровне значимости
, то при заданном уровне значимости гипотеза о надежности модели в целом отвергается.
гипотеза о надежности модели в целом отвергается.
52. Понятие экстраполяции (прогнозирование результатов измерений)
Экстраполяция— это метод прогнозирования, который предполагает, что закономерность развития, действовавшая в прошлом, сохранится и в прогнозируемом будущем.
53. Фундаментальная теорема переноса ошибок имеет вид:
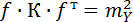 где
где 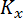 – корреляционная матрица,
– корреляционная матрица, 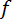 – матрица производных функций
– матрица производных функций 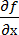 . Эта формула применяется при оценке функций.
. Эта формула применяется при оценке функций.
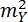 – это дисперсия DY.
– это дисперсия DY.
Если оценивается несколько функций, то матрица f будет являться матрицей Якоби (используем формулу 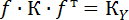 ).
).
Получим ковариационную матрицу, диагональные элементы которой соответствуют дисперсии, корень из дисперсии будет соответствовать СКО функций.
Если мы имеем функцию суммы или разности двух независимых величин
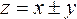 , то квадрат средней квадратической ошибки функции выразится формулой
, то квадрат средней квадратической ошибки функции выразится формулой
mz 2 =mx 2 +my 2 При 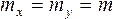
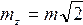
Если функция имеет вид
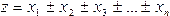 ,
,
то 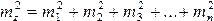 (14)
(14)
т. е. квадрат средней квадратической ошибки алгебраической суммы аргументов равен сумме квадратов средних квадратических ошибок слагаемых.
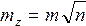 т. е. средняя квадратическая ошибка алгебраической суммы (разности) измеренных с одинаковой точностью величин в
т. е. средняя квадратическая ошибка алгебраической суммы (разности) измеренных с одинаковой точностью величин в 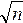 раз больше средней квадратической ошибки одного слагаемого.
раз больше средней квадратической ошибки одного слагаемого.
Если функция имеет вид
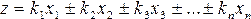
То 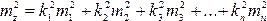 где k1, k2, kз, . kп — постоянные числа; m1,m2,m3. тп — средние квадратические ошибки соответствующих аргументов. Если имеем функцию многих независимых переменных общего вида
где k1, k2, kз, . kп — постоянные числа; m1,m2,m3. тп — средние квадратические ошибки соответствующих аргументов. Если имеем функцию многих независимых переменных общего вида
то 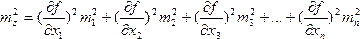 . (15)
. (15)
Из формулы (15) следует, что квадрат средней квадратической ошибки функции общего вида равен сумме квадратов произведений частных производных по каждому аргументу на среднюю квадратическую ошибку соответствующего аргумента
54. Оценка точности функций зависимых результатов измерений.
Формулы для вычислений средних квадратических ошибок функции u=f(x1,x2,….xn)
а) в случае некоррелированных аргументов :
mu 2 =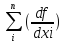 2 mxi 2
2 mxi 2
б) для коррелированных аргументов
mu 2 =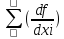 2 mxi 2 +2
2 mxi 2 +2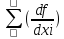
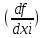 rxi xj mxi mxj
rxi xj mxi mxj
Для системы функций (вектор-функции) u = f(X)
Mu 2 = AM 2 xA T где Mu 2 и M 2 x – соответственно эмпирическне корреляционные матрицы вектор-функции и вектора измерений. А – Матрица
Квадрат коэффициента корреляции (r 2 ) называется коэффициентом детерминации или аппроксимации и обозначается RI или R 2 .Этот коэффициент показывает долю (%) тех изменений, которые в данном явлении зависят от изучаемого фактора. Коэффициент детерминации является более непосредственным и прямым способом выражения зависимости одной величины от другой, и в этом отношении он предпочтительнее коэффициента корреляции. В случаях, где известно, что независимая переменная у находится в причинной связи с независимой переменной х, значение r 2 показывает ту долю элементов в вариации у, которая определена влиянием х. Так, например, если было установлено, что коэффициент корреляции между дозой азотного удобрений и содержанием белка в зерне составил 0,96, то можно утверждать, что 92% (0,96 · 0,96) колебаний содержания белка в зерне обусловлено варьированием доз азотного удобрения.
В практической статистике, коэффициенты детерминации или аппроксимации более широко используются при характеристике изучаемых взаимосвязей. Его можно использовать не только для описания прямолинейной связи между признаками, но и криволинейной (в этом случае, его называют коэффициент аппроксимации, и он представляет собой квадрат корреляционного отношения 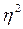 ).
).
Обычно при определении взаимосвязи между изучаемыми признаками устанавливают последовательно коэффициент корреляции, коэффициент детерминации (или аппроксимации) и скорректированный коэффициент детерминации (RIadj), который рассчитывается по формуле:
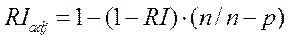 . (57)
. (57)
Именно, скорректированный коэффициент детерминации позволяет судить с высокой степенью вероятности о том, насколько процентов варьирование результативного признака обусловлено варьированием факториального.
Множественная корреляция.Корреляцияназывается множественной если на величину результативного признака одновременно влияют несколько факториальных.
Наиболее простой формой множественной связи является линейная зависимость между тремя признаками, когда один из них, например содержание белка в зерне , рассматривается как результативный признак функции у, а два другие – доза азотного удобрения и количество осадков за вегетацию – как аргументы x и z. В качестве меры тесноты линейной связи трёх признаков используют частные коэффициенты корреляции, обозначаемые rxy·z, rxz·y, rzy·x, и множественные коэффициенты корреляции, обозначаемые символами Rxy·z, Rxz·y, Rzy·x.
Частные коэффициенты корреляции рассчитываются по формулам:
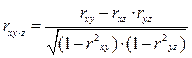 ; (58)
; (58)
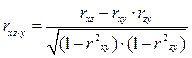 ; (59)
; (59)
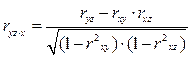 . (60)
. (60)
Ошибку и критерий значимости частной корреляции определяют аналогично, что и парной корреляции.
Множественный коэффициент корреляции нескольких переменных – это показатель тесноты связи между одним из признаков (буква индекса перед точкой) и совокупностью других признаков (буквы индекса после точки). Коэффициент корреляции трёх переменных рассчитывается по следующим формулам:
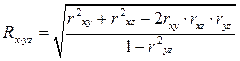 ; (61)
; (61)
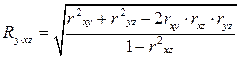 ; (62)
; (62)
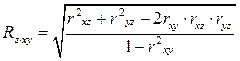 . (63)
. (63)
Эти формулы позволяют легко вычислить множественные коэффициенты корреляции при известных значениях коэффициентов парной корреляции. Коэффициент R положителен и всегда находится в пределах от 0 до 1.
Квадрат коэффициента множественной корреляции называется коэффициентом множественной детерминации, который, как и обыкновенный коэффициент детерминации, обозначается RI или R 2 .
Значимость множественной корреляции оценивается по F – критерию:
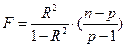 , (64)
, (64)
где n – объём выборки,
p – число независимых переменных или признаков.
Теоретическое значение F – критерия берут из приложения III для df1 = р-1 и df2 = n–p степеней свободы и принятого уровня значимости. Нулевая гипотеза о равенстве множественного коэффициента корреляции в совокупности нулю (Н : R = 0) принимается, если Fфакт
Парная регрессияхарактеризует связь между двумя признаками: результативным и факторным. Аналитически связь между ними описывается уравнениями:
прямой 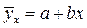 ;
;
гиперболы 
параболы 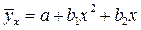 и т.д.
и т.д.
Определить тип уравнения можно, исследуя зависимость графически, однако в практике не часто прибегают к этому методу определения уравнения.
Оценка параметров уравнений регрессии (а, b1, b2…) осуществляется методом наименьших квадратов, в основе которого лежит предположение о независимости наблюдений исследуемой совокупности и нахождении параметров модели при которых минимизируется сумма квадратов отклонений эмпирических (фактических) значений результативного признака от теоретических, полученных по выбранному уравнению регрессии:
SS = 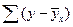 → min
→ min

Рисунок 8. Прямая линия регрессии на графике зависимости содержания белка в зерне ячменя от дозы азотного удобрения
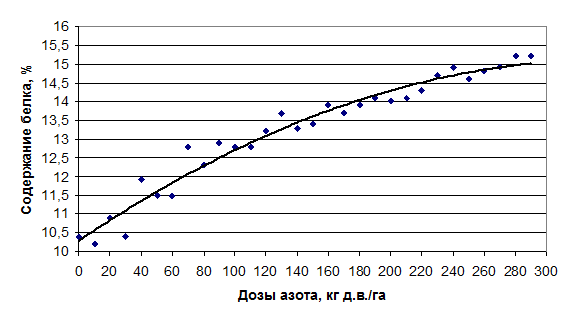
Рисунок 9. Параболическая линия регрессии на графике зависимости содержания белка в зерне ячменя от дозы азотного удобрения
В отношении установленной зависимости между дозами азотного удобрения и содержания белка в зерне ячменя данное правило можно интерпретировать так: прямая линия должна быть максимально приближена ко всем значениям ху или ух, что отчётливо отмечается на графике (рисунок 2 и рисунок 3)
Задача регрессионного анализа состоит в том, чтобы установить параметры уравнения регрессии (а, b1, b2…) или иными словами, описать взаимосвязь между изучаемыми показателями с помощью уравнения, оценить на какую величину изменяется значение результативного признака, при изменении факторного на единицу.
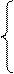 Нахождение параметров линейной парной регрессии общепринятым методом осуществляется решением системы нормальных уравнений следующего вида:
Нахождение параметров линейной парной регрессии общепринятым методом осуществляется решением системы нормальных уравнений следующего вида:
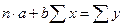
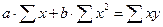 , (65)
, (65)
где n – объём исследуемой совокупности (число единиц наблюдений).
В уравнениях регрессии параметр a показывает усреднённое влияние на результативный признак неучтённых в уравнении факторных признаков: коэффициент регрессии b показывает, на сколько изменяется в среднем значение результативного признака при увеличении факторного на единицу собственного измерения. Таким образом, решая данную систему нормальных уравнений задача состоит именно в определении параметров уравнения регрессии a и b.
Уравнение линейной регрессии , в сельскохозяйственных и биологических исследованиях нередко представляют несколько в другом виде:
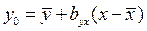 , (66)
, (66)
или аналогично для нахождения теоретической линии регрессии х по у: 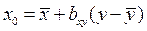 , (67)
, (67)
где 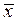 и
и 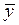 – средние арифметические для ряда х и у;
– средние арифметические для ряда х и у;
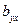 – коэффициент регрессии у по х,
– коэффициент регрессии у по х,
 – коэффициент регрессии х по у .
– коэффициент регрессии х по у .
Коэффициенты регрессии вычисляются по формулам:
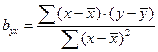 ; (68)
; (68)
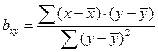 . (69)
. (69)
Числители этих формул представляют собой сумму произведений отклонений значений х и у от своих средних (то есть числитель формулы (64) расчёта коэффициента корреляции), а знаменатели – сумму квадратов отклонений от средних. Таким образом, связь между коэффициентов корреляции и коэффициентом регрессии можно математически выразить так:
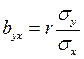 ;
; 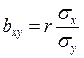 . (70, 71)
. (70, 71)
Произведение коэффициентов регрессии равно коэффициенту детерминации:
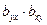 =RI (72)
=RI (72)
При регрессионном анализе проводят обычно две оценки выборочных коэффициентов регрессии: а) оценки величины отклонений от линии регрессии и б) оценку существенности b, то есть значимость отклонения его от нуля.
Ошибка коэффициента регрессии вычисляется по формуле:
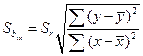 и
и  . (73, 74)
. (73, 74)
Критерий существенности коэффициента регрессии определяют по формуле:
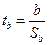 (75)
(75)
Существенность коэффициента регрессии оценивают по приложению II, число степеней свободы df принимают равным n–2.
ПРИЛОЖЕНИЯ
Значения критерия ω (по Н.Ф. Деревицкому)
| Число степеней свободы | Уровень значимости | Число степеней свободы 5%-ный | Уровень значимости |
| 5%-ный | 1%-ный | 5%-ный | 1%-ный |
| 1,41 | 1,41 | 1,93 | 2,45 |
| 1,64 | 1,72 | 1,93 | 2,45 |
| 1,76 | 1,92 | 1,93 | 2,46 |
| 1,81 | 2,05 | 1,93 | 2,46 |
| 1,85 | 2,14 | 1,94 | 2,47 |
| 1,87 | 2,21 | 1,94 | 4,47 |
| 1,88 | 2,26 | 1,94 | 2,48 |
| 1,90 | 2,29 | 1,94 | 2,48 |
| 1,90 | 2,32 | 1,94 | 2,49 |
| 1,91 | 2,34 | 1,94 | 2,49 |
| 1,92 | 2,35 | 1,94 | 2,50 |
| 1,92 | 2,38 | 1,94 | 2,50 |
| 1,92 | 2,39 | 1,94 | 2,50 |
| 1,92 | 2,41 | 1,94 | 2,51 |
| 1,93 | 2,42 | 1,95 | 2,53 |
| 1,93 | 2,43 | 1,95 | 2,54 |
| 1,93 | 2,44 | 1,96 | 2,55 |
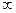 |
1,96 | 2,58 |
Стандартные значения критерия t (критерия Стьюдента) на 5%-ном, 1%-ном и 0,1%-ном уровне значимости (округлены до десятых)
| Число степеней свободы | Уровень значимости | Число степеней свободы | Уровень значимости | |||
| 0,05 | 0,01 | 0,001 | 0,05 | 0,01 | 0,001 | |
| 12,7 | 63,7 | 637,0 | 2,2 | 3,0 | 4,1 | |
| 4,3 | 9,9 | 31,6 | 14-15 | 2,1 | 3,0 | 4,1 |
| 3,2 | 5,8 | 12,9 | 16-17 | 2,1 | 2,9 | 4,0 |
| 2,8 | 4,6 | 8,6 | 18-20 | 2,1 | 2,9 | 3,9 |
| 2,6 | 4,0 | 6,9 | 21-24 | 2,1 | 2,8 | 3,8 |
| 2,4 | 3,7 | 6,0 | 25-28 | 2,1 | 2,8 | 3,7 |
| 2,4 | 3,5 | 5,3 | 29-30 | 2,0 | 2,8 | 3,7 |
| 2,3 | 3,4 | 5,0 | 31-34 | 2,0 | 2,7 | 3,7 |
| 2,3 | 3,3 | 4,8 | 35-42 | 2,0 | 2,7 | 3,6 |
| 2,2 | 3,2 | 4,6 | 43-62 | 2,0 | 2,7 | 3,5 |
| 2,2 | 3,1 | 4,4 | 63-175 | 2,0 | 2,6 | 3,4 |
| 2,2 | 3,1 | 4,3 | ≥176 | 2,0 | 2,6 | 3,3 |
Наиболее значимые стандартные значения критерия F (критерия Р.Фишера) на 5%-ном, 1%-ном (жирным шрифтом) уровне значимости
(округлены до десятых)
| Число степеней свободы для меньшей дисперсии (df2) | Число степеней свободы для большей дисперсии (df1) | ||||||||||
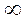 |
|||||||||||
| 6,0 13,7 | 5,1 10,9 | 4,8 9,8 | 4,5 9,2 | 4,4 8,8 | 4,3 8,5 | 4,2 8,3 | 4,2 8,1 | 4,0 7,7 | 3,8 7,3 | 3,7 6,9 | |
| 5,6 12,3 | 4,7 9,6 | 4,4 8,5 | 4,1 7,9 | 4,0 7,5 | 3,9 7,2 | 3,8 7,0 | 3,7 6,8 | 3,6 6,5 | 3,4 6,1 | 3,2 5,7 | |
| 5,3 11,3 | 4,5 8,7 | 4,1 7,6 | 3,8 7,0 | 3,7 6,3 | 3,6 6,4 | 3,5 6,2 | 3,4 6,0 | 3,3 5,7 | 3,1 5,3 | 2,9 4,9 | |
| 5,1 10,6 | 4,3 8,0 | 3,9 7,0 | 3,6 6,4 | 3,5 6,1 | 3,4 5,8 | 3,3 5,6 | 3,2 5,5 | 3,1 5,1 | 2,9 4,7 | 2,7 4,3 | |
| 5,0 10,0 | 4,1 7,6 | 3,7 6,6 | 3,5 6,0 | 3,3 5,6 | 3,2 5,4 | 3,1 5,2 | 3,1 5,1 | 2,9 4,7 | 2,7 4,3 | 2,5 3,9 | |
| 4,8 9,7 | 4,0 7,2 | 3,6 6,2 | 3,4 5,7 | 3,2 5,3 | 3,1 5,1 | 3,0 4,9 | 3,0 4,7 | 2,8 4,4 | 2,6 4,0 | 2,4 3,6 | |
| 4,8 9,3 | 3,9 6,9 | 3,5 6,0 | 3,3 5,4 | 3,1 5,1 | 3,0 4,8 | 2,9 4,6 | 2,8 4,5 | 2,7 4,2 | 2,5 3,8 | 2,3 3,4 | |
| 4,7 9,1 | 3,8 6,7 | 3,4 5,7 | 3,2 5,2 | 3,0 4,9 | 2,9 4,6 | 2,8 4,4 | 2,8 4,3 | 2,6 4,0 | 2,4 3,6 | 2,2 3,2 | |
| 4,6 8,9 | 3,7 6,5 | 3,3 5,6 | 3,1 5,0 | 3,0 4,7 | 2,9 4,5 | 2,8 4,3 | 2,7 4,1 | 2,5 3,8 | 2,3 3,4 | 2,1 3,0 | |
| 4,5 8,7 | 3,7 6,4 | 3,3 5,4 | 3,1 4,9 | 2,9 4,6 | 2,8 4,3 | 2,7 4,1 | 2,6 4,0 | 2,5 3,7 | 2,3 3,3 | 2,3 2,9 | |
| 4,5 8,5 | 3,6 6,2 | 3,2 5,3 | 3,0 4,8 | 2,9 4,4 | 2,7 4,2 | 2,7 4,0 | 2,6 3,9 | 2,4 3,6 | 2,2 3,2 | 2,0 2,8 | |
| 4,4 8,3 | 3,6 6,0 | 3,2 5,1 | 2,9 4,6 | 2,8 4,3 | 2,7 4,0 | 2,6 3,8 | 2,5 3,7 | 2,3 3,4 | 2,1 3,0 | 1,9 2,6 | |
| 4,4 8,1 | 3,5 5,9 | 3,1 4,9 | 2,9 4,4 | 2,7 4,1 | 2,6 3,9 | 2,5 3,7 | 2,4 3,6 | 2,3 3,2 | 2,1 2,9 | 1,8 2,4 | |
| 4,3 7,9 | 3,4 5,7 | 3,1 4,8 | 2,8 4,3 | 2,7 4,0 | 2,6 3,8 | 2,5 3,6 | 2,4 3,5 | 2,2 3,1 | 2,0 2,8 | 1,8 2,3 | |
| 4,3 7,8 | 3,4 5,6 | 3,0 4,7 | 2,8 4,2 | 2,6 3,9 | 2,5 3,7 | 2,4 3,5 | 2,4 3,3 | 2,2 3,0 | 2,0 2,7 | 1,7 2,2 | |
| 4,2 7,7 | 3,4 5,5 | 3,0 4,6 | 2,7 4,1 | 2,6 3,8 | 2,5 3,6 | 2,4 3,4 | 2,3 3,3 | 2,2 3,0 | 1,9 2,6 | 1,7 2,1 | |
| 4,2 7,6 | 3,3 5,4 | 2,9 4,5 | 2,7 4,0 | 2,5 3,7 | 2,4 3,5 | 2,3 3,3 | 2,3 3,2 | 2,1 2,8 | 1,9 2,5 | 1,6 2,0 | |
| |
3,8 6,6 | 3,0 4,6 | 2,6 3,8 | 2,4 3,3 | 2,2 3,0 | 2,1 2,8 | 2,0 2,6 | 1,9 2,5 | 1,8 2,2 | 1,5 1,8 | 1,0 1,0 |
Дата добавления: 2016-12-06 ; просмотров: 4217 | Нарушение авторских прав