Содержание
Сегодня автоматизация в тренде — что ни день, то появляются статьи о замене рабочих на роботов. Однако этот процесс гораздо раньше начался в интернете, где каждый второй сайт встречает пользователя окном онлайн-консультанта. Многие думают, что с ними на связи находится живой человек, но это не так. Чаще всего это чат-бот — специальная программа, имитирующая живого человека. Она, в отличие от оператора-человека, не ест, не пьет и работает круглосуточно. Правда, чтобы от такого чат-бота была реальная польза бизнесу, для него нужно написать правильный текст.
Знакомьтесь, текстовый робот
Как уже было сказано, чат-бот — это специализированная программа. Вы их много раз встречали на сайтах и даже могли с ними разговаривать. Да-да, всем известные Сири, Алекса и Алиса — не что иное, как чат-боты, только умеющие произносить текст. Внутреннее устройство таких программ нам не так интересно, как текстовая часть, которая и является основой для их работы.
Если вы подумали, что чат-боты умеют понимать человеческую речь, то спешу вас разочаровать. Максимум, на что они способны, — это выделить из сообщения пользователя ключевые слова и найти подходящий ответ в своей базе данных. А чтобы нам казалось, что программа действительно поддерживает с нами диалог, для нее нужно написать хороший сценарий.
Учим чат-бота разговаривать
Уверен, многие из вас сталкивались с людьми, которые совершенно не умеют вести диалог. Они отвечают невпопад, игнорируют вопросы или несут откровенную чушь. Чтобы добиться от такого человека конкретики, нужно направлять беседу, задавать четкие вопросы и периодически переспрашивать, правильно ли вы поняли собеседника. Все эти правила применимы и к чат-ботам, правда, с некоторыми нюансами.
Поздоровайтесь правильно
Любой диалог начинается с приветствия, но в случае с чат-ботом просто сказать «Здравствуйте» и представиться недостаточно. Приведу простой пример. Представьте, что вы попали на сайт прачечной и увидели в нижнем правому углу сообщение:
Здравствуйте! Вас приветствует прачечная «Чистюля»!
Уверен, большинство из нас после такого сообщения просто закроет окно мессенджера. Но не потому, что нам не нравится эта прачечная или нам не нужна помощь онлайн-консультанта. Дело в том, что мы просто не поняли, что делать дальше: мы не имеем представления о том, что именно этот чат-бот умеет, потому продолжаем пользоваться привычным интерфейсом. Но если бы робот поприветствовал нас правильно, все могло бы сложиться иначе.
Здравствуйте! Прачечная «Чистюля» может отстирать практически любые загрязнения. Что именно у вас испачкалось?
Теперь нам сразу стало понятно, что этот бот умеет: он может подсказать, стоит ли в эту прачечную нести именно ту вещь, которая у нас испачкалась, или нет.
Будьте проще
Не стоит писать для чат-бота длинные реплики. Помните, что пользователь будет их видеть на небольшом экране, напоминающем окно мессенджера. Длинные монологи нужно будет прокручивать вверх-вниз, что очень неудобно. Если же вы делаете речь для голосового помощника, то человек к концу длинной фразы просто забудет то, что ему говорили в начале.
Чат-бот должен отвечать кратко и четко. Для этого придется поработать над формулировками, но только в этом случае вы получите нужный результат.
Научите бота манерам
Речь, конечно же, не о правилах вежливости. Ваш текстовый робот должен разговаривать соответственно той услуге, для которой он предназначен. Например, если чат-бот призван подсказывать пользователю меню в кафе, то он может разговаривать более свободно и даже использовать молодежный сленг. Если же это чат-бот на сайте юридической фирмы, помогающий пользователю ориентироваться в разделах законодательства, то он должен говорить исключительно строгим языком.
Но при том, что чат-бот должен имитировать разную речь, он никогда не должен пытаться выдавать себя за человека. Живой собеседник рано или поздно поймет, что общается с программой и воспримет такое притворство как обман. Пусть ваш чат-бот сразу признается в своей сущности, это только сыграет ему на руку, так как даст больше возможностей для использования юмора, о необходимости которого расскажем чуть позже.
Сделайте чат-бота живым
Внимательный читатель сейчас должен заметить противоречие. В прошлом абзаце я писал о том, что ни в коем случае нельзя изображать из чат-бота живого человека, а теперь предлагаю ему именно этим и заняться. Но это не ошибка.
Дело в том, что чат-бота нужно воспринимать не как живого человека, а как некого персонажа. Играя в компьютерные игры или смотря фильмы, мы отчетливо понимаем, что перед нами выдуманные герои, но при этом у каждого из них есть свой характер и ведут они себя как живые. То же нужно сделать и с чат-ботом.
Пользователю будет гораздо интереснее общаться с роботом, у которого есть характер. Чтобы его создать, нужно придумать ему какие-то особые слова и заставить реагировать определенным образом на определенные вопросы. Это поможет вызвать эмоциональный отклик у пользователя и настроить его более дружелюбно. Все же не каждый день современный человек общается с роботами.
В этом вопросе как раз поможет юмор. Он особенно полезен, когда чат-бот не может обработать запрос пользователя. Сравните два варианта ответа:
«Ой, эту информацию люди от меня скрывают. Давайте я лучше расскажу вам об услугах нашей компании».
Однако не стоит увлекаться написанием «развлекательных» сценариев, в которых чат-бот будет остроумно отвечать на нетипичные вопросы пользователя. Помните, он предназначен совсем для другого.
Поставьте цель
Чат-бот или голосовой помощник — это программа, призванная решать бизнес-задачи. Следовательно, сценарий общения нужно писать соответственным образом. Причем каждый сценарий должен решать одну задачу.
Например, вы хотите, чтобы чат-бот помогал посетителю забронировать столик в кафе. В этом случае возможен следующий диалог:
ЧАТ-БОТ: Здравствуйте! Вам помочь забронировать столик?
ПОЛЬЗОВАТЕЛЬ: Да.
ЧАТ-БОТ: С радостью помогу. Уже выбрали дату?
ПОЛЬЗОВАТЕЛЬ: Нет.
ЧАТ-БОТ: Тогда можете выбрать любую, начиная с завтрашнего дня. У нас есть свободные места в любой день.
ПОЛЬЗОВАТЕЛЬ: Пятница.
ЧАТ-БОТ: Пятница, 11 января 2019 года. Верно?
ПОЛЬЗОВАТЕЛЬ: Да.
ЧАТ-БОТ: Отлично! Вам нужен большой столик или маленький?
ПОЛЬЗОВАТЕЛЬ: Большой.
ЧАТ-БОТ: Готово! Я забронировал для Вас большой столик на пятницу 11 января. Оставьте, пожалуйста, свой телефон, чтобы мой коллега-человек мог Вам позвонить и подтвердить бронь.
ПОЛЬЗОВАТЕЛЬ: 89101234567
ЧАТ-БОТ: Большое спасибо! Уверен, вам у нас понравится.
Обратите внимание, чат-бот почти всегда заканчивает свою реплику вопросом. Таким образом он дает направление беседе и подсказывает пользователю, каких именно действий от него ждут. Конечно же, пользователь далеко не всегда будет отвечать положительно. Поэтому сценарий диалога должен подразумевать ветвление, но в текстовом редакторе его реализовать будет не так-то просто. Для этого лучше использовать другие приложения, напроимен, программы для построения схем или ментальных карт. Приведенный выше диалог можно наглядно представить следующим образом.
Не пропустите будущее
Технология голосовых интерфейсов и чат-ботов только в начале своего пути, но я уверен, что она будет стремительно развиваться. Это значит только одно — совсем скоро возникнет большой спрос на специалистов, которые будут уметь писать сценарии для таких программ. Думаю, самое время этим заняться, ведь у первых всегда есть преимущество.
В этой статье расскажу и покажу как устроен мой чат-бот. Приведу ссылку на структуру чат-бота. Объясню основные принципы, которыми руководствуюсь при создании.
Чат-бот создан для следующих целей:
- сбор базы для рассылки,
- определение аудитории для ретаргетинга,
- сбор базы потенциальных клиентов.
- отдает полезный контент из блога в обмен на емайл-адрес пользователя,
- выгружает полученные данные в CRM,
- предлагает подписаться на рассылку,
- сегментирует пользователя по степени удовлетворенности контентом и лояльности.
Роль чат-бота в отношениях с клиентом – первое касание, калибровка клиента и отсев нецелевых. На каждом участке общения отмечаются качества пользователя – сегментация по по интересам, лояльности и удовлетворенности, – в конечном счете профиль каждого человека приобретает вид:

Профиль человека в ManyChat:
- Интересует тема продвижения в Facebook/Instagram – тег facebook.
- Зашел с лид-магнита “5 стратегий для лид-магнита” – тег lid-m-fb-subscribe.
- Видимо материал понравился: есть тег подписки на рассылку blog.
- После чего человек просмотрел раздел отзывы – важный индикатор “нагретости” – тег review.
- И сделал ряд шагов для заказа продукта. По сути готовый лид. Подогретый и желающий купить. Тег sale.
- Для контакта есть три способа:
- написать письмо на емайл,
- открыть чат в Facebook Messenger,
- сделать последовательность сообщений Sequences – если совсем ленивые и хотим, чтобы он сам купил продукт, например трипваер.
Кол-во данных можно увеличить, со временем добавляются новые теги, формируются дополнительные черты профиля.
Планируем
Прежде чем создать чат-бот, надо определить две вещи:
6 шагов для продвижения без бюджета
- место в воронке продаж,
- задачи, что хотим получить в итоге.
Я не пользуюсь телефонными звонками, заменяю их на Facebook Messenger. Поэтому собираю только емайл для таргетинга рекламы и возможной переписке с клиентом. По этой же причине сразу информирую, что емайлы использую только для CRM и никакого спама. Рассылку (broadcasting) делаю в чат-боте и только при условии прямого согласия пользователя. Опытным путем определил, что это самый эффективный путь.
Все выше описанное дает исходные потребности: забрать емайл и пригласить подписаться на рассылку.

Подробная версия картинки по ссылке: bit.ly/chatbot-shema-full
Отмечу ряд моментов:
- Начинаем с рекламы. Очень важно в рекламном сообщение задать правильный эмоциональный и информационный посыл, что и для кого предлагаем. Сделать предупреждение, что общение проводит чат-бот, что с пользователя потребуют емайл-адрес. Это снижает кол-во тех, кто вошел в диалог, но не оставил емайл или затормозил на первом сообщении.
- Однозначность прочтения. Принимай условия или уходи. В первом же сообщении предлагаю забрать полезный классный контент – или уйти прочь. Одна кнопка “Забрать” и все. На первом этапе отсеиваем не целевых, тех, кто не умеет читать и не понимает куда попал.
- Продаются эмоции. Это относится к использованию смайлов, которые создают эмоциональный фон. Надо четко понимать, какие эмоции транслируем и почему.
- Тестируем. Любой чат-бот постоянно эволюционирует. Анализирует диалоги, ищем более совершенные формы коммуникации, построение и формирование фраз. Стараемся уложиться в минимум реплик.
Кстати про рекламу. Обычно рекламирую через сообщения – рекламная кампания на Сообщения. Пробовал через ссылки и через вовлеченность (комментарии), но пока результат не такой хороший как через сообщения.

И естественно через JSON. Это самый удобный формат. Позволяет редактировать чат-бот – за исключением первого сообщения – в процессе рекламной кампании.

Создаем несколько вариантов рекламы и аудиторий, тестируем, определяем лучший.
Но вернемся к схеме. Чат-бот можно создавать на разных платформах, но схема остается примерно одинаковая. В этом польза предварительного планирования. Вот так выглядит схема текущего проекта:
![]()
Естественно в процессе работы будут вноситься правки и коррективы. Тестирование добавит еще изменений и конечная рабочая версия будет довольно сильно отличаться от плана в деталях, но сохранит общую идею: лид-магнит, группа Фейсбук, акцент на сбор номеров телефонов.
Как сделать
Работаю только с Facebook, поэтому создаю в сервисе ManyChat. Использую платную версию – от $10/month. Сервис дает большое кол-во вариантов для привлечения пользователей. Нас прежде всего
интересует Facebook Ads JSON, который только в платной версии.

В разделе Flow создаем поток. В вашем случае смотрим готовый и копируем.
Если вы пользователи ManyChat, то это победа: копируете в аккаунт и работайте.
Разберем составные части потока:
- Первое сообщение. Простое, короткое с одной кнопкой. Формат JSON накладывает технические ограничения на размер текста и возможности по Action. Поэтому используем как короткий тизер, приглашение нажать кнопку. Принцип: жми или проходи мимо.
- Сразу тег. Как только пользователь выразил согласие и нажал кнопку, получает тег отметку своей области интереса.
- Скрытая развилка. Если пользователь повторно заходит в поток и уже оставлял емайл-адрес, то даем короткую версию потока – сразу контент. Экономим время и силы пользователя.
- Забираем данные. Вторым этапом обязательно запрашиваем контактные данные и выгружаем в CRM. Чем меньше полей спросим, тем больше вероятности, что их заполнят. Я использую только емайл.
- Второй тег. Если пользователь оставил данные, значит проявил интерес и хочет получить наш контент. Отмечаем вид контента.
- Ссылка на контент с предупреждением об опросе. Последнюю часть ввел недавно. Показалось, что это повышает кол-во людей, которые отвечают опрос и высказывают желание подписаться на рассылку.
- Иногда жалуются, что ссылка не работает. Не понял в чем проблема: то ли маничат глючит, то ли телефон пользователя. В этом случаем отправляю прямую ссылку, что тоже не всегда помогает.
- Иногда люди подписываются на рассылку уже в блоге через виджет. Или находят в меню чат-бота. Это нормально и даже хорошо.
- Некоторые пишут в чат-бот, что хотят подписаться на рассылку. Вносим в список рассылки вручную: ставим соответствующий тег.
- Пауза. Используем умную паузу. На 18 часов и только в рабочее время, но это еще предмет эксперимента. Мне показалось этичным делать опрос в рабочее время, чтобы лишний раз не дергать пользователя, дать возможность прочитать и усвоить материал.
- Опрос. Простая фраза с ответом да или нет. Открытая развилка. Понравилось или нет?
- Иногда люди отвечают, что еще не прочитали. Этот ответ еще не придумал как обработать. Но как минимум опрос подталкивает вернуться к прочтению.
- Если не понравилось, высказываем сожаление и – третий тег! Обозначаем негативное отношение к контенту.
- Если понравилось, то выдаем скрытую развилку. Пользователь в базе рассылки? Да – благодарим за внимание и обещаем порадовать еще. Нет – предлагаем подписаться на рассылку.
Вот и все, ничего сверхъестественного нет.
Варианты улучшения (пришли в голову, пока писал статью):
- Убрать последнюю явную развилку для тех, кому понравилось. Просто кнопка подписаться на рассылку – так меньше диалогов.
- Сделать опрос негативщиков. Если человеку не понравился контент, узнать что именно и как улучшить.
- В первом сообщении картинка. Добавить яркости первому сообщение, больше завлекающих эмоций.
- Сделать анонс блога в приглашении подписаться. Показать галерею с анонсами другим материалов блога с приглашением подписаться или прочитать.
Вообщем, есть над чем поработать. 🙂
Немного про цифры
Проблему сквозной аналитики обозначил, поэтому текущие цифры весьма условные и подсчитывались вручную.
- стоимость подписки на чат-бот – меньше 15 р
- стоимость подтвержденной подписки на рассылку блога – больше 60 р*
*Считалось вручную. Потому что подписываются: в блоге, через повторный контакт с чат-ботом, через меню чат-бота. С аналитикой надо еще поработать.

Есть данные и о более низкой стоимости вовлечения в переписку. Много зависит от аудитории, ниши, качества оффера.
Можно не запрашивать разрешение на рассылку. Делать как обычно: рассылать всем, кто написал, принял участие в диалоге с чат-ботом. Вроде даже не сильно отписываются. Поначалу. Но анализ тренда на более менее длительном промежутке показывает:
- падение открываемость – очень четкий тренд;
- кол-во подписантов не дают продаж.
Поэтому сейчас остановился на варианте меньше, но лучше. Крайне осторожно сегментировать аудиторию рассылки. Лучше 100 человек, но потенциальных клиентов.
Емайл-рассылка. Я не использую. Но в принципе, сбор базы рассылки без Opt-In – те же 15-20 р. Не все люди оставляют емайл-адрес. Если планируете использовать именно емайл рассылку, то поток надо переделать. Запросить подтверждение подписки и раздавать контент после Opt-In. Но это уже отдельный разговор и отдельный чат-бот.
Заключение
Этот небольшой материал показываем эволюцию от создания чат-бота к мессенджер-маркетингу. Думаю каждый, кто использует чат-бот, поневоле вынужден пройти этот путь: от потока коммуникаций до осознания потребностей мессенджер-маркетинга. Качество рекламы, стоимость трафика, конечная стоимость лида, срок жизни подписчика – это лишь некоторые вопросы, которые начинают вставать при использовании бота.
На этом пути постараюсь помочь. Поэтому мне важны ваши вопросы и комментарии
Ниже анонс прямой трансляции, где можно задать вопросы в прямом эфире. Либо готовая видеотрансляция, если вы читаете статью после вебинара.
Если хотите получать уведомления о будущих вебинарах, то подписывайтесь на блог (виджет сверху или меню в онлайн-чате) и на мою страницу в Facebook. Подписчики получают все анонсы первыми. Активные участники приглашаются в закрытую группу Бизон.
Послесловие
Как все началось? Как появилась идея этого бота?
Началось с банального: возникла потребность личного продвижения. Выстраивал стратегию продвижения для самого себя и осознал ограниченность личных ресурсов. А еще потребности экспериментировать и делиться контентом. Возникла идея: как сделать так, чтобы каждая единица контента в блоге работала на воронку продаж? Чтобы публиковать контент в блоге и через него получать подписчиков, выстраивать воронку продаж.
В материале про схемы лид-магнитов описывал разные схемы. Самая простая – с чат-ботом. Мои эксперименты с рекламой показывали низкую стоимость вовлечения в сообщения. Да и схема выглядела простой.
Это было в октябре 2018. Тогда еще не знал, что мнимая “сказочная” эффективность чат-бота имеет много подводных камней и условий. Даже сейчас, спустя несколько месяцев, постоянно нахожу точки улучшения. И что самое обидное, очень мало серьезных материалов. В лучшем случае англоязычные. Ну еще различные курсы, где продают магию и рассказывают про сверхъестественную “открываемость рассылки” в мессенджере.
Как бы там ни было, задачу выполнил. Чат-бот стал надежным инструментом-связкой для первого касания с пользователем. Хорошо работает в промежутке между рекламой и контентом.
Это только первый шаг в освоении Мессенджер-Маркетинга. Впереди много идеи и областей применения. Например остро стоит вопрос аналитики: как выгружать данные для отслеживания события? Довольно сложная тема. Но уже есть наработки и в следующем году постараюсь раскрыть.
Еще интересная тема – связка рекламы и чат-бота. По идее каждый сегмент аудитории бота можно использовать для таргетинга рекламы. Даже если человек отказался подписываться на рассылку, то остается в базе и можно подогревать рекламой. Это дает интересные варианты для связки чат-бота и воронки продаж.

Несколько лет назад было опубликовано интервью, в котором говорят об искусственном интеллекте и, в частности, о чат-ботах. Респондент подчеркивает, что чат-боты не общаются, а имитирует общение.
В них заложено ядро разумных микродиалогов вполне человеческого уровня и построен коммуникативный алгоритм постоянного сведения разговора к этому ядру. Только и всего.
На мой взгляд, в этом что-то есть…
Тем не менее, о чат-ботах много говорят на Хабре. Они могут быть самые разные. Популярностью пользуются боты на базе нейронных сетей прогнозирования, которые генерируют ответ пословно. Это очень интересно, но затратно с точки зрения реализации, особенно для русского языка из-за большого количества словоформ. Мной был выбран другой подход для реализации чат-бота Boltoon.
Boltoon работает по принципу выбора наиболее семантически близкого ответа из предложенной базы данных с последующей обработкой. Этот подход имеет ряд преимуществ:
- Быстрота работы;
- Чат-бот можно использовать для разных задач, для этого нужно загрузить новую базу;
- Боту не требуется дообучение после обновления базы.
Есть база данных с вопросами и ответами на них.

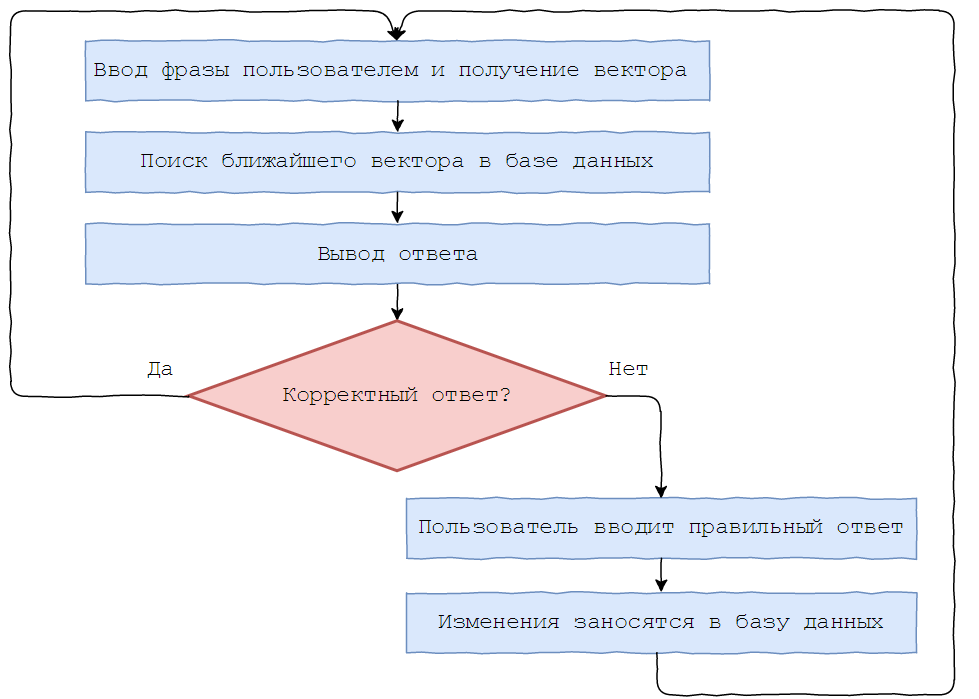
Необходимо, чтобы бот хорошо распознавал смысл введенных фраз и находил похожие в базе. Например, «как дела?», «как ты?», «как дела у тебя?» значат одно и то же. Т.к. компьютер хорошо работает с числами, а не с буквами, поиск соответствий между введенной фразой и имеющимися нужно свести к сравнению чисел. Требуется перевести всю колонку с вопросами из базы данных в числа, вернее, в векторы из N действительных чисел. Так все документы получат координаты в N-мерном пространстве. Представить его затруднительно, но можно снизить размерность пространства до 2 для наглядности.

В том же пространстве находим координату введенной пользователем фразы, сравниваем ее с имеющимися по косинусной метрике и находим ближайшую. На такой простой идее основан Boltoon.
Теперь обо всем по порядку и более формальным языком. Введем понятие «векторное представление текста» (word embeddings) – отображение  слова из естественного языка в вектор фиксированной длины (обычно от 100 до 500 измерений, чем выше это значение, тем представление точнее, но сложнее его вычислить).
слова из естественного языка в вектор фиксированной длины (обычно от 100 до 500 измерений, чем выше это значение, тем представление точнее, но сложнее его вычислить).
Например, слова «наука», «книга» могут иметь следующее представление:
На Хабре уже писали об этом (подробно можно почитать здесь). Для данной задачи более всего подходит распределенная модель представления текста. Представим, что есть некое «пространство смыслов» — N-мерная сфера, в которой каждое слово, предложение или абзац будут точкой. Вопрос в том, как его построить?
В 2013 году появилась статья «Efficient Estimation of Word Representations in Vector Space», автор Томас Миколов, в которой он говорит о word2vec. Это набор алгоритмов для нахождения распределенного представления слов. Так каждое слово переводится в точку в некотором семантическом пространстве, причем алгебраические операции в этом пространстве соответствуют операциям над смыслом слов (поэтому используют слово семантическое).
На картинке отображено это очень важное свойство пространства на примере вектора «женственности». Если от вектора слова «король» вычесть вектор слова «мужчина» и прибавить вектор слова «женщина», то получим «королеву». Больше примеров Вы можете найти в лекциях Яндекса, также там представлено объяснение работы word2vec «для людей», без особой математики.

На Python это выглядит примерно так (потребуется установить пакет gensim).
Здесь используется уже построенная модель word2vec проектом Russian Distributional Thesaurus
Подробнее рассмотрим ближайшие к «королю» слова. Существует ресурс для поиска семантически связанных слов, результат выводится в виде эго-сети. Ниже представлены 20 ближайших соседей для слова «король».

Модель, которую предложил Миколов очень проста – предполагается, что слова, находящиеся в схожих контекстах, могут значить одно и то же. Рассмотрим архитектуру нейронной сети.
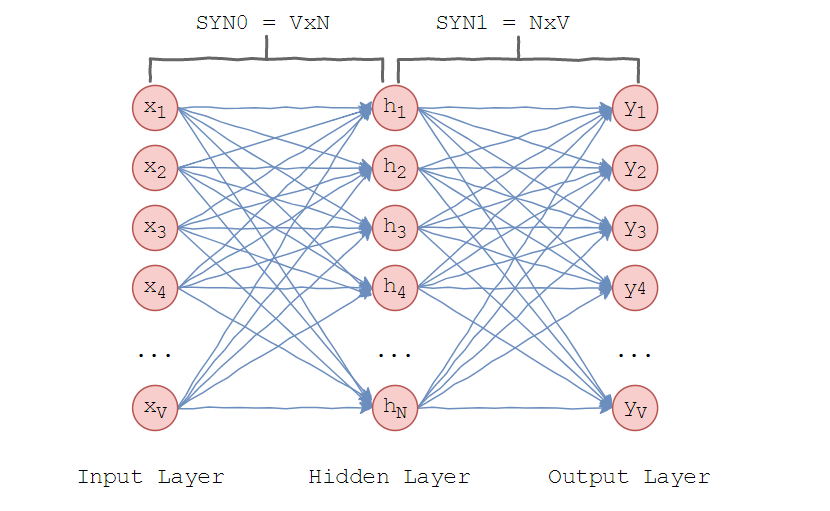
Word2vec использует один скрытый слой. Во входном слое установлено столько нейронов, сколько слов в словаре. Размер скрытого слоя – размерность пространства. Размер выходного слоя такой же, как входного. Таким образом, считая, что словарь для обучения состоит из V слов и N размерность векторов слов, веса между входным и скрытым слоем образуют матрицу SYN0 размера V×N. Она представляет собой следующее.

Каждая из V строк является векторным N-мерным представлением слова.

Аналогично, веса между скрытым и выходным слоем образуют матрицу SYN1 размера N×V. Тогда на входе выходного слоя будет:

где  – j-ый столбец матрицы SYN1.
– j-ый столбец матрицы SYN1.
Скалярное произведение – косинус угла между двумя точками в n-мерном пространстве. И эта формула показывает, как близко находятся векторы слов. Если слова противоположные, то это значение -1. Затем используем softmax – «функцию мягкого максимума», чтобы получить распределение слов.

С помощью softmax word2vec максимизирует косинусную меру между векторами слов, которые встречаются рядом и минимизирует, если не встречаются. Это и есть выход нейронной сети.
Чтобы лучше понять, как работает алгоритм, рассмотрим корпус для обучения, состоящий из следующих предложений:
«Кот увидел собаку»,
«Кот преследовал собаку»,
«Белый кот взобрался на дерево».
Словарь корпуса содержит восемь слов: [«белый», «взобрался», «дерево», «кот», «на», «преследовал», «собаку», «увидел»]
После сортировки в алфавитном порядке на каждое слово можно ссылаться по его индексу в словаре. В этом примере нейронная сеть будет иметь восемь входных и выходных нейронов. Пусть будет три нейрона в скрытом слое. Это означает, что SYN0 и SYN1 будут соответственно 8×3 и 3×8 матрицами. Перед началом обучения эти матрицы инициализируются небольшими случайными значениями, как это обычно бывает при обучении. Пусть SYN0 и SYN1 инициализированы так:
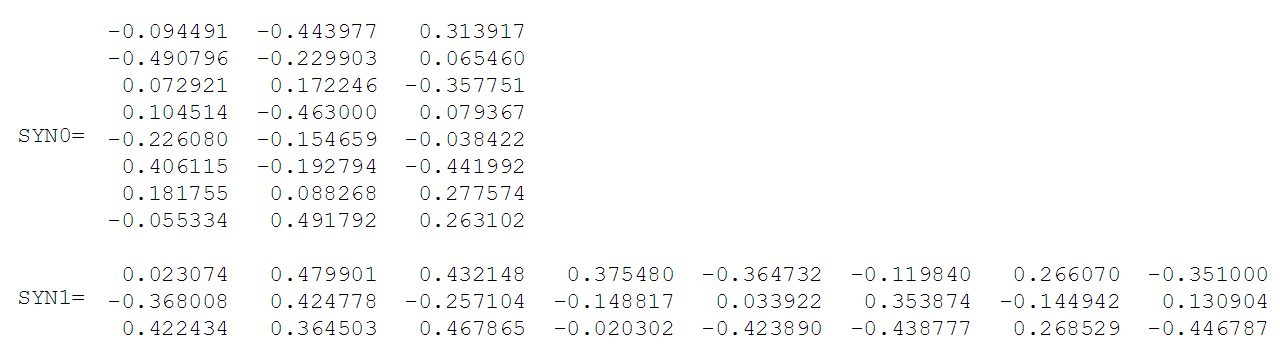
Предположим, нейронная сеть должна найти отношение между словами «взобрался» и «кот». То есть, сеть должна показывать высокую вероятность слова «кот», когда «взобрался» подается на вход сети. В терминологии компьютерной лингвистики слово «кот» называется центральное, а слово «взобрался» — контекстное.

В этом случае входной вектор X будет  (потому что «взобрался» находится вторым в словаре). Вектор слова «кот» —
(потому что «взобрался» находится вторым в словаре). Вектор слова «кот» —  .
.
При подаче на вход сети вектора, представляющего «взобрался», вывод на нейронах скрытого слоя можно вычислить так:

Обратите внимание, что вектор H скрытого слоя равен второй строке матрицы SYN0. Таким образом, функция активации для скрытого слоя – это копирование вектора входного слова в скрытый слой.
Аналогично для выходного слоя:

Нужно получить вероятности слов на выходном слое,  для
для  , которые отражают отношение центрального слова с контекстным на входе. Для отображения вектора в вероятность, используют softmax. Выход j-го нейрона вычисляется следующим выражением:
, которые отражают отношение центрального слова с контекстным на входе. Для отображения вектора в вероятность, используют softmax. Выход j-го нейрона вычисляется следующим выражением:
Таким образом вероятности для восьми слов в корпусе равны: [0,143073 0,094925 0,114441 0,111166 0,14492 0,122874 0,119431 0,1448800], вероятность «кота» равна 0,111166 (по индексу в словаре).
Так мы сопоставили каждому слову вектор. Но нам нужно работать не со словами, а со словосочетаниями или с целыми предложениями, т.к. люди общаются именно так. Для это существует Doc2vec (изначально Paragraph Vector) – алгоритм, который получает распределенное представление для частей текстов, основанный на word2vec. Тексты могут быть любой длины: от словосочетания до абзацев. И очень важно, что на выходе получаем вектор фиксированной длины.
На этой технологии основан Boltoon. Сначала мы строим 300-мерное семантическое пространство (как упоминалось выше, выбирают размерность от 100 до 500) на основе русскоязычной Википедии (ссылка на дамп).
Еще немного Python.
Создаем экземпляр класса для последующего обучения с параметрами:
- min_count: минимальная частота появления слова, если частота ниже заданной – игнорировать
- window: «окно», в котором рассматривается контекст
- size: размерность вектора (пространства)
- sample: максимальная частота появления слова, если частота выше заданной – игнорировать
- workers: количество потоков
Строим таблицу словарей. Documents – дамп Википедии.
Обучение. total_examples – количество документов на вход. Обучение проходит один раз. Это ресурсоемкий процесс, строим модель из 50 МБ дампа Википедии (мой ноутбук с 8 ГБ RAM больше не потянул). Далее сохраняем обученную модель, получая эти файлы.

Как упоминалось выше, SYN0 и SYN1 – матрицы весов, образованные во время обучения. Эти объекты сохранены в отдельные файлы с помощью pickle. Их размер пропорционален N×V×W, где N – размерность вектора, V – количество слов в словаре, W – вес одного символа. Из этого получился такой большой размер файлов.
Возвращаемся к базе данные с вопросами и ответами. Находим координаты всех фраз в только что построенном пространстве. Получается, что с расширением базы данных не придется переучивать систему, достаточно учитывать добавленные фразы и находить их координаты в том же пространстве. Это и есть основное достоинство Boltoon’а – быстрая адаптация к обновлению данных.
Теперь поговорим об обратной связи с пользователем. Найдем координату вопроса в пространстве и ближайшую к нему фразу, имеющуюся в базе данных. Но здесь возникает проблема поиска ближайшей точки к заданной в N-мерном пространстве. Предлагаю использовать KD-Tree (подробнее о нем можно почитать здесь).
KD-Tree (K-мерное дерево) – структура данных, которая позволяет разбить K-мерное пространство на пространства меньшей размерности посредством отсечения гиперплоскостями.
Но оно имеет существенный недостаток: при добавлении элемента перестройка дерева осуществляется за O(NlogN) в среднем, что долго. Поэтому Boltoon использует «ленивое» обновление — перестраивает дерево каждые M добавлений фраз в базу данных. Поиск происходит за O(logN).
Для дообучения Boltoon’a был введен следующий функционал: после получения вопроса отправляется ответ с двумя кнопками для оценки качества.

В случае отрицательного ответа, пользователю предлагается скорректировать его, и исправленный результат заносится в базу данных.

Пример диалога с Boltoon’ом с использованием фраз, которых нет в базе данных.