Содержание
Древовидные структуры не относятся напрямую к программированию баз данных, тем не менее, программисту нередко приходится "изобретать велосипед", придумывая различные решения сохранения таких структур в таблице, и обратное их считывание в дерево .
Типичный пример дерева – всем знакомое дерево каталогов. Примеров таких структур множество – это могут быть отделы в каком-либо учреждении или разделы библиотеки. Посмотрим на рисунок с фрагментом дерева разделов библиотеки:

Основная сложность хранения деревьев в таблице – это то, что мы не знаем заранее, какова будет глубина вложенности разделов. Можно было бы создать таблицу с 10 полями, например. Но если вложенных разделов будет меньше, то таблица будет неэффективна – останется много пустых полей. А если больше – ограничивать пользователя?
Самый простой способ сохранения структуры дерева и ее считывания обратно – воспользоваться тем, что дерево – это список узлов, и имеет хорошо знакомые нам методы:
Однако этот способ имеет массу недостатков. Во-первых, в результате получим простой текстовый файл , в котором вложенные узлы располагаются ниже родителя и имеют отступ . Пользователь легко может случайно или намеренно испортить такой файл , отредактировав или просто удалив его с диска, и программа будет работать с ошибками. Во-вторых, обычно древовидная структура тесно связана с другими данными, например, таблица отделов предприятия связана со служащими этого предприятия – запись каждого служащего имеет ссылку на отдел, где он работает. Если структуру предприятия хранить в простом текстовом файле, то такую связь сложно будет обеспечить.
Когда программист впервые сталкивается с необходимостью хранения древовидных структур в базе данных, обычно он первым делом подключается к Интернету и ищет какой-нибудь компонент , который бы позволил это делать. Но не все нестандартные компоненты работают качественно, да и зачем искать какой-то новый компонент , когда имеется стандартный TreeView на вкладке Win32 Палитры компонентов ? Именно с этим компонентом мы и будем работать в данной лекции.
Рецептов работы с деревьями в базах данных много, мы рассмотрим лишь один из них, достаточно эффективный и в то же время простой. Смысл этого способа состоит в том, чтобы в каждой записи таблицы сохранять номер узла раздела, номер его родителя, если он есть, и название узла. В случае если узел не имеет родителя (главный узел, например, "Художественная литература" в рисунке 10.1), то в соответствующее поле запишем ноль.
Подготовка проекта
Для реализации примера нам потребуется новая база данных . Загрузите MS Access и создайте базу данных " TreeBD ", а в ней таблицу " Razdels ". Вообще-то, в базе данных MS Access как таблицы, так и поля могут иметь русские названия, однако мы будем использовать средства SQL , который не всегда корректно обрабатывает русские идентификаторы. Кроме того, данный способ можно использовать в любой СУБД , а далеко не все из них так предупредительны, как MS Access , поэтому название таблицы и ее полей выполним латиницей.
Таблица будет иметь три поля:
| № | Имя поля | Тип поля | Дополнение |
|---|---|---|---|
| 1 | R_Num | Счетчик | Ключевое поле |
| 2 | R_ Parent | Числовой | Целое |
| 3 | R_Name | Текстовый | Длина 50 символов |
Созданную базу данных сохраните в папке, где будем разрабатывать наш проект (не забудьте сделать резервную копию пустой базы данных на всякий случай.).
Далее создадим в Delphi новый проект и простую форму:

Как всегда, назовите форму fMain , в свойстве Caption напишите "Реализация сохранения дерева в БД ", модуль формы сохраните как Main , а проект в целом назовите, например, TreeToBD . Сделанная база данных TreeBD должна быть в той же папке, что и проект.
Далее установите компонент TreeView ( дерево ) с вкладки Win32. Его свойству Align присвойте alLeft, чтобы дерево заняло весь левый край. Затем можете установить сплиттер – разделитель, ухватившись за который пользователь сможет менять ширину дерева. Компонент Splitter находится на вкладке Additional и его свойство Align по умолчанию равно alLeft – разделитель "прилепится" к правому краю дерева.
Правее установите сетку DBGr >место . Ни главное меню , ни панель инструментов нам здесь не потребуются, используем лишь два всплывающих PopupMenu – первый для дерева, второй для сетки (выберите соответствующие PopupMenu в свойстве PopupMenu этих компонентов).
Далее с вкладки ADO нам потребуется компонент ADOConnection для соединения с базой данных, таблица ADOTable и запрос ADOQuery для вспомогательных нужд. С вкладки Data Access – компонент DataSource, для связи сетки с таблицей. Подключите ADOConnection к базе данных и откройте соединение ( "ADO. Связь с таблицей MS Access" ). Таблицу подключите к ADOConnection (свойство Connection ), затем выберите в свойстве TableName нашу таблицу " Razdels ", а свойство Name переименуйте в tRazdels – так будем обращаться к таблице. Для удобства отображения названия полей откройте редактор полей таблицы (дважды щелкнув по ней), добавьте все поля и у каждого поля измените свойство DisplayLabel, соответственно, на "№", "Родитель" и "Название". Не забудьте открыть таблицу.
Компонент DataSource подключите к tRazdels , а сетку – к DataSource, в сетке должны отобразиться поля. Кроме того, переименуйте свойство Name запроса ADOQuery1 в Q1, ведь нам часто придется обращаться к нему по имени. Запрос также подключите к ADOConnection, но делать его активным не нужно.
На этом приготовления закончены.
Создание и сохранение в таблицу дерева разделов
Работа с деревьями состоит из двух этапов:
- Сохранение дерева в таблицу.
- Считывание дерева из таблицы.
В этом разделе лекции разберем первый этап. Щелкните дважды по компоненту PopupMenu1, который "привязан" к дереву, и создайте в нем следующие разделы :
- Создать главный раздел
- Добавить подраздел к выделенному
- Переименовать выделенный
- Удалить выделенный
- –
- Свернуть дерево
- Развернуть дерево
Все эти команды относятся к работе с разделами дерева. Прежде всего, создадим обработчик для команды "Создать главный раздел". Листинг процедуры смотрите ниже:
Разберем код. Переменная NewRazd имеет тип TTreeNode , к которому относятся все разделы и подразделы (узлы) дерева. В текстовую переменную s с помощью функции InputQuery() мы получаем имя нового главного узла. Функция имеет три строковых параметра:
- Заголовок окна.
- Пояснительная строка.
- Переменная, куда будет записан введенный пользователем текст.
Если переменная , передаваемая в качестве третьего параметра, пуста, то поле ввода будет пустым. Если же в ней содержался текст – он будет выведен как текст "по умолчанию". Функция возвращает True, если пользователь ввел (или изменил) текст, и False в противном случае. В результате работы функции для пользователя будет выведено простое окно с запросом:
мы снимаем выделение, если какой либо раздел был выделен, ведь мы создаем главный раздел, не имеющий родителя. Свойство Selected компонента TreeView указывает на выделенный узел и позволяет производить с ним различные действия, например, получить текст узла:
А присваиваемое значение nil (ничто) снимает всякое выделение, если таковое было. Далее мы создаем сам узел:
Разберем эту строку подробней. Переменная NewRazd – это новый узел дерева. Каждый узел – объект , обладающий своими свойствами и методами. Все узлы хранятся в списке – свойстве Items дерева TreeView, а метод Add() этого свойства позволяет добавить новый узел. У метода два параметра – выделенный узел (у нас он равен nil ) и строка текста, которая будет присвоена новому узлу. Таким образом, в дереве появляется новый главный узел.
Затем мы сохраняем его в базу данных, предварительно добавив в таблицу новую запись :
Вы помните, что такие методы, как Append или Insert автоматически переводят таблицу в режим редактирования, поэтому вызывать метод Edit излишне?
Обратите внимание на то, что мы сохраняем ноль в поле "R_ Parent ", так как это – главный раздел, не имеющий родителя. Свойство Text нового узла NewRazd содержит название нового узла, которое мы присваиваем полю "R_Name".
Далее сгенерируем процедуру для команды меню "Добавить подраздел к выделенному":
Код этой процедуры очень похож на код предыдущей, но есть и отличия. Прежде всего, мы проверяем – а имеется ли выделенный раздел? Ведь фокус ввода мог быть и на сетке DBGr >пользователь щелкнул правой кнопкой по дереву, и выбрал эту команду. В этом случае, если не делать проверки, мы получим ошибку, пытаясь добавить дочерний узел к пустоте.
Далее, мы ввели строковую переменную z , чтобы сформировать запрос . Ведь пользователю будет удобней, если в окне InputQuery() он сразу увидит, к какому именно разделу он добавляет подраздел.
Затем, при добавлении дочернего узла вместо метода Add() мы используем метод AddChild() .
Ну и, наконец, при сохранении узла в таблицу мы записываем не только созданный узел, но и номер его родителя, получив его с помощью запроса
Запрос формирует набор данных с единственной строкой – записью родителя добавляемого элемента. Поле Q1[‘R_Num’], как вы понимаете, хранит номер этого родителя в запросе.
Код процедуры переименования выделенного раздела выглядит так:
Здесь комментарии достаточно подробны, чтобы вы разобрались с кодом. Следует обратить внимание на то, что вначале мы исправляем запись в таблице, и только потом – в узле. Если бы мы сначала исправили текст узла, как бы затем нашли старую запись в таблице? Пришлось бы вводить дополнительную переменную для хранения старого текста.
Удаляется выделенный узел еще проще:
Далее нам осталось сгенерировать процедуры для сворачивания и разворачивания дерева. Делается это одной строкой:
Итак, метод FullCollapse дерева TreeView сворачивает его узлы, а метод FullExpand разворачивает.
Теперь сохраните проект и скомпилируйте его. Попробуйте заполнить дерево разделами и подразделами, убедитесь, что параллельно данные сохраняются и в таблице.
Кузьменко Дмитрий, iBase.ru

Введение
Используемые инструменты
Таблицы-объекты
Для того, чтобы подойти к построению "деревьев", мы должны рассмотреть, что представляет собой реляционная таблица.

Рис. 1
Однотипные связанные объекты
Предположим что мы действительно хотим создать таблицу "Люди", в которой нужно отслеживать родственные связи типа родитель-потомок. Для простоты представим себе, что у потомков родитель может быть только один (например, "Родитель"):
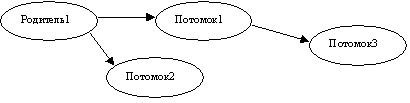
Рис. 2
Для того, чтобы хранить информацию о родителе экземпляра объекта, любой объект в таблице должен помимо идентификатора иметь атрибут "родитель". На рисунке видно, что все "Потомки" имеют родителя, кроме самого "Родитель1". Экземпляр "Родитель1" может в принципе вообще отсутствовать – можно принять что у потомков первого уровня всегда один и тот же родитель, поэтому хранить информацию о нем необязательно (в каких случаях это необходимо, мы рассмотрим дальше).
Читатель может заметить – а как же множественное наследование? А никак. В природе такового не существует – все объекты реального мира являются или цельными, или составными. Множественное наследование было создано только как методика проектирования классов, когда разработчик не обладает полной информацией о самих классах. Автор статьи считает, что множественное наследование только запутывает реализацию прикладной области. Например, в ряде книг приводится случай, когда объект "тесто" получается множественным наследованием объектов "вода" и "мука". На самом деле это не так – даже при диффузии отдельные материалы все равно остаются сами собой, т. е. в данном случае мы имеем совершенно новый объект "тесто", который имеет среди атрибутов указатели на два класса – "тесто" и "вода" (или список составляющих "тесто" классов, как угодно). Характеристики "теста" при этом зависят не только от состава "воды" и "муки", но и от их процентного соотношения. То же самое относится и к биологическому "рождению" – ребенок наследует свойства родителей, т. е. их наборы хромосом, и представляет собой типичный составной объект при отсутствии какого бы то ни было множественного наследования. Конечно, множественное наследование в редких случаях облегчает программирование, однако это не значит, что оно отражает суть реальных вещей, которые можно описать в программе.
Итак, структура нашей "родовитой" таблицы будет выглядеть следующим образом:

Рис. 3
Поле "Родитель" всегда ссылается на значение поля "Идентификатор". Здесь нас поджидает подводный камень – если бы мы решили, что "…ссылается на существующее значение поля…", и в соответствии с реляционными правилами объявили-бы связь конструкцией SQL "alter table … add constraint … foreign key", то попали-бы в замкнутый круг "курица и яйцо". Как создать экземпляр объекта если родителя нет? Действительно, может-ли существовать экземпляр объекта без указания родителя? Чтобы избавиться на начальном этапе хотя-бы от первого вопроса, нужно отказаться от декларации связи Родитель->Идентификатор на уровне сервера. Это снизит защищенность данных, но избавит нас от долгих раздумий в самом начале пути. На второй вопрос (может-ли существовать экземпляр без родителя) можно безболезненно ответить "нет", установив ограничение целостности для поля "Родитель" как "значение обязательно" (NOT NULL).
Поскольку мы отказались от создания FK, по полю "родитель" не будет автоматически построен индекс, который был бы нужен оптимизатору для ускорения запросов, выбирающих группы потомков для конкретного родителя. Не забудьте добавить такой индекс потом, вручную.
Давайте теперь посмотрим, как будет выглядеть таблица, заполненная экземплярами объектов с рисунка 2:
| Идентификатор | Родитель | Остальные атрибуты … |
|---|---|---|
| Родитель1 | . | |
| Потомок1 | Родитель1 | |
| Потомок2 | Родитель1 | |
| Потомок3 | Потомок1 |
Из таблицы видно, что Потомок1 одновременно является и потомком элемента "Родитель1", и родителем элемента "Потомок3".
Такую таблицу можно создать конструкцией SQL:
Пусть идентификаторы экземпляров объектов будут начинаться с номера 1. Тогда родителем экземпляра "Родитель1" можно принять значение 0 (корневой элемент). Фактически экземпляров с родителем = 0 может быть сколько угодно, и именно они будут представлять "корень" нашего дерева. Названия экземпляров пусть находятся в поле "NAME". Пронумеруем идентификаторы экземпляров объектов. В этом случае таблица будет иметь вид
| ID | PARENT | NAME |
|---|---|---|
| 1 | Родитель1 | |
| 2 | 1 | Потомок1 |
| 3 | 1 | Потомок2 |
| 4 | 2 | Потомок3 |
Тогда, чтобы получить из таблицы OBJECTS все корневые элементы, достаточно выполнить запрос
Представить такую информацию можно в виде "каталогов" и "файлов", например, как в Windows Explorer. Щелчок мыши по каталогу приводит к "проваливанию" на более глубокий уровень, и т. д.
Конечно, для того чтобы иметь возможность вернуться назад по дереву нужно в приложении хранить "список возврата", т. е. список элементов, по которым мы углубились внутрь, с идентификаторами их владельцев (своеобразный "стек"). С другой стороны, нужно иметь возможность выбрать весь путь вплоть до корня начиная с произвольного элемента. Это можно сделать написав хранимую процедуру (если ваш SQL-сервер поддерживает стандарт ANSI SQL 3 в части хранимых процедур (PSM) и позволяет из хранимых процедур возвращать наборы записей). Вот как выглядит такая процедура для InterBase:
В процедуру передается идентификатор, с которого нужно подниматься “вверх” по дереву. В цикле, пока идентификатор не стал равным 0 (не поднялись выше корневого элемента) происходит выборка записи с указанным идентификатором, затем идентификатор меняется на идентификатор родителя.
Выполнение этой процедуры для наших данных привело бы к следующему результату (запрос SELECT * FROM GETPARENTS 4):
Визуализация древовидной структуры
Для визуализации подобной структуры можно воспользоваться компонентом TTreeView, поставляемым в Delphi 2.0 и 3.0. Этот компонент формирует представление типа "outline" при помощи объектов TTreeNode. К сожалению, с этим типом объекта работать не очень удобно, поскольку он произведен от стандартного элемента GUI и при разработке нельзя использовать наследование. Для хранения дополнительных данных узла дерева приходится использовать поле TTreeNode.Data, представляющее собой указатель на произвольный объект или структуру данных.
Рис. 4
При отображении небольшого количества записей (до 1000) можно считывать в память всю таблицу и формировать TTreeView в памяти, не обращаясь затем к базе данных. Однако если нужно периодически перечитывать "дерево", то такой подход будет слишком медленным. Оптимальным было бы перечитывание только раскрываемой ветви дерева. При этом перечитывание будет происходить максимально быстро, т. к. даже самая сложная древовидная структура содержит максимум 200-500 элементов в одной ветви.
Для реализации перечитывания записей по "распахиванию" ветви дерева можно использовать приведенный выше запрос с выборкой элементов одной ветви.
После выполнения этой функции создаются элементы, дочерние для указанного Node, или корневые элементы, если Node=nil.
Однако в этом случае структура данных таблицы OBJECTS не дает нам возможности узнать (без дополнительного запроса) есть ли у элемента его "подэлементы". И TreeView для всех элементов не будет показывать признак “раскрываемости” или значок “+”.
Для этих целей без расширения нашей структуры данных не обойтись. Очевидно необходимо добавить в таблицу OBJECTS поле, которое будет содержать количество дочерних элементов (0 или больше). Такое поле можно добавить
Но кто будет модифицировать это поле, записывая туда новое количество дочерних элементов? Можно, конечно, делать это и из клиентского приложения. Однако самым правильным решением будет добавление триггеров на вставку, изменение и удаление записей в таблице OBJECTS.
Триггер по вставке записи должен увеличить количество "детей" у своего родителя:
(Обратите внимание, что во всех триггерах при обращении к таблице используетс псевдоним O, а для полей в триггере используется уточнитель new. или old. Это сделано для того, чтобы SQL-сервер не перепутал изменяемые поля в UPDATE и поля таблицы в контексте триггера).
Теперь таблица OBJECTS полностью автоматически отслеживает количество "детей" у каждого элемента.
(Для того чтобы правильно освобождать память, занимаемую операцией New(R), необходимо в методе TTreeView.OnDeletion написать одну строку – Dispose(PItemRec(Node.Data); Это освободит занятую память при удалении любого элемента TTreeNode или группы элементов).
Свойство HasChildren приведет к автоматической прорисовке значка "+" в TreeView у элемента, который имеет дочерние элементы. Таким образом мы получаем представление дерева без необходимости считывать все его элементы сразу.
Эта версия статьи устарела. Новая версия статьи перенесена по адресу: https://github.com/codedokode/pasta/blob/master/db/trees.md
Как хранить в БД древовидные структуры
Древовидные структуры – это такие структуры, где есть родители и дети, например, каталог товаров:
Типичные задачи, которые встречаются при работе с такими структурами:
- выбрать всех детей элемента
- выбрать всех потомков (детей и их детей) элемента
- выбрать цепочку предков элемента (родитель, его родитель, и так далее)
- переместить элемент (и его потомков) из одной группы в другую
- удалить элемент из таблицы (со всеми потомками)
У каждой записи есть идентификатор — уникальное число, он на схеме написан в скобках (думаю, это ты и так знаешь). Рассмотрим способы хранения таких данных.
1) Добавить колонку parent_id (метод Adjacency List)
Мы добавляем к каждой записи колонку parent_id (и индекс на нее), которая хранит id родительской записи (если родителя нет — NULL). Это самый простой, но самый неэффективный способ. Вот как будет выглядеть вышеприведенное дерево:
Выбрать всех детей просто: SELECT WHERE parent_ >, но другие операции требуют выполнения нескольких запросов и на больших деревьях особо неэффективны. Например, выбор всех потомков элемента с идентификатором :id
- выбрать список детей :id ( SELECT WHERE parent_ >)
- выбрать список их детей ( SELECT WHERE parent_id IN (:children1) )
- выбрать список детей детей ( SELECT WHERE parent_id IN (:children2) )
И так, пока мы не дойдем до самого младшего ребенка. После этого надо еще отсортировать и объединить результаты в дерево.
Плюсом, впрочем, является быстрая вставка и перемещение веток, которые не требуют никаких дополнительных запросов, и простота реализации. Если можно эффективно кешировать выборки, это в общем-то нормальный и работающий вариант (например, для меню сайта). Это может быть годный вариант для часто меняющихся данных.
Иногда еще добавляют поле depth , указывющее глубину вложенности, но его надо не забыть обновлять при перемещении ветки.
2) Closure table — усовершенствование предыдущего способа
В этом способы мы так же добавляет поле parent_id , но для оптимизации рекурсивных выборок создаем дополнительную таблицу, в которой храним всех потомков (детей и их детей) и их глубину относительно родителя каждой записи. Поясню. Дополнительная таблица выглядит так:
Чтобы узнать всех потомков записи, мы (в отличие от предыдущего способа), делаем запрос к дополнительной таблице: SELECT child_ >, получаем id потомков и выбираем их их основной таблицы: SELECT WHERE id IN (:children) . Если таблицы хранятся в одной БД, запросы можно объединить в один с использованием JOIN.
Данные потом надо будет вручную отсортировать в дерево.
Узнать список предков можно тоже одним запросом к таблице связей: SELECT parent_ >
Минусы метода: нужно поддерживать таблицу связей, она может быть огромной (размер посчитайте сами), при вставке новых записей и при перемещении веток нужны сложные манипуляции. Если таблица часто меняется, это не лучший способ.
Плюсы: относительная простота, быстрота выборок.
Идея в том, что мы добавляем к каждой записи поля parent_id , depth , left , right и выстраиваем записи хитрым образом. После этого выборка всех потомков (причем уже отсортированных в нужном порядке) делаетсяпростым запросом вида SELECT WHERE left >= :a AND right
Минусы: необходимость пересчитывать left / right при вставке записей в середину или удалении, сложное перемещение веток, сложность в понимании.
Плюсы: скорость выборки
В общем-то, годный вариант для больших таблиц, которые часто выбираются, но меняются нечасто (например, только через админку, где не критична производительность).
4) Materialized Path
Идея в том, что записи в пределах одной ветки нумеруются по порядку и в каждую запись добавляется поле path, содержащее полный список родителей. Напоминает способ нумерации глав в книгах. Пример:
При этом способе path хранится в поле вроде TEXT или BINARY, по нему делается индекс. Выбрать всех потомков можно запросом SELECT WHERE path LIKE ‘1.1.%’ ORDER BY path , который использует индекс.
Плюс: записи выбираются уже отсортированными в нужном порядке. Простота решения и скорость выборок высокая (1 запрос). Быстрая вставка.
Минусы: при вставке записи в середину надо пересчитывать номера и пути следующих за ней. При удалении ветки, возможно тоже. При перемещении ветки надо делать сложные расчеты. Глубина дерева и число детей у родителя ограничены выделенным дял них местом и длиной path
Этот способ отлично подходит для древовидных комментариев.
Теория: google it
5) Использовать БД с поддержкой иерархии
Я в этом не разбираюсь, может кто-то расскажет, какие есть возможности в БД для нативной поддержки деревьев. Вроде что-то такое есть в MSSQL и Oracle. Только хотелось бы услышать, как именно это оптимизируется и какой метод хранения используется, а не общие слова.