Содержание
- 1 Решение: запрет на индексацию сайта с помощью robots.txt
- 2 Закрыть сайт от индексации в файле .htaccess
- 3 Задача: закрыть от индексации поддомен
- 4 Закрываем блок на сайте от индекса
- 5 Универсальный вариант скрытия картинок от индексации
- 6 Задача: закрыть внешние или внутренние ссылки от индексации
- 7 Как закрыть от индексации страницу на сайте
- 8 Как закрыть от индексации сразу весь раздел на проекте
- 9 Закрываем папку от индексации
- 10 Пять вариантов закрыть дубли на сайте от индексации Яндекс и Google
- 11 Запрет индексации сайта через .htaccess
- 12 Запрет индексации сайта через robots.txt
- 13 Запрет индексации с помощью .htaccess
- 14 Запрет с помощью .htaccess


Зачем закрывают сайт или какие-то его части от индексации поисковых систем? Ответов несколько
- Нужно скрыть от общего доступа какую то секретную информацию.
- В целях создания релевантного контента: бывают случаи, когда хочется донести до пользователей больше информации, но она размывает текстовую релевантность.
- Закрыть дублированный контент.
- Скрыть мусорную информацию: поисковые системы очень не любят контент, который не несет или имеет устаревший смысл, например, календарь в афише.
Вся статья будет неким хелпом по закрытию от индексации для различных ситуаций:
Решение: запрет на индексацию сайта с помощью robots.txt
Создаем текстовый файл с названием robots, получаем robots.txt.
Копируем туда этот код
Полученный файл с помощью FTP заливаем в корень сайта.
Если нужно закрыть индексацию сайта только от Яндекс:
Если же скрываем сайт только от Google, то код такой:
Закрыть сайт от индексации в файле .htaccess
Способ первый
В файл .htaccess вписываем следующий код:
Каждая строчка для отдельной поисковой системы
Способ второй и третий
Для всех страниц на сайте подойдет любой из вариантов – в файле .htaccess прописываем любой из ответов сервера для страницы, которую нужно закрыть.
- Ответ сервера – 403 Доступ к ресурсу запрещен -код 403 Forbidden
- Ответ сервера – 410 Ресурс недоступен – окончательно удален
Способ четвертый
Запретить индексацию с помощью доступа к сайту только по паролю
В файл .htaccess, добавляем такой код:
Авторизацию уже увидите, но она пока еще не работает
Теперь необходимо добавить пользователя в файл паролей:
USERNAME это имя пользователя для авторизации. Укажите свой вариант.
Задача: закрыть от индексации поддомен
Поддомен для поисковых систем является отдельным сайтом, из чего следует, что для него подходят все варианты того, как закрыть от индексации сайт.
Закрываем блок на сайте от индекса
Довольно часто требуется закрыть от индексации определенный блок: меню, счетчик, текст или какой-нибудь код.
Когда был популярен в основном Яндекс, а Google все само как то в топ выходило, все использовали вариант Тег "noindex"
Но потом Яндекс все чаще и чаще стал не обращать внимания на такой технический прием, а Google вообще не понимает такой комбинации и все стали использовать другую схему для скрытия от индексации части текста на странице – с помощью javascript:
Текст или любой блок – кодируется в javascript , а потом сам скрипт закрывается от индексации в robots.txt
Как это реализовать?
- Файл BASE64.js для декодирования того, что нужно скрыть.
- Алгоритм SEOhide.js.
- Jquery.
- Robots.txt (чтобы скрыть от индексации сам файл SEOhide.js)
- HTML код
BASE64.js. Здесь я его приводить не буду, в данном контексте он нам не так интересен.
Переменные seoContent и seoHrefs. В одну записываем html код, в другую ссылки.
- de96dd3df7c0a4db1f8d5612546acdbb — это идентификатор, по которому будет осуществляться замена.
- 0JHQu9C+0LMgU0VPINC80LDRgNC60LXRgtC+0LvQvtCz0LAgLSDQn9Cw0LLQu9CwINCc0LDQu9GM0YbQtdCy0LAu— html, который будет отображаться для объявленного идентификатора.
И сам HTML файл:
В robots.txt обязательно скрываем от индексации файл SEOhide.js.
Универсальный вариант скрытия картинок от индексации
К примеру, вы используете на сайте картинки, но они не являются оригинальными. Есть страх, что поисковые системы воспримут их негативно.
Код элемента, в данном случае ссылки, на странице, будет такой:
Скрипт, который будет обрабатывать элемент:
Задача: закрыть внешние или внутренние ссылки от индексации
Обычно это делают для того, чтобы не передавать вес другим сайтам или при перелинковке уменьшить уходящий вес текущей страницы.
Создаем файл transfers.js
Эту часть кода вставляем в transfers.js
Этот файл, размещаем в соответствующей папке (как в примере "js") и на странице в head вставляем код:
А это и есть сама ссылка, которую нужно скрыть от индексации:
Как закрыть от индексации страницу на сайте
- 1 Вариант – в robots.txt
Disallow: /url-stranica.html
- 2 Вариант – закрыть страницу в метегах – это наиболее правильный вариант
- 3 Вариант – запретить индексацию через ответ сервера
Задача, чтобы ответ сервера для поисковых систем был
404 – ошибка страницы
410 – страница удаленна
Добавить в файл .htaccess:
это серый метод, использовать в крайних мерах
Как закрыть от индексации сразу весь раздел на проекте
1 Вариант реализовать это с помощь robots.txt
Также подойдут варианты, которые используются при скрытии страницы от индекса, только в данном случае это должно распространятся на все страницы раздела – конечно же если это позволяет сделать автоматически
- Ответ сервера для всех страниц раздела
- Вариант с метатегами к каждой странице
Это все можно реализовать программно, а не в ручную прописывать к каждой странице – трудозатраты – одинаковые.
Конечно же проще всего это прописать запрет в robots, но наша практика показывает, что это не 100% вариант и поисковые системы бывает игнорируют запреты.
Закрываем папку от индексации
В данном случае под папкой имеется ввиду не раздел,а именно папка в которой находят файлы, которые стоит скрыть от поисковых систем – это или картинки или документы
Единственный вариант для отдельной папки это реализация через robots.txt
Пять вариантов закрыть дубли на сайте от индексации Яндекс и Google
1 Вариант – и самый правильный, чтобы их не было – нужно физически от них избавиться т.е при любой ситуации кроме оригинальной страницы – должна показываться 404 ответ сервера
2 Вариант – использовать Атрибут rel="canonical" – он и является самым верным. Так как помимо того, что не позволяет индексироваться дублям, так еще и передает вес с дублей на оригиналы
Ну странице дубля к коде необходимо указать
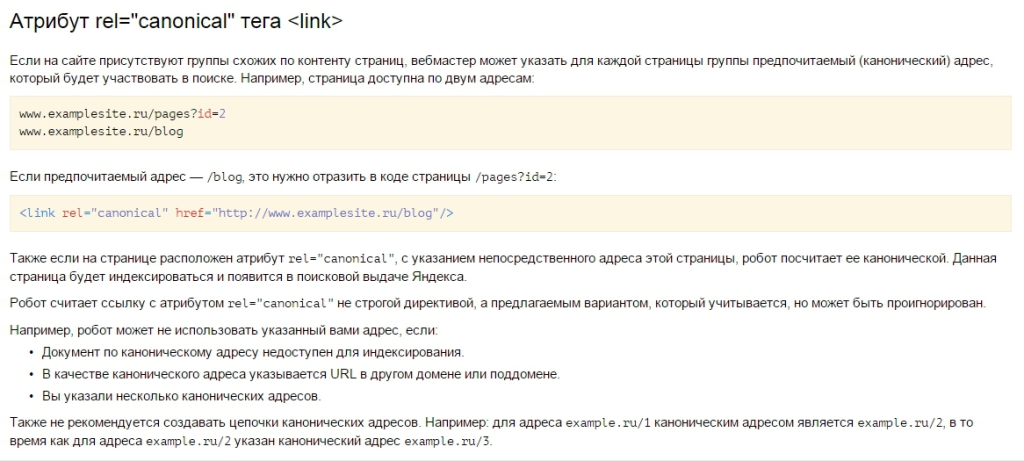
3 Вариант избавиться от индексации дублей – это все дублирующие страницы склеить с оригиналами 301 редиректом через файл .htaccess
4 Вариант – метатеги на каждой странице дублей
5 Вариант – все тот же robots
Если что то упустили, будем рады любым дополнениям в комментариях.

Запрет индексации сайта через .htaccess
В файл .htaccess прописываем коды ( для каждого робота на новой строчке ):
Запрет индексации сайта через robots.txt
 Файл robots.txt – это текстовый файл, находящийся в корневой директории сайта, в котором записываются специальные инструкции для поисковых роботов. Эти инструкции могут запрещать к индексации некоторые разделы или страницы на сайте, указывать на правильное «зеркалирование» домена, рекомендовать поисковому роботу соблюдать определенный временной интервал между скачиванием документов с сервера и т.д.
Файл robots.txt – это текстовый файл, находящийся в корневой директории сайта, в котором записываются специальные инструкции для поисковых роботов. Эти инструкции могут запрещать к индексации некоторые разделы или страницы на сайте, указывать на правильное «зеркалирование» домена, рекомендовать поисковому роботу соблюдать определенный временной интервал между скачиванием документов с сервера и т.д.
Чтобы создать файл robots.txt, нужен простой текстовый файл. Если вы не собираетесь создавать запреты к индексации, можно сделать пустой файл robots.txt.

Самый простой Robots.txt
Самый простой robots.txt , который всем поисковым системам, разрешает всё индексировать, выглядит вот так:
User-agent: *
Disallow:
Если у директивы Disallow не стоит наклонный слеш в конце, то разрешены все страницы для индексации.
Такая директива полностью запрещает сайт к индексации:
User-agent: *
Disallow: /
User-agent – обозначает для кого предназначены директивы, звёздочка обозначает что для всех ПС, для Яндекса указывают User-agent: Yandex .
В справке Яндекса написано, что его поисковые роботы обрабатывают User-agent: * , но если присутствует User-agent: Yandex , User-agent: * игнорируется.
Директивы Disallow и Allow
Существуют две основные директивы:
Disallow – запретить
Allow – разрешить
Пример: На блоге мы запретили индексировать папку /wp-content/ где находятся файлы плагинов, шаблон и.т.п. Но так же там находятся изображения, которые должны быть проиндексированы ПС, для участия в поиске по картинкам. Для этого надо использовать такую схему:
User-agent: *
Allow: /wp-content/uploads/ # Разрешаем индексацию картинок в папке uploads
Disallow: /wp-content/
Порядок использования директив имеет значение для Яндекса, если они распространяются на одни страницы или папки. Если вы укажите вот так:
User-agent: *
Disallow: /wp-content/
Allow: /wp-content/uploads/
Изображения не будут скачиваться роботом Яндекса с каталога /uploads/ , потому что исполняется первая директива, которая запрещает весь доступ к папке wp-content .
Google относится проще и выполняет все директивы файла robots.txt, вне зависимости от их расположения.
Так же, не стоит забывать, что директивы со слешем и без, выполняют разную роль:
Disallow: /about Запретит доступ ко всему каталогу site.ru/about/ , так же не будут индексироваться страницы которые содержат about – site.ru/about.html , site.ru/aboutlive.html и.т.п.
Disallow: /about/ Запретит индексацию роботам страниц в каталоге site.ru/about/ , а страницы по типу site.ru/about.html и.т.п. будут доступны к индексации.
Регулярные выражения в robots.txt
Поддерживается два символа, это:
* – подразумевает любой порядок символов.
Disallow: /about* запретит доступ ко всем страницам, которые содержат about, в принципе и без звёздочки такая директива будет так же работать. Но в некоторых случаях это выражение не заменимо. Например, в одной категории имеются страницы с .html на конце и без, чтобы закрыть от индексации все страницы которые содержат html, прописываем вот такую директиву:
Disallow: /about/*.html
Теперь страницы site.ru/about/live.html закрыта от индексации, а страница site.ru/about/live открыта.
Ещё пример по аналогии:
User-agent: Yandex
Allow: /about/*.html #разрешаем индексировать
Disallow: /about/
Все страницы будут закрыты, кроме страниц которые заканчиваются на .html
$ – обрезает оставшуюся часть и обозначает конец строки.
Disallow: /about – Эта директива robots.txt запрещает индексировать все страницы, которые начинаются с about , так же идёт запрет на страницы в каталоге /about/ .
Добавив в конце символ доллара – Disallow: /about$ мы сообщим роботам, что нельзя индексировать только страницу /about , а каталог /about/ , страницы /aboutlive и.т.п. можно индексировать.
Войти
Запрет индексации с помощью .htaccess
Главной особенностью было то, что запрет на индексацию нужно было сделать не через прописывание запрета в robots.txt, а с помощью файла .htaccess.
Нужно это было для того, чтобы никто кроме меня не знал, что я запретил.
Запрет с помощью .htaccess
Для осуществления данного действия нужно чтобы у вас в корневой папке домена находился файл .htaccess.
Если у вас такой файл есть – а его особенность – отсутсвие имени и наличние только расширения, то есть (точка)htaccess, то можно просто внести в него изменения. Если такого файла нет, то его очень просто сделать: нужно в блокноте создать файлик htaccess.txt , и переименовать в .htaccess.
Кстати в проводнике windows с этим могут быть проблемы.
Когда вы убедились, что файлик .htaccess есть, в него просто нужно дописать следующие строки:
SetEnvIfNoCase User-Agent "^Googlebot" search_bot
SetEnvIfNoCase User-Agent "^Yandex" search_bot
SetEnvIfNoCase User-Agent "^Yahoo" search_bot
Вышеописанные строки для трех основных поисковиков Google, Yandex и Yahoo.
Что именно мы прописали в .htaccess для запрета?
Попробую расшифровать написанное на примере Google
SetEnvIfNoCase User-Agent "^Googlebot" search_bot
SetEnvIfNoCase – это мы задаем условия для переменной env
User-Agent – означает какая именно переменная, в данном случае это имя агента или бота поисковой машины
"^Googlebot" собственно это имя этого агента
А search_bot – это значение переменной
Другими словами (по русски) строчка
SetEnvIfNoCase User-Agent "^Googlebot" search_bot
Значит: если на сайт придет бот у которого в имени будет содержаться слово Googlebot, то такому боту задать значение переменной env= search_bot (пометить его как search_bot)
Запрет других ботов в .htaccess
Вот список других ботов которые могут вас навестить:
SetEnvIfNoCase User-Agent "^Aport" search_bot
SetEnvIfNoCase User-Agent "^msnbot" search_bot
SetEnvIfNoCase User-Agent "^spider" search_bot
SetEnvIfNoCase User-Agent "^Robot" search_bot
SetEnvIfNoCase User-Agent "^php" search_bot
SetEnvIfNoCase User-Agent "^Mail" search_bot
SetEnvIfNoCase User-Agent "^bot" search_bot
SetEnvIfNoCase User-Agent "^igdeSpyder" search_bot
SetEnvIfNoCase User-Agent "^Snapbot" search_bot
SetEnvIfNoCase User-Agent "^WordPress" search_bot
SetEnvIfNoCase User-Agent "^BlogPulseLive" search_bot
SetEnvIfNoCase User-Agent "^Parser" search_bot
Задаем правило для запрета в .htaccess
Вот само правило:
Deny from env=search_bot
в строке Order Allow,Deny
Мы указываем порядок доступа, у нас сказано сначала разрешить, а потом запретить
Allow from all – разрешить всем
Deny from env=search_bot – запретить доступ тем, кто помечен флажком search_bot, в данном случае это боты, которые мы перечисляли выше
Нужно заметить что такое правило запрещает доступ этим ботам на весь сайт, если мы хотим запретить в .htaccess только определенный файл или группу файлов нужно их уточнить, делается это так:
Deny from env=search_bot
То есть все тоже самое, но мы ограничиваем область запрета в FilesMatch
"^.*$" эта комбинация также значит любой файл (^ – начало строки, точка – это любой символ, звезда – любое количество этого символа, то есть сочетание (.*) значит любая комбинация любых символов, а $ – это конец строки). Поэтому такой комбинацией мы запрещаем в .htaccess доступ к любому файлу.
-тут мы запрещаем доступ только к файлу primer.html
– запрет к любому файлу, содержащему слово primer
Примеры запрета в .htaccess для ботов
Запрет на любой файл для ботов:
SetEnvIfNoCase User-Agent "^Yandex" search_bot
SetEnvIfNoCase User-Agent "^Yahoo" search_bot
SetEnvIfNoCase User-Agent "^Googlebot" search_bot
SetEnvIfNoCase User-Agent "^Aport" search_bot
SetEnvIfNoCase User-Agent "^msnbot" search_bot
SetEnvIfNoCase User-Agent "^spider" search_bot
SetEnvIfNoCase User-Agent "^Robot" search_bot
SetEnvIfNoCase User-Agent "^php" search_bot
SetEnvIfNoCase User-Agent "^Mail" search_bot
SetEnvIfNoCase User-Agent "^bot" search_bot
SetEnvIfNoCase User-Agent "^igdeSpyder" search_bot
SetEnvIfNoCase User-Agent "^Snapbot" search_bot
SetEnvIfNoCase User-Agent "^WordPress" search_bot
SetEnvIfNoCase User-Agent "^BlogPulseLive" search_bot
SetEnvIfNoCase User-Agent "^Parser" search_bot
Deny from env=search_bot
Запрет на файл primer.html для трех основных поисковиков Google, Yandex и Yahoo
SetEnvIfNoCase User-Agent "^Googlebot" search_bot
SetEnvIfNoCase User-Agent "^Yandex" search_bot
SetEnvIfNoCase User-Agent "^Yahoo" search_bot
Deny from env=search_bot
Надеюсь вам пригодиться данная информация, у меня ушло очень много времени, чтобы разобрать как запрещать доступ к файлам через переменную в .htaccess
Кстати точно также можно запретить и доступ с определенного ip.
Для этого нужно записать
SetEnvIfNoCase Remote_Addr 123.123.123.123 search_bot